搜索到
362
篇与
的结果
-
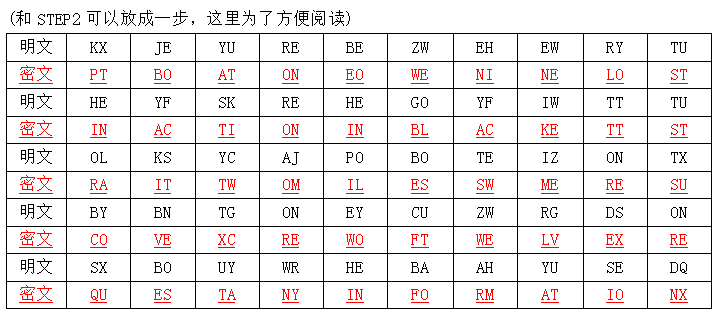
 密码学与网络安全第七版部分课后习题答案 第0章 序言1.课后题汇总(仅部分)第一章 思考题:1、2、4、5第二章 习题:10、12、16第三章 习题:9第四章 思考题:4、5、6第五章 习题:11第六章 习题:2、6第七章 思考题:2、3、4 习题:4、7、8第八章 习题:2第九章 思考题:5、6 习题:2、3第十章 习题:1、2第十一章 思考题:1、2、3第十二章 思考题:1、3、4、7第十三章 思考题:5第十四章 思考题:2、7、10、11第十五章 思考题:2、5第十七章 思考题:3、8、9第二十章 思考题:2、3、4、5、8第1章 计算机与网络安全的概念1.什么是OSI安全架构?(p6)OSI 安全框架是提供安全的一种组织方法,而且因为这个框架是作为国际标准而开发的, 所有计算机和通信商已经在他们的产品和服务上开发了这些安全特性,这些产品和服务与安 全服务是和安全机制的结构化定义相关联的。OSI安全框架主要关注安全攻击、机制和服务。安全攻击:任何危及信息系统安全的行为安全机制:用来检测、阻止攻击或从攻击状态恢复到正常状态的过程(或实现该过程的设备)。安全服务:加强数据处理系统和信息传输的安全性的一种处理过程或通信服务,目的在于利用一种或多种安全机制进行反攻击。2.被动安全威胁与主动安全威胁有何区别?(书上没找着,参考p6-p7的主动攻击和被动攻击)被动威胁的本质是窃听或监视数据传输,主动威胁包含数据流的改写和错误数据流的添加。3.列出并简要定义安全服务的种类。(p8)①认证:保证通信的实体是它所声明的实体②访问控制:阻止对资源的非授权使用(即这项服务控制谁能访问资源,在什么条件下可以访问,这些访问的资源可用于做什么)③数据保密性:保护数据免于非授权泄露④数据完整性:保证收到的数据的确是授权实体发出的数据(即未修改、插入、删除或重播)⑤不可否认性:防止整个或部分通信过程中,任一通信实体进行否认的行为。4.列出并简要定义安全机制的种类。(p10)①特定安全机制:可以并入适当的安全协议层提供一些OSI安全服务②普遍的安全机制:不局限与任何特定的OSI安全服务或协议层的机制第2章 数论基础1.求$Z_5$中各非0元素的乘法逆元。(p25)参考答案:STEP1:列出 $x \times y \ mod \ 5$ 并记录结果为1的情况x/y0123400000010$\color{red}{1}$2342024$\color{red}{1}$3303$\color{red}{1}$424043 $\color{red}{1}$STEP2:由此得到$Z_5$中的各非0元素的乘法逆元分别为涉及知识:①什么是$Z_5$?比n小的非负整数的集合为$Z_n,Z_n={0,1,…,(n-1)}$,这个集合称为类集,或者模n的剩余类。②什么是乘法逆元?简单来说就是这样:在$(mod \ p)$意义下($p$是素数),如果$a*a'=1$,那么我们就说$a'$是$a$的逆元。当然啦,反过来,$a$也是$a'$的逆元。也就是说,如果$(a*a')mod p=1$,那么我们就说$a'$是$a$的逆元。求法:列表就行Eg:求Z8中各元素的乘法逆元STEP1:模8乘法 $(x*y \ mod \ 8)$ STEP2:模8乘法的逆2.求gcd(24140,16762)和gcd(4655,12075)(p22-p23)gcd(24140,16762)被除数除数商余数241401676217378167627378220067378200631306200613061646130664626864668934683420因此$gcd(24140,16762)=34$gcd(4655,12075)被除数除数商余数120754655227654655276511890276518901875189087521408751406351403540因此$(4655,12075)=35$3.用扩展欧几里得算法求下列乘法逆元(p29)核心公式:$q_i=r_i-2/r_i-1$$r_i=r_i-2-r_i-1*q_i$$x_i=x_i-2-q_i*x_i-1$$y_i=y_i-2-q_i*y_i-1$解题模板参考下题(a)(a)1234mod4321(b)24140mod40902i$r_i$$q_i$$x_i$$y_i$-140902 10024140 0111676211-1273781-123200633-5413603-10175646113-226682-36617349337-571802 因为无余数($r_i$)为0,所以无乘法逆元。(c)550mod1769i$r_i$$q_i$$x_i$$y_i$-11769 100550 01111931-32744-41334515-164291-929516114-456131-237473137-1198$\color{red}{1}$4-171$\color{red}{550}$903 验证:$$ 550 \times 550 + (-171) \times 1769 = 1 $$所以550为550mod1769的乘法逆元。第3章 传统加密技术1. Playfair密码解密当海军上尉John F.Kennedy 管理的美国巡逻船PT-109被日本毁灭者击沉时,位于澳大利亚的一个无线站截获了一条用Playfair密码加密的消息:KXJEY UREBE ZWEHE WRYTU HEYFS KREHE GOYFI WTTTU OLKSY CAJPO BOTEI ZONTX BY_BWT GONEY CUZWR GDSON SXBOU YWRHE BAAHY USEDQ密钥为roy_al new Zealand navy.请解密这条消息,将TT换为tt.STEP1:构造密匙字母矩阵方法:构造5X5的字母矩阵,先将密匙中包含的字母挨个填入字母矩阵(不重复),入上图的下划线部分,再把剩下的继续按A-Z的顺序填入字母矩阵,I/J算同一个STEP2:分解字母对STEP3:解密方法:每个密文字母都取其对应的明文字母①若两个字母处于字母矩阵的同一行,则每个字母都取其左边的一个字母,最左边字母取最右边的。②若两个字母处于字母矩阵的同一列,则每个字母都取其上面的一个字母,最上边字母取最下边的。③若两个字母不同行业不同列,那就各反取对角,明文字母和密文字母在同一行STEP4:提取信息PT BOAT ONE OWE NINE LOST IN ACTION IN BLACKETT ATART TWO MILES SW MERESU COVE X CREW OF TWELVE X REQUEST ANY INFORMATION X第4章 分组密码和数据加密标准1.什么是乘积密码(p74)乘积密码是指依次使用两个或两个以上的基本密码,所得结果的密码强度将强与所有单个密码的强度.2.混淆和扩散的区别(p75)扩散(Diffusion):明文的统计结构被扩散消失到密文的,使得明文和密文之间的统计关系尽量复杂.即让每个明文数字尽可能地影响多个密文数字混淆(confusion):使得密文的统计特性与密钥的取值之间的关系尽量复杂,阻止攻击者发现密钥3.哪些参数与设计决定了实际的Feistel密码算法?(p75-p77)①分组长度:分组越长意味着安全性越高,但是会降低加/解密的速度。②密钥长度:密钥越长意味着安全性越高,但是会降低加/解密的速度。③迭代轮数:Feistel密码的本质在于单轮不能提供足够的安全性,而多轮加密可- 取的很高的安全性。④子密钥产生算法:子密钥产生越复杂,密码分析就越困难。⑤轮函数:轮函数越复杂,抗攻击能力就越强⑥快速软件加/解密:加密算法被嵌入到应用程序中,以避免硬件实现的麻烦,因此,算法执行的速度很重要。⑦简化分析难度:如果算法描述起来简洁清楚,那么分析其脆弱性也就容易一些,因而可以开发出更强的算法。第5章 有限域1.求x3+x+1在GF(24)里的乘法逆元,模m(x)=x4+x+1参考答案+解题模板:计算优化核心公式:$q_i(x)=r_{i-2}(x)/r_{i-1}(x)$$r_i(x)=r_{i-2}(x)-r_{i-1}(x)*q_i(x)$$v_i=v_i-2-q_i*v_i-1$$w_i=w_i-2-q_i*w_i-1$注意:$GF(2^n)$上所有的运算皆为模2运算第6章 高级加密标准1.在GF$(2^8)$上{01}的逆是什么?注意:$GF(2^8)$上的运算都是模2运算参考答案:注意:01为16进制使用拓展欧几里得算法28=256∴在GF(28)上{01}的逆是{01}拓展求$GF(2^8)$上{95}的逆(注意:95为16进制)使用拓展欧几里得算法$\color{red}{拓展题-典型错误解法}:$28=256 95H=149拓展题-正确解法--$GF(2^N)$上的运算都是模2运算特别注意--GF(28)的既约多项式为x8+x4+x3+x+1∴$GF(2^8)$上{95}的逆是{8A}2.验证{01}在S盒中的项(p115,p117)涉及知识①怎么验证看课表p117②S盒和逆S盒在p1153. 对如下所述的DES中的元素,指出AES中与之相对应的元素,或解释AES中为什么不需要该元素:①f函数的输入与子密钥相异或;轮密匙加②f函数的输出与分组最左的部分相异或;不需要,∵每轮都使用代替和混淆将整个数据细分为一个单一的矩阵处理③f函数字节代替、行移位、列混淆、轮密匙加④置换P;行移位⑤交换分组长度相等的两部分不需要,∵每轮都使用代替和混淆将整个数据细分为一个单一的矩阵处理第7章 分组加密的工作方式1.什么是中间相遇攻击?(p137)是密码学上以空间换取时间的一种攻击。中途相遇攻击(meet-in-the-middle attack)可成倍减少解密已被多个密钥加密的文本所进行的蛮力排列操作。这种攻击可以使入侵者更容易获取数据。2.在三重加密中一个用到了几个密匙(p138)2个3.为什么3DES的中间部分采用了解密而不是加密?(p138)第二步采用解密运算并没有什么密码学上的含义,这仅仅是为了使用三重DES的用户可以利用该算法解密单DES加密的数据。4. DES的ECB模式和CBC模式在DES的ECB模式中,若在密文的传输过程中,某一块发生错误则只有相应的明文分组会有影响。然而,在CBC模式中,这种错误具有扩散性。比如,图7.4中传输C1时发生的错误将会影响明文分组P1,P2a.P2以后的所有块是否会受到影响b.假设P1本来就有一位发生了错误。则这个错误要扩散至多少个密文分组?对接收者解密后的结果有什么影响参考答案a.不会受到影响b.会在加密过程中传递到每一个密文分组。对接收者解密后,P1与加密前一样有一位的错误,而对其他Ci能够解密得到无错误的密文。5. DES的CBC模式和CFB模式参考答案安全性,密文分组是否会泄露关于明文分组的信息等6. 在8位的cfb模式中,若传输中一个密文字符发生了一位错,这个错误将传播多远参考答案9个明文字符受到影响,因为除了与密文字符和对应的一个明文字符受影响外,受影响的该明文字符进入移位寄存器,直到接下来的8个字符处理完毕后才移出。第8章 伪随机数的产生和流密码1.伪随机数发生器a.下述的伪随机数发生器可获得的最大周期是多少?$X_n+1=(a*X_n) mod 24$参考答案:最大周期为4b.这时a为多少?参考答案:3、5、11、13c.对种子有什么要求?参考答案:种子必须为奇数,即$X_0$=1,3,5,7,9,11,13,15第9章 公钥密码学与RSA1.什么是单向函数?(p198-p199)课本上自己画2.什么是单向陷门函数?(p199)课本上自己画3.RSA秘钥生成及加密解密的计算涉及知识(打印版看不清可以看课本p201)题目-用RSA实现加密和解密:a.p=3;q=11;e=7;M=5密钥产生:①$n=p*q=3*11=33$②$φ(n)=(p-1)*(q-1)=2*10=20$③$d≡1modφ(n)即7d=1mod20$=>d=3所以,公钥PU={7,33},私钥PR={3,33}加密:$C=Me mod n=57 mod 33=14$---注意怎么算的解密:$M=Cd mod n=143 mod 33=5$---注意怎么算的4.在使用RSA的公钥体制中,已截获发给用户的密文C=10,该用户的公钥e=5,n=35,那么明文M是多少参考答案欧拉函数$φ(n)=24$$dmod24=1$可得$d=5$$M=Cd mod n=105 mod 35=5$---注意怎么算的第10章 密钥管理和其他公钥密码体制1.用户A和B在使用Diffie-Hellman密匙交换技术来交换密匙,设公钥的素数q=71,本原根α=7a.若用户A的私钥XA=5,则A个公钥$Y_A$为多少?参考答案:$Y_A=75mod71=51$b.若用户B的私钥XB=12,则B个公钥$Y_B$为多少?参考答案:$Y_B=712mod71=4$c.共享密钥为多少?参考答案:$K= (Y_A^XB)mod71=5112mod71=30$或者:$K= (Y_B^XA)mod71=45mod71=30$2.设Diffie-Hellman方法中,公钥素数q=11,本原根α=2。a.证明2是11的本原根参考答案:$2^1 mod 11=2$$2^2 mod 11=4$$2^3 mod 11=8$$2^4 mod 11=5$$2^5 mod 11=10$$2^6 mod 11=9$$2^7 mod 11=7$$2^8 mod 11=3$$2^9 mod 11=6$$2^{10} mod 11=1$∴2是11的本原根b.若用户A的公钥Y_A=9,则A个私钥XA为多少?参考答案:(2^XA) mod 11=9 ∴XA=6c.若用户B的公钥Y_B=3,则共享密钥K为多少?参考答案:K= (Y_B^XA)mod11=36 mod 11=3第11章 密码学Hash函数1.安全Hash函数需要具有哪些特征?(p240)①输入长度可变②输出长度固定③效率④抗原像攻击(单向性)⑤抗第二原像攻击(抗弱碰撞性)⑥抗碰撞攻击(抗强碰撞性)⑦伪随机性2.抗弱碰撞性和抗强碰撞之间的区别是什么?(p240)见课本3.Hash函数的压缩函数的作用是什么?压缩函数将一个较长的、固定长度的输入处理后返回一个较短的、固定长度的输出。第12章 消息认证码1.消息认证是为了对付哪些类型的攻击?(p264-p265)①伪装②内容修改③顺序修改④计时修改2.产生消息认证有哪些方法?(p265)①Hash函数②消息加密③消息认证码(MAC)3.对称加密和错误控制码一起用于消息认证时,这两个函数必须以何种顺序执行?先错误控制码,后对称加密4.为提供消息认证,应以何种方式保证Hash值的安全?a.用对称密码对消息及附加在其后的Hash码加密。b.用对称密码仅对Hash加密。c.用公钥密码和发送方的密钥仅对Hash加密。d.若寄希望保证保密性有希望有数字签名,则先用发送方的密钥对Hash码加密e.该方法使用Hash函数但不使用加密函数来进行消息认证。f.如果对整个消息和Hash码加密,则(e)中的方法可提供保密性。第13章 数字签名1.签名函数和保密函数应以何种顺序作用与消息?为什么?先执行签名函数,再执行加密函数。这样在发生争执时,第三方可以查看消息及其签名。这种先后次序非常重要,如果先对消息加密,然后再对消息的密文签名,那么第三方必须知道解密密钥才能读取原始消息。第14章 密钥管理和分发1.会话密钥和主密钥之间有什么不同?主密钥是被客户机和服务器用于产生会话密钥的一个密钥。这个主密钥被用于产生客户端读密钥,客户端写密钥,服务器读密钥,服务器写密钥。主密钥能够被作为一个简单密钥块输出。会话密钥是指:当两个端系统希望通信,他们建立一条逻辑连接。在逻辑连接持续过程中,所以用户数据都使用一个一次性的会话密钥加密。在会话和连接结束时,会话密钥被销。2.公钥目录的必要要素是什么?一是目录管理员的私钥安全,二是目录管理员保存的记录安全。3.X.509标准的用途是什么?(p319)X.509标准是一个广为接受的方案,用来规范公钥证书的格式。证书在大部分网络安全应用中都有使用,包括IP安全、传输层安全(TLS)和S/MIME。4.什么是证书链?数字证书由颁发该证书的签名。多个证书可以绑定到一个信息或交易上形成证书链,证书链中每一个证书都由其前面的数字证书进行鉴别。最高级的必须是受接受者信任的、独立的机构。第15章 用户认证1.列出三个常用的防止重放攻击的方法(p332)①对每一个用于认证交互的消息附上一个序列号。②时间戳:只有当消息中包含一个时间戳时,A才接收该消息。③挑战/应答:A想要一个来自B的新消息,首先发给B一个临时交互号,并要求后面从B收到的消息(回复)中包含正确的临时交互号。2.在网络或者Internet上,和用户认证相关联的三个威胁是什么?①用户可能通过某种途径进入工作站并假装成其他用户操作工作站。②用户可以通过变更工作站的网络地址,从该机上发送伪造的请求。③用户可以静听信息或使用重放攻击,以获得服务或破坏正常操作。第17章 传输层安全1.TLS连接和TLS会话的区别是什么?(p381)书上自己画2.HTTPS的目的是什么?在 http 的基础上结合 ssl 来实现网络浏览器和服务器的安全通信。3.哪些应用程序可以使用SSH?远程登录工具,文件传输工具等第20章 IP安全性1.IPSec提供哪些服务?①访问控制②连接完整性③数据源认证④拒绝重放包(部分顺序完整性格式)⑤保密性(加密)⑥限制流量保密性2.哪些参数标识SA,哪些参数刻画一个特定SA的本质?由安全参数索引、IP目的地址、安全协议标识三个参数确定一个SA。由“序列号计数器,序列计数器溢出,反重放窗口,AH信息,ESP信息,此安全关联的生存期,IPSec 协议模式,最大传输单元路径”等参数表示一个特定的SA。3.指出传输模式和隧道模式的区别传输模式是对IP数据包的载荷(上层协议)、IPV6报头的扩展部分进行保护和认证;隧道模式是对整个内部IP包、IPV6报头的扩展部分进行保护和认证。4.什么是重放攻击?重放攻击就是一个攻击者得到了一个经过认证的包的副本,稍后又将其传送到其希望被传送到的目的的站点的攻击。5.IPSec中的Oakley密钥确定协议和ISAKMP的作用是什么?IPSec的密钥管理部分包括密钥的确定和分发。分手动密钥管理和自动密钥管理两种类型。Oakley和ISAKMP就是IPSec的自动密钥管理协议。
密码学与网络安全第七版部分课后习题答案 第0章 序言1.课后题汇总(仅部分)第一章 思考题:1、2、4、5第二章 习题:10、12、16第三章 习题:9第四章 思考题:4、5、6第五章 习题:11第六章 习题:2、6第七章 思考题:2、3、4 习题:4、7、8第八章 习题:2第九章 思考题:5、6 习题:2、3第十章 习题:1、2第十一章 思考题:1、2、3第十二章 思考题:1、3、4、7第十三章 思考题:5第十四章 思考题:2、7、10、11第十五章 思考题:2、5第十七章 思考题:3、8、9第二十章 思考题:2、3、4、5、8第1章 计算机与网络安全的概念1.什么是OSI安全架构?(p6)OSI 安全框架是提供安全的一种组织方法,而且因为这个框架是作为国际标准而开发的, 所有计算机和通信商已经在他们的产品和服务上开发了这些安全特性,这些产品和服务与安 全服务是和安全机制的结构化定义相关联的。OSI安全框架主要关注安全攻击、机制和服务。安全攻击:任何危及信息系统安全的行为安全机制:用来检测、阻止攻击或从攻击状态恢复到正常状态的过程(或实现该过程的设备)。安全服务:加强数据处理系统和信息传输的安全性的一种处理过程或通信服务,目的在于利用一种或多种安全机制进行反攻击。2.被动安全威胁与主动安全威胁有何区别?(书上没找着,参考p6-p7的主动攻击和被动攻击)被动威胁的本质是窃听或监视数据传输,主动威胁包含数据流的改写和错误数据流的添加。3.列出并简要定义安全服务的种类。(p8)①认证:保证通信的实体是它所声明的实体②访问控制:阻止对资源的非授权使用(即这项服务控制谁能访问资源,在什么条件下可以访问,这些访问的资源可用于做什么)③数据保密性:保护数据免于非授权泄露④数据完整性:保证收到的数据的确是授权实体发出的数据(即未修改、插入、删除或重播)⑤不可否认性:防止整个或部分通信过程中,任一通信实体进行否认的行为。4.列出并简要定义安全机制的种类。(p10)①特定安全机制:可以并入适当的安全协议层提供一些OSI安全服务②普遍的安全机制:不局限与任何特定的OSI安全服务或协议层的机制第2章 数论基础1.求$Z_5$中各非0元素的乘法逆元。(p25)参考答案:STEP1:列出 $x \times y \ mod \ 5$ 并记录结果为1的情况x/y0123400000010$\color{red}{1}$2342024$\color{red}{1}$3303$\color{red}{1}$424043 $\color{red}{1}$STEP2:由此得到$Z_5$中的各非0元素的乘法逆元分别为涉及知识:①什么是$Z_5$?比n小的非负整数的集合为$Z_n,Z_n={0,1,…,(n-1)}$,这个集合称为类集,或者模n的剩余类。②什么是乘法逆元?简单来说就是这样:在$(mod \ p)$意义下($p$是素数),如果$a*a'=1$,那么我们就说$a'$是$a$的逆元。当然啦,反过来,$a$也是$a'$的逆元。也就是说,如果$(a*a')mod p=1$,那么我们就说$a'$是$a$的逆元。求法:列表就行Eg:求Z8中各元素的乘法逆元STEP1:模8乘法 $(x*y \ mod \ 8)$ STEP2:模8乘法的逆2.求gcd(24140,16762)和gcd(4655,12075)(p22-p23)gcd(24140,16762)被除数除数商余数241401676217378167627378220067378200631306200613061646130664626864668934683420因此$gcd(24140,16762)=34$gcd(4655,12075)被除数除数商余数120754655227654655276511890276518901875189087521408751406351403540因此$(4655,12075)=35$3.用扩展欧几里得算法求下列乘法逆元(p29)核心公式:$q_i=r_i-2/r_i-1$$r_i=r_i-2-r_i-1*q_i$$x_i=x_i-2-q_i*x_i-1$$y_i=y_i-2-q_i*y_i-1$解题模板参考下题(a)(a)1234mod4321(b)24140mod40902i$r_i$$q_i$$x_i$$y_i$-140902 10024140 0111676211-1273781-123200633-5413603-10175646113-226682-36617349337-571802 因为无余数($r_i$)为0,所以无乘法逆元。(c)550mod1769i$r_i$$q_i$$x_i$$y_i$-11769 100550 01111931-32744-41334515-164291-929516114-456131-237473137-1198$\color{red}{1}$4-171$\color{red}{550}$903 验证:$$ 550 \times 550 + (-171) \times 1769 = 1 $$所以550为550mod1769的乘法逆元。第3章 传统加密技术1. Playfair密码解密当海军上尉John F.Kennedy 管理的美国巡逻船PT-109被日本毁灭者击沉时,位于澳大利亚的一个无线站截获了一条用Playfair密码加密的消息:KXJEY UREBE ZWEHE WRYTU HEYFS KREHE GOYFI WTTTU OLKSY CAJPO BOTEI ZONTX BY_BWT GONEY CUZWR GDSON SXBOU YWRHE BAAHY USEDQ密钥为roy_al new Zealand navy.请解密这条消息,将TT换为tt.STEP1:构造密匙字母矩阵方法:构造5X5的字母矩阵,先将密匙中包含的字母挨个填入字母矩阵(不重复),入上图的下划线部分,再把剩下的继续按A-Z的顺序填入字母矩阵,I/J算同一个STEP2:分解字母对STEP3:解密方法:每个密文字母都取其对应的明文字母①若两个字母处于字母矩阵的同一行,则每个字母都取其左边的一个字母,最左边字母取最右边的。②若两个字母处于字母矩阵的同一列,则每个字母都取其上面的一个字母,最上边字母取最下边的。③若两个字母不同行业不同列,那就各反取对角,明文字母和密文字母在同一行STEP4:提取信息PT BOAT ONE OWE NINE LOST IN ACTION IN BLACKETT ATART TWO MILES SW MERESU COVE X CREW OF TWELVE X REQUEST ANY INFORMATION X第4章 分组密码和数据加密标准1.什么是乘积密码(p74)乘积密码是指依次使用两个或两个以上的基本密码,所得结果的密码强度将强与所有单个密码的强度.2.混淆和扩散的区别(p75)扩散(Diffusion):明文的统计结构被扩散消失到密文的,使得明文和密文之间的统计关系尽量复杂.即让每个明文数字尽可能地影响多个密文数字混淆(confusion):使得密文的统计特性与密钥的取值之间的关系尽量复杂,阻止攻击者发现密钥3.哪些参数与设计决定了实际的Feistel密码算法?(p75-p77)①分组长度:分组越长意味着安全性越高,但是会降低加/解密的速度。②密钥长度:密钥越长意味着安全性越高,但是会降低加/解密的速度。③迭代轮数:Feistel密码的本质在于单轮不能提供足够的安全性,而多轮加密可- 取的很高的安全性。④子密钥产生算法:子密钥产生越复杂,密码分析就越困难。⑤轮函数:轮函数越复杂,抗攻击能力就越强⑥快速软件加/解密:加密算法被嵌入到应用程序中,以避免硬件实现的麻烦,因此,算法执行的速度很重要。⑦简化分析难度:如果算法描述起来简洁清楚,那么分析其脆弱性也就容易一些,因而可以开发出更强的算法。第5章 有限域1.求x3+x+1在GF(24)里的乘法逆元,模m(x)=x4+x+1参考答案+解题模板:计算优化核心公式:$q_i(x)=r_{i-2}(x)/r_{i-1}(x)$$r_i(x)=r_{i-2}(x)-r_{i-1}(x)*q_i(x)$$v_i=v_i-2-q_i*v_i-1$$w_i=w_i-2-q_i*w_i-1$注意:$GF(2^n)$上所有的运算皆为模2运算第6章 高级加密标准1.在GF$(2^8)$上{01}的逆是什么?注意:$GF(2^8)$上的运算都是模2运算参考答案:注意:01为16进制使用拓展欧几里得算法28=256∴在GF(28)上{01}的逆是{01}拓展求$GF(2^8)$上{95}的逆(注意:95为16进制)使用拓展欧几里得算法$\color{red}{拓展题-典型错误解法}:$28=256 95H=149拓展题-正确解法--$GF(2^N)$上的运算都是模2运算特别注意--GF(28)的既约多项式为x8+x4+x3+x+1∴$GF(2^8)$上{95}的逆是{8A}2.验证{01}在S盒中的项(p115,p117)涉及知识①怎么验证看课表p117②S盒和逆S盒在p1153. 对如下所述的DES中的元素,指出AES中与之相对应的元素,或解释AES中为什么不需要该元素:①f函数的输入与子密钥相异或;轮密匙加②f函数的输出与分组最左的部分相异或;不需要,∵每轮都使用代替和混淆将整个数据细分为一个单一的矩阵处理③f函数字节代替、行移位、列混淆、轮密匙加④置换P;行移位⑤交换分组长度相等的两部分不需要,∵每轮都使用代替和混淆将整个数据细分为一个单一的矩阵处理第7章 分组加密的工作方式1.什么是中间相遇攻击?(p137)是密码学上以空间换取时间的一种攻击。中途相遇攻击(meet-in-the-middle attack)可成倍减少解密已被多个密钥加密的文本所进行的蛮力排列操作。这种攻击可以使入侵者更容易获取数据。2.在三重加密中一个用到了几个密匙(p138)2个3.为什么3DES的中间部分采用了解密而不是加密?(p138)第二步采用解密运算并没有什么密码学上的含义,这仅仅是为了使用三重DES的用户可以利用该算法解密单DES加密的数据。4. DES的ECB模式和CBC模式在DES的ECB模式中,若在密文的传输过程中,某一块发生错误则只有相应的明文分组会有影响。然而,在CBC模式中,这种错误具有扩散性。比如,图7.4中传输C1时发生的错误将会影响明文分组P1,P2a.P2以后的所有块是否会受到影响b.假设P1本来就有一位发生了错误。则这个错误要扩散至多少个密文分组?对接收者解密后的结果有什么影响参考答案a.不会受到影响b.会在加密过程中传递到每一个密文分组。对接收者解密后,P1与加密前一样有一位的错误,而对其他Ci能够解密得到无错误的密文。5. DES的CBC模式和CFB模式参考答案安全性,密文分组是否会泄露关于明文分组的信息等6. 在8位的cfb模式中,若传输中一个密文字符发生了一位错,这个错误将传播多远参考答案9个明文字符受到影响,因为除了与密文字符和对应的一个明文字符受影响外,受影响的该明文字符进入移位寄存器,直到接下来的8个字符处理完毕后才移出。第8章 伪随机数的产生和流密码1.伪随机数发生器a.下述的伪随机数发生器可获得的最大周期是多少?$X_n+1=(a*X_n) mod 24$参考答案:最大周期为4b.这时a为多少?参考答案:3、5、11、13c.对种子有什么要求?参考答案:种子必须为奇数,即$X_0$=1,3,5,7,9,11,13,15第9章 公钥密码学与RSA1.什么是单向函数?(p198-p199)课本上自己画2.什么是单向陷门函数?(p199)课本上自己画3.RSA秘钥生成及加密解密的计算涉及知识(打印版看不清可以看课本p201)题目-用RSA实现加密和解密:a.p=3;q=11;e=7;M=5密钥产生:①$n=p*q=3*11=33$②$φ(n)=(p-1)*(q-1)=2*10=20$③$d≡1modφ(n)即7d=1mod20$=>d=3所以,公钥PU={7,33},私钥PR={3,33}加密:$C=Me mod n=57 mod 33=14$---注意怎么算的解密:$M=Cd mod n=143 mod 33=5$---注意怎么算的4.在使用RSA的公钥体制中,已截获发给用户的密文C=10,该用户的公钥e=5,n=35,那么明文M是多少参考答案欧拉函数$φ(n)=24$$dmod24=1$可得$d=5$$M=Cd mod n=105 mod 35=5$---注意怎么算的第10章 密钥管理和其他公钥密码体制1.用户A和B在使用Diffie-Hellman密匙交换技术来交换密匙,设公钥的素数q=71,本原根α=7a.若用户A的私钥XA=5,则A个公钥$Y_A$为多少?参考答案:$Y_A=75mod71=51$b.若用户B的私钥XB=12,则B个公钥$Y_B$为多少?参考答案:$Y_B=712mod71=4$c.共享密钥为多少?参考答案:$K= (Y_A^XB)mod71=5112mod71=30$或者:$K= (Y_B^XA)mod71=45mod71=30$2.设Diffie-Hellman方法中,公钥素数q=11,本原根α=2。a.证明2是11的本原根参考答案:$2^1 mod 11=2$$2^2 mod 11=4$$2^3 mod 11=8$$2^4 mod 11=5$$2^5 mod 11=10$$2^6 mod 11=9$$2^7 mod 11=7$$2^8 mod 11=3$$2^9 mod 11=6$$2^{10} mod 11=1$∴2是11的本原根b.若用户A的公钥Y_A=9,则A个私钥XA为多少?参考答案:(2^XA) mod 11=9 ∴XA=6c.若用户B的公钥Y_B=3,则共享密钥K为多少?参考答案:K= (Y_B^XA)mod11=36 mod 11=3第11章 密码学Hash函数1.安全Hash函数需要具有哪些特征?(p240)①输入长度可变②输出长度固定③效率④抗原像攻击(单向性)⑤抗第二原像攻击(抗弱碰撞性)⑥抗碰撞攻击(抗强碰撞性)⑦伪随机性2.抗弱碰撞性和抗强碰撞之间的区别是什么?(p240)见课本3.Hash函数的压缩函数的作用是什么?压缩函数将一个较长的、固定长度的输入处理后返回一个较短的、固定长度的输出。第12章 消息认证码1.消息认证是为了对付哪些类型的攻击?(p264-p265)①伪装②内容修改③顺序修改④计时修改2.产生消息认证有哪些方法?(p265)①Hash函数②消息加密③消息认证码(MAC)3.对称加密和错误控制码一起用于消息认证时,这两个函数必须以何种顺序执行?先错误控制码,后对称加密4.为提供消息认证,应以何种方式保证Hash值的安全?a.用对称密码对消息及附加在其后的Hash码加密。b.用对称密码仅对Hash加密。c.用公钥密码和发送方的密钥仅对Hash加密。d.若寄希望保证保密性有希望有数字签名,则先用发送方的密钥对Hash码加密e.该方法使用Hash函数但不使用加密函数来进行消息认证。f.如果对整个消息和Hash码加密,则(e)中的方法可提供保密性。第13章 数字签名1.签名函数和保密函数应以何种顺序作用与消息?为什么?先执行签名函数,再执行加密函数。这样在发生争执时,第三方可以查看消息及其签名。这种先后次序非常重要,如果先对消息加密,然后再对消息的密文签名,那么第三方必须知道解密密钥才能读取原始消息。第14章 密钥管理和分发1.会话密钥和主密钥之间有什么不同?主密钥是被客户机和服务器用于产生会话密钥的一个密钥。这个主密钥被用于产生客户端读密钥,客户端写密钥,服务器读密钥,服务器写密钥。主密钥能够被作为一个简单密钥块输出。会话密钥是指:当两个端系统希望通信,他们建立一条逻辑连接。在逻辑连接持续过程中,所以用户数据都使用一个一次性的会话密钥加密。在会话和连接结束时,会话密钥被销。2.公钥目录的必要要素是什么?一是目录管理员的私钥安全,二是目录管理员保存的记录安全。3.X.509标准的用途是什么?(p319)X.509标准是一个广为接受的方案,用来规范公钥证书的格式。证书在大部分网络安全应用中都有使用,包括IP安全、传输层安全(TLS)和S/MIME。4.什么是证书链?数字证书由颁发该证书的签名。多个证书可以绑定到一个信息或交易上形成证书链,证书链中每一个证书都由其前面的数字证书进行鉴别。最高级的必须是受接受者信任的、独立的机构。第15章 用户认证1.列出三个常用的防止重放攻击的方法(p332)①对每一个用于认证交互的消息附上一个序列号。②时间戳:只有当消息中包含一个时间戳时,A才接收该消息。③挑战/应答:A想要一个来自B的新消息,首先发给B一个临时交互号,并要求后面从B收到的消息(回复)中包含正确的临时交互号。2.在网络或者Internet上,和用户认证相关联的三个威胁是什么?①用户可能通过某种途径进入工作站并假装成其他用户操作工作站。②用户可以通过变更工作站的网络地址,从该机上发送伪造的请求。③用户可以静听信息或使用重放攻击,以获得服务或破坏正常操作。第17章 传输层安全1.TLS连接和TLS会话的区别是什么?(p381)书上自己画2.HTTPS的目的是什么?在 http 的基础上结合 ssl 来实现网络浏览器和服务器的安全通信。3.哪些应用程序可以使用SSH?远程登录工具,文件传输工具等第20章 IP安全性1.IPSec提供哪些服务?①访问控制②连接完整性③数据源认证④拒绝重放包(部分顺序完整性格式)⑤保密性(加密)⑥限制流量保密性2.哪些参数标识SA,哪些参数刻画一个特定SA的本质?由安全参数索引、IP目的地址、安全协议标识三个参数确定一个SA。由“序列号计数器,序列计数器溢出,反重放窗口,AH信息,ESP信息,此安全关联的生存期,IPSec 协议模式,最大传输单元路径”等参数表示一个特定的SA。3.指出传输模式和隧道模式的区别传输模式是对IP数据包的载荷(上层协议)、IPV6报头的扩展部分进行保护和认证;隧道模式是对整个内部IP包、IPV6报头的扩展部分进行保护和认证。4.什么是重放攻击?重放攻击就是一个攻击者得到了一个经过认证的包的副本,稍后又将其传送到其希望被传送到的目的的站点的攻击。5.IPSec中的Oakley密钥确定协议和ISAKMP的作用是什么?IPSec的密钥管理部分包括密钥的确定和分发。分手动密钥管理和自动密钥管理两种类型。Oakley和ISAKMP就是IPSec的自动密钥管理协议。 -
CommentToMail:给博客添加评论邮箱提醒功能 1.下载安装首先下载插件再上传到/usr/plugins目录解压,博客后台启用并配置插件。下载地址:CommentToMail2.配置邮箱smtp地址:smtp.qq.com(我用的QQ邮箱)SMTP端口:465SMTP用户:自己的邮箱账户SMTP密码:开启smtp时获取的授权码(QQ在设置-账户里面,其他百度)STMP验证:服务器需要验证、ssl加密全打勾3.美化代码3.1步骤一依次打开:博客后台 -> 控制台 -> 评论邮件提醒 -> 编辑邮件模板3.2步骤二将以下代码复制粘贴到guest.html<table style="width: 99.8%;height:99.8% "><tbody><tr><td style="background:#fafafa url('data:image/png;base64,iVBORw0KGgoAAAANSUhEUgAAAAgAAAAICAYAAADED76LAAAAy0lEQVQY0x2PsQtAYBDFP1keKZfBKIqNycCERUkMKLuSgZnRarIpJX8s3zfcDe9+794du+8bRVHQOI4wDAOmaULTNDDGYFkWMVVVQUTQdZ3iOMZxHCjLElVV0TRNYHVdC7ptW6RpSn3f4wdJkiTs+w6WJAl4DcOAbdugKAq974umaRAEARgXn+cRW3zfFxuiKCJZloXGHMeBbdv4Beq6Duu6Issy7iYB8Jbnucg8zxPLsggnj/zvIxaGIXmeB9d1wSE+nOeZf4HruvABUtou5ypjMF4AAAAASUVORK5CYII=')"> <div style="border-radius: 10px 10px 10px 10px;font-size:13px; color: #555555;width: 666px;font-family:'Century Gothic','Trebuchet MS','Hiragino Sans GB',微软雅黑,'Microsoft Yahei',Tahoma,Helvetica,Arial,'SimSun',sans-serif;margin:50px auto;border:1px solid #eee;max-width:100%;background: #ffffff repeating-linear-gradient(-45deg,#fff,#fff 1.125rem,transparent 1.125rem,transparent 2.25rem);box-shadow: 0 1px 5px rgba(0, 0, 0, 0.15);"> <div style="width:100%;background:#49BDAD;color:#ffffff;border-radius: 10px 10px 0 0;background-image: -moz-linear-gradient(0deg, rgb(67, 198, 184), rgb(255, 209, 244));background-image: -webkit-linear-gradient(0deg, rgb(67, 198, 184), rgb(255, 209, 244));height: 66px;"> <p style="font-size:15px;word-break:break-all;padding: 23px 32px;margin:0;background-color: hsla(0,0%,100%,.4);border-radius: 10px 10px 0 0;">您在<a style="text-decoration:none;color: #ffffff;" href="https:"> {siteTitle} </a>上的留言有新回复啦! </p> </div> <div style="margin:40px auto;width:90%"> <p>{author_p} 您曾在文章《{title}》上发表评论:</p> <p style="background: #fafafa repeating-linear-gradient(-45deg,#fff,#fff 1.125rem,transparent 1.125rem,transparent 2.25rem);box-shadow: 0 2px 5px rgba(0, 0, 0, 0.15);margin:20px 0px;padding:15px;border-radius:5px;font-size:14px;color:#555555;">{text_p}</p> <p>{author} 给您的回复如下:</p> <p style="background: #fafafa repeating-linear-gradient(-45deg,#fff,#fff 1.125rem,transparent 1.125rem,transparent 2.25rem);box-shadow: 0 2px 5px rgba(0, 0, 0, 0.15);margin:20px 0px;padding:15px;border-radius:5px;font-size:14px;color:#555555;">{text}</p> <p>您可以点击 <a style="text-decoration:none; color:#12addb" href="{permalink}">查看回复的完整內容 </a>,欢迎再次光临 <a style="text-decoration:none; color:#12addb" href="https:"> {siteTitle} </a>。</p> <style type="text/css">a:link{text-decoration:none}a:visited{text-decoration:none}a:hover{text-decoration:none}a:active{text-decoration:none}</style> </div> </div> </td></tr></tbody></table>3.3步骤三接着将以下代码复制粘贴到owner.html<style> .wrap span { display: inline-block; } .w260{ width: 260px;} .w20{ width: 20px;} .wauto{ width: auto;} </style> <table style="width: 99.8%;height:99.8% "><tbody><tr><td style="background:#fafafa url('data:image/png;base64,iVBORw0KGgoAAAANSUhEUgAAAAgAAAAICAYAAADED76LAAAAy0lEQVQY0x2PsQtAYBDFP1keKZfBKIqNycCERUkMKLuSgZnRarIpJX8s3zfcDe9+794du+8bRVHQOI4wDAOmaULTNDDGYFkWMVVVQUTQdZ3iOMZxHCjLElVV0TRNYHVdC7ptW6RpSn3f4wdJkiTs+w6WJAl4DcOAbdugKAq974umaRAEARgXn+cRW3zfFxuiKCJZloXGHMeBbdv4Beq6Duu6Issy7iYB8Jbnucg8zxPLsggnj/zvIxaGIXmeB9d1wSE+nOeZf4HruvABUtou5ypjMF4AAAAASUVORK5CYII=')"> <div style="border-radius: 10px 10px 10px 10px;font-size:13px; color: #555555;width: 666px;font-family:'Century Gothic','Trebuchet MS','Hiragino Sans GB',微软雅黑,'Microsoft Yahei',Tahoma,Helvetica,Arial,'SimSun',sans-serif;margin:50px auto;border:1px solid #eee;max-width:100%;background: #ffffff repeating-linear-gradient(-45deg,#fff,#fff 1.125rem,transparent 1.125rem,transparent 2.25rem);box-shadow: 0 1px 5px rgba(0, 0, 0, 0.15);"> <div style="width:100%;background:#49BDAD;color:#ffffff;border-radius: 10px 10px 0 0;background-image: -moz-linear-gradient(0deg, rgb(67, 198, 184), rgb(255, 209, 244));background-image: -webkit-linear-gradient(0deg, rgb(67, 198, 184), rgb(255, 209, 244));height: 66px;"> <p style="font-size:15px;word-break:break-all;padding: 23px 32px;margin:0;background-color: hsla(0,0%,100%,.4);border-radius: 10px 10px 0 0;">您的<a style="text-decoration:none;color: #ffffff;" href="https:"> {siteTitle} </a>上有新的评论啦! </p> </div> <div style="margin:40px auto;width:90%"> <p>{author} 在您文章《{title}》上发表评论:</p> <p style="background: #fafafa repeating-linear-gradient(-45deg,#fff,#fff 1.125rem,transparent 1.125rem,transparent 2.25rem);box-shadow: 0 2px 5px rgba(0, 0, 0, 0.15);margin:20px 0px;padding:15px;border-radius:5px;font-size:14px;color:#555555;">{text}</p> <p class="wrap" style="text-decoration:none"><span class="w260">时间:{time}</span><span class="w20"> </span><span class="wauto"> IP:{ip}</span></p> <p class="wrap" style="text-decoration:none"><span class="w260">邮箱:{mail}</span><span class="w20"> </span><span class="wauto">状态:{status}</span></p> <p><a style="text-decoration:none; color:#12addb" href="{permalink}" target='_blank'>[查看评论]</a> | <a style="text-decoration:none; color:#12addb" href="{manage}" target='_blank'>[管理评论] </a></p> <style type="text/css">a:link{text-decoration:none}a:visited{text-decoration:none}a:hover{text-decoration:none}a:active{text-decoration:none}</style> </div> </div> </td></tr></tbody></table>注意:要把里面的链接改为自己的哦3.4美化效果被评论:被回复:
-
cmake使用及如何编写CMakeLists.txt文件 1.cmake 简介CMake是一个跨平台的安装(编译)工具,可以用简单的语句来描述所有平台的安装(编译过程)。他能够输出各种各样的makefile或者project文件,能测试编译器所支持的C++特性,类似UNIX下的automake。2.CMake 操作流程CMake的所有的语句都写在一个叫:CMakeLists.txt的文件中。当CMakeLists.txt文件确定后,可以用ccmake命令对相关 的变量值进行配置。这个命令必须指向CMakeLists.txt所在的目录。配置完成之后,应用cmake命令生成相应的makefile(在Unix like系统下)或者 project文件(指定用window下的相应编程工具编译时)。其基本操作流程为:$ ccmake directory $ cmake directory $ make其中directory为CMakeList.txt所在目录;第一条语句用于配置编译选项,如VTK_DIR目录 ,一般这一步不需要配置,直接执行第二条语句即可,但当出现错误时,这里就需要认为配置了,这一步才真正派上用场;第二条命令用于根据CMakeLists.txt生成Makefile文件;第三条命令用于执行Makefile文件,编译程序,生成可执行文件;CMake的执行就是这么简单,其难点在于如何编写CMakeLists.txt文件3.如何编写CMakeLists.txt文件3.1 开头通用模块make版本要求cmake_minimum_required( VERSION 2.8 )工程文件名-可任取project(project)编译模式# 设置为 Release 模式 SET(CMAKE_BUILD_TYPE Release) # 设置为 debug 模式 SET(CMAKE_BUILD_TYPE debug) # 打印设置的编译模型信息 MESSAGE("Build type: " ${CMAKE_BUILD_TYPE})检查C++版本# Check C++11 or C++0x support include(CheckCXXCompilerFlag) CHECK_CXX_COMPILER_FLAG("-std=c++11" COMPILER_SUPPORTS_CXX11) CHECK_CXX_COMPILER_FLAG("-std=c++0x" COMPILER_SUPPORTS_CXX0X) if(COMPILER_SUPPORTS_CXX11) set(CMAKE_CXX_FLAGS "${CMAKE_CXX_FLAGS} -std=c++11") add_definitions(-DCOMPILEDWITHC11) message(STATUS "Using flag -std=c++11.") elseif(COMPILER_SUPPORTS_CXX0X) set(CMAKE_CXX_FLAGS "${CMAKE_CXX_FLAGS} -std=c++0x") add_definitions(-DCOMPILEDWITHC0X) message(STATUS "Using flag -std=c++0x.") else() message(FATAL_ERROR "The compiler ${CMAKE_CXX_COMPILER} has no C++11 support. Please use a different C++ compiler.") endif()3.2 项目文件配置模块如果仅包含OpenCV库时备注:这里的OpenCV包含目录为含有OpenCVConfig.cmake的路径。set(OpenCV_DIR "/usr/local/include/opencv3.2.0/share/OpenCV") find_package(OpenCV REQUIRED) include_directories( ${OpenCV_INCLUDE_DIRS} )生成可执行文件ADD_EXECUTABLE( 目标文件(可执行文件) 依赖文件(.cpp))add_executable(${PROJECT_NAME} src/loop_closure.cpp ) target_link_libraries(${PROJECT_NAME} ${OpenCV_LIBS})包含第三库的头文件#设置.h文件对应的路径 set( DBoW2_INCLUDE_DIRS ${PROJECT_SOURCE_DIR}/ThirdParty/DBow-master/include/) #包含.h文件路径 include_directories( ${OpenCV_INCLUDE_DIRS} ${DBoW2_INCLUDE_DIRS} ${DBoW2_INCLUDE_DIRS}/DBoW2/) 包含第三方库的cpp文件set(DBoW2_SRCS "${PROJECT_SOURCE_DIR}/ThirdParty/DBow-master/src") #生成可执行文件 -- 使用空格分割cpp文件路径 add_executable(${PROJECT_NAME} src/loop_closure.cpp src/run_main.cpp ${DBoW2_SRCS}/BowVector.cpp ${DBoW2_SRCS}/FBrief.cpp ${DBoW2_SRCS}/FeatureVector.cpp ${DBoW2_SRCS}/FORB.cpp ${DBoW2_SRCS}/FSurf64.cpp ${DBoW2_SRCS}/QueryResults.cpp ${DBoW2_SRCS}/ScoringObject.cpp)3.3 一个简单的CMakeLists.txt文件democmake_minimum_required( VERSION 2.8 ) project( loop_closure ) #set(CMAKE_BUILD_TYPE Debug) IF(NOT CMAKE_BUILD_TYPE) SET(CMAKE_BUILD_TYPE Release) ENDIF() MESSAGE("Build type: " ${CMAKE_BUILD_TYPE}) # Check C++11 or C++0x support include(CheckCXXCompilerFlag) CHECK_CXX_COMPILER_FLAG("-std=c++11" COMPILER_SUPPORTS_CXX11) CHECK_CXX_COMPILER_FLAG("-std=c++0x" COMPILER_SUPPORTS_CXX0X) if(COMPILER_SUPPORTS_CXX11) set(CMAKE_CXX_FLAGS "${CMAKE_CXX_FLAGS} -std=c++11") add_definitions(-DCOMPILEDWITHC11) message(STATUS "Using flag -std=c++11.") elseif(COMPILER_SUPPORTS_CXX0X) set(CMAKE_CXX_FLAGS "${CMAKE_CXX_FLAGS} -std=c++0x") add_definitions(-DCOMPILEDWITHC0X) message(STATUS "Using flag -std=c++0x.") else() message(FATAL_ERROR "The compiler ${CMAKE_CXX_COMPILER} has no C++11 support. Please use a different C++ compiler.") endif() #opencv #set(OpenCV_DIR "/usr/local/include/opencv3.2.0/share/OpenCV") set(OpenCV_DIR "/opt/ros/kinetic/share/OpenCV-3.3.1-dev") find_package(OpenCV REQUIRED) set( DBoW3_INCLUDE_DIRS "/usr/local/include") set( DBoW2_INCLUDE_DIRS ${PROJECT_SOURCE_DIR}/ThirdParty/DBow-master/include/) message(${DBoW2_INCLUDE_DIRS}) #important #file(GLOB DBoW2_SRCS ${PROJECT_SOURCE_DIR}/ThirdParty/DBow-master/src/*.cpp) #message(${DBoW2_SRCS}) set(DBoW2_SRCS "${PROJECT_SOURCE_DIR}/ThirdParty/DBow-master/src") message(${DBoW2_SRCS}) find_package(DLib QUIET PATHS ${DEPENDENCY_INSTALL_DIR}) if(${DLib_FOUND}) message("DLib library fo NDENCY_DIR} GIT_REPOSITORY http://github.com/dorian3d/DLib GIT_TAG master INSTALL_DIR ${DEPENDENCY_INSTALL_DIR} CMAKE_ARGS -DCMAKE_INSTALL_PREFIX=<INSTALL_DIR>) add_custom_target(Dependencies ${CMAKE_COMMAND} ${CMAKE_SOURCE_DIR} DEPENDS DLib) else() message(SEND_ERROR "Please, activate DOWNLOAD_DLib_dependency option or download manually") endif(${DOWNLOAD_DLib_dependency}) endif(${DLib_FOUND}) include_directories( ${OpenCV_INCLUDE_DIRS} ${DBoW3_INCLUDE_DIRS} ${DBoW2_INCLUDE_DIRS} ${DBoW2_INCLUDE_DIRS}/DBoW2/) message("DBoW3_INCLUDE_DIRS ${DBoW3_INCLUDE_DIRS}") message("DBoW2_INCLUDE_DIRS ${DBoW2_INCLUDE_DIRS}") message("opencv ${OpenCV_VERSION}") # dbow3 # dbow3 is a simple lib so I assume you installed it in default directory set( DBoW3_LIBS "/usr/local/lib/libDBoW3.a") add_executable(${PROJECT_NAME} src/loop_closure.cpp src/run_main.cpp ${DBoW2_SRCS}/BowVector.cpp ${DBoW2_SRCS}/FBrief.cpp ${DBoW2_SRCS}/FeatureVector.cpp ${DBoW2_SRCS}/FORB.cpp ${DBoW2_SRCS}/FSurf64.cpp ${DBoW2_SRCS}/QueryResults.cpp ${DBoW2_SRCS}/ScoringObject.cpp ) message(${DBoW2_SRCS}/BowVector.cpp) target_link_libraries(${PROJECT_NAME} ${OpenCV_LIBS} ${DLib_LIBS} ${DBoW3_LIBS} )参考资料cmake使用方法详解快速了解如何编写CMakeLists.txt文件?
-
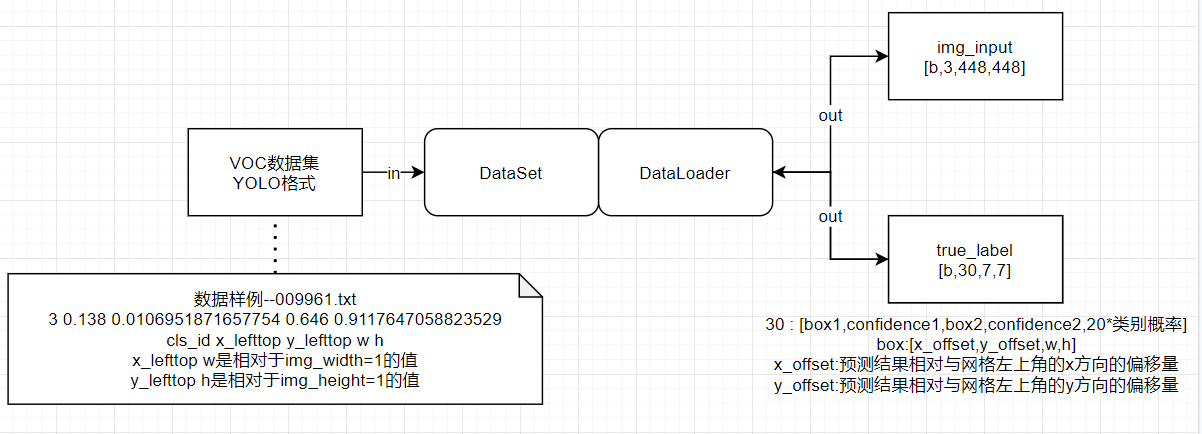
YOLOv1论文复现 一.整理结构概览1.数据格式转换部分2.DataSet,DateLoader部分2.1 主模块2.2 DataSet辅助模块--boxs2yololabel将单个图片中yolo格式的所有box转为yolov1网络模型所需要的label3.YOLOv1网络部分4.YOLOv1损失函数部分二.对每部分逐一进行实现1.数据格式转换部分--VOC2YOLO.py模块封装import xmltodict import os from progressbar import * """ 将单个xml文件中的单个object转换为yolov1格式 """ def get_yolo_data(obj,img_width,img_height): # 获取voc格式的数据信息 name = obj['name'] xmin = float(obj['bndbox']['xmin']) xmax = float(obj['bndbox']['xmax']) ymin = float(obj['bndbox']['ymin']) ymax = float(obj['bndbox']['ymax']) # 计算对应的yolo格式的数据信息,并进行归一化处理 class_idx = class_names.index(name) x_lefttop = xmin / img_width y_lefttop = ymin / img_height box_width = (xmax - xmin) / img_width box_height = (ymax - ymin) / img_height # 组转YOLO格式的数据 yolo_data = "{} {} {} {} {}\n".format(class_idx,x_lefttop,y_lefttop,box_width,box_height) return yolo_data """ 逐一处理xml文件,转换为YOLO所需的格式 + input + voc_xml_dir:VOC数据集的所有xml文件存储的文件夹 + yolo_txt_dir:转化完成后的YOLOv1格式数据的存储文件夹 + class_names:涉及的所有的类别 + output + yolo_txt_dir文件夹下的文件中的对应每张图片的YOLO格式的数据 """ def VOC2YOLOv1(voc_xml_dir,yolo_txt_dir,class_names): #进度条支持 count = 0 #计数器 widgets = ['VOC2YOLO: ',Percentage(), ' ', Bar('#'),' ', Timer(),' ', ETA()] pbar = ProgressBar(widgets=widgets, maxval=len(os.listdir(xml_dir))).start() # 对xml文件进行逐一处理 for xml_file in os.listdir(xml_dir): # 路径组装 xml_file_path = os.path.join(xml_dir,xml_file) txt_file_path = os.path.join(txt_dir,xml_file[:-4]+".txt") yolo_data = "" # 读取xml文件 with open(xml_file_path) as f: xml_str = f.read() # 转为字典 xml_dic = xmltodict.parse(xml_str) # 获取图片的width、height img_width = float(xml_dic["annotation"]["size"]["width"]) img_height = float(xml_dic["annotation"]["size"]["height"]) # 获取xml文件中的所有object objects = xml_dic["annotation"]["object"] # 对所有的object进行逐一处理 if isinstance(objects,list): # xml文件中包含多个object for obj in objects: yolo_data += get_yolo_data(obj,img_width,img_height) else: # xml文件中包含1个object obj = objects yolo_data += get_yolo_data(obj,img_width,img_height) # 将图片对应的yolo格式的数据写入到对应的文件 with open(txt_file_path,'w') as f: f.write(yolo_data) #更新进度 count += 1 pbar.update(count) pbar.finish() # 释放进度条调用测试voc_xml_dir='../VOC2007/Annotations/' #原xml路径 yolo_txt_dir='../VOC2007/labels/' #转换后txt文件存放路径 # 所有待检测的labels class_names = ['aeroplane', 'cat', 'car', 'dog', 'chair', 'person', 'horse', 'bird', 'tvmonitor', 'bus', 'boat', 'diningtable', 'bicycle', 'bottle', 'sofa', 'pottedplant', 'motorbike', 'cow', 'train', 'sheep'] VOC2YOLOv1(voc_xml_dir,yolo_txt_dir,class_names)VOC2YOLO: 100% |##########################| Elapsed Time: 0:01:18 Time: 0:01:182.DataSet,DateLoader部分模块封装from torch.utils.data import Dataset,DataLoader from PIL import Image """ 构建YOLOv1的dataset,用于加载VOC数据集(已对其进行了YOLO格式转换) + input + mode:调用模式,train/val + DATASET_PATH:VOC数据集的根目录,已对其进行了YOLO格式转换 + yolo_input_size:训练和测试所用的图片大小,通常为448 """ class Dataset_VOC(Dataset): def __init__(self,mode = "train",DATASET_PATH = "../VOC2007/",yolo_input_size = 448): self.filenames = [] # 储存数据集的文件名称 # 获取数据集的文件夹列表 if mode == "train": with open(DATASET_PATH + "ImageSets/Main/train.txt", 'r') as f: # 调用包含训练集图像名称的txt文件 self.filenames = [x.strip() for x in f] elif mode =='val': with open(DATASET_PATH + "ImageSets/Main/val.txt", 'r') as f: # 调用包含训练集图像名称的txt文件 self.filenames = [x.strip() for x in f] # 图像文件所在的文件夹 self.img_dir = os.path.join(DATASET_PATH,"JPEGImages") # 图像对应的label文件(.txt文件)的文件夹 self.label_dir = os.path.join(DATASET_PATH,"labels") def boxs2yololabel(self,boxs): """ 将boxs数据转换为训练时方便计算Loss的数据形式(7,7,5*B+cls_num) 单个box数据格式:(cls,x_rela_width,y_rela_height,w_rela_width,h_rela_height) x_rela_width:相对width=1的x的取值 """ gridsize = 1.0/7 # 网格大小 # 初始化result,此处需要根据不同数据集的类别个数进行修改 label = np.zeros((7,7,30)) # 根据box的数据填充label for i in range(len(boxs)//5): # 计算当前box会位于哪个网格 gridx = int(boxs[i*5+1] // gridsize) # 当前bbox中心落在第gridx个网格,列 gridy = int(boxs[i*5+2] // gridsize) # 当前bbox中心落在第gridy个网格,行 # 计算box相对于网格的左上角的点的相对位置 # box中心坐标 - 网格左上角点的坐标)/网格大小 ==> box中心点的相对位置 x_offset = boxs[i*5+1] / gridsize - gridx y_offset = boxs[i*5+2] / gridsize - gridy # 将第gridy行,gridx列的网格设置为负责当前ground truth的预测,置信度和对应类别概率均置为1 label[gridy, gridx, 0:5] = np.array([x_offset, y_offset, boxs[i*5+3], boxs[i*5+4], 1]) label[gridy, gridx, 5:10] = np.array([x_offset, y_offset, boxs[i*5+3], boxs[i*5+4], 1]) label[gridy, gridx, 10+int(boxs[i*5])] = 1 return label def __len__(self): return len(self.filenames) def __getitem__(self, index): # 构建image部分 # 读取图片 img_path = os.path.join(self.img_dir,self.filenames[index]+".jpg") img = cv2.imread(img_path) # 计算padding值将图像padding为正方形 h,w = img.shape[0:2] padw,padh = 0,0 if h>w: padw = (h - w) // 2 img = np.pad(img,((0,0),(padw,padw),(0,0)),'constant',constant_values=0) elif w>h: padh = (w - h) // 2 img = np.pad(img,((padh,padh),(0,0),(0,0)), 'constant', constant_values=0) # 然后resize为yolo网络所需要的尺寸448x448 yolo_input_size = 448 # 输入YOLOv1网络的图像尺寸为448x448 img = cv2.resize(img,(yolo_input_size,yolo_input_size)) # 构建label部分 # 读取图像对应的box信息,按1维的方式储存,每5个元素表示一个bbox的(cls_id,x_lefttop,y_lefttop,w,h) label_path = os.path.join(self.label_dir,self.filenames[index]+".txt") with open(label_path) as f: boxs = f.read().split('\n') boxs = [x.split() for x in boxs] boxs = [float(x) for y in boxs for x in y] # 根据padding、图像增广等操作,将原始的box数据转换为修改后图像的box数据 for i in range(len(boxs)//5): if padw != 0: boxs[i*5+1] = (boxs[i*5+1] * w + padw) / h boxs[i*5+3] = (boxs[i*5+3] * w) / h elif padh != 0: boxs[i*5+2] = (boxs[i*5+2] * h + padh) / w boxs[i*5+4] = (boxs[i*5+4] * h) / w # boxs转为yololabel label = self.boxs2yololabel(boxs) # img,label转为tensor img = transforms.ToTensor()(img) label = transforms.ToTensor()(label) return img,label调用测试train_dataset = Dataset_VOC(mode="train") val_dataset = Dataset_VOC(mode="val") train_dataloader = DataLoader(train_dataset,batch_size=2,shuffle=True) val_dataloader = DataLoader(val_dataset,batch_size=2,shuffle=True) for i,(inputs,labels) in enumerate(train_dataloader): print(inputs.shape,labels.shape) break for i,(inputs,labels) in enumerate(val_dataloader): print(inputs.shape,labels.shape) breaktorch.Size([2, 3, 448, 448]) torch.Size([2, 30, 7, 7]) torch.Size([2, 3, 448, 448]) torch.Size([2, 30, 7, 7])3.YOLOv1网络部分网络结构模块封装import torch import torch.nn as nn class YOLOv1(nn.Module): def __init__(self): super(YOLOv1,self).__init__() self.feature = nn.Sequential( nn.Conv2d(in_channels=3,out_channels=64,kernel_size=7,stride=2,padding=3), nn.LeakyReLU(), nn.MaxPool2d(kernel_size=2,stride=2), nn.Conv2d(in_channels=64,out_channels=192,kernel_size=3,stride=1,padding=1), nn.LeakyReLU(), nn.MaxPool2d(kernel_size=2,stride=2), nn.Conv2d(in_channels=192,out_channels=128,kernel_size=1,stride=1,padding=0), nn.LeakyReLU(), nn.Conv2d(in_channels=128,out_channels=256,kernel_size=3,stride=1,padding=1), nn.LeakyReLU(), nn.Conv2d(in_channels=256,out_channels=256,kernel_size=1,stride=1,padding=0), nn.LeakyReLU(), nn.Conv2d(in_channels=256,out_channels=512,kernel_size=3,stride=1,padding=1), nn.LeakyReLU(), nn.MaxPool2d(kernel_size=2,stride=2), nn.Conv2d(in_channels=512,out_channels=256,kernel_size=1,stride=1,padding=0), nn.LeakyReLU(), nn.Conv2d(in_channels=256,out_channels=512,kernel_size=3,stride=1,padding=1), nn.LeakyReLU(), nn.Conv2d(in_channels=512,out_channels=256,kernel_size=1,stride=1,padding=0), nn.LeakyReLU(), nn.Conv2d(in_channels=256,out_channels=512,kernel_size=3,stride=1,padding=1), nn.LeakyReLU(), nn.Conv2d(in_channels=512,out_channels=256,kernel_size=1,stride=1,padding=0), nn.LeakyReLU(), nn.Conv2d(in_channels=256,out_channels=512,kernel_size=3,stride=1,padding=1), nn.LeakyReLU(), nn.Conv2d(in_channels=512,out_channels=256,kernel_size=1,stride=1,padding=0), nn.LeakyReLU(), nn.Conv2d(in_channels=256,out_channels=512,kernel_size=3,stride=1,padding=1), nn.Conv2d(in_channels=512,out_channels=512,kernel_size=1,stride=1,padding=0), nn.LeakyReLU(), nn.Conv2d(in_channels=512,out_channels=1024,kernel_size=3,stride=1,padding=1), nn.LeakyReLU(), nn.MaxPool2d(kernel_size=2,stride=2), nn.Conv2d(in_channels=1024,out_channels=512,kernel_size=1,stride=1,padding=0), nn.LeakyReLU(), nn.Conv2d(in_channels=512,out_channels=1024,kernel_size=3,stride=1,padding=1), nn.LeakyReLU(), nn.Conv2d(in_channels=1024,out_channels=512,kernel_size=1,stride=1,padding=0), nn.LeakyReLU(), nn.Conv2d(in_channels=512,out_channels=1024,kernel_size=3,stride=1,padding=1), nn.LeakyReLU(), nn.Conv2d(in_channels=1024,out_channels=1024,kernel_size=3,stride=1,padding=1), nn.LeakyReLU(), nn.Conv2d(in_channels=1024,out_channels=1024,kernel_size=3,stride=2,padding=1), nn.LeakyReLU(), nn.Conv2d(in_channels=1024,out_channels=1024,kernel_size=3,stride=1,padding=1), nn.LeakyReLU(), nn.Conv2d(in_channels=1024,out_channels=1024,kernel_size=3,stride=1,padding=1), nn.LeakyReLU(), ) self.classify = nn.Sequential( nn.Flatten(), nn.Linear(1024 * 7 * 7, 4096), nn.Dropout(0.5), nn.Linear(4096, 1470) #1470=7*7*30 ) def forward(self,x): x = self.feature(x) x = self.classify(x) return x调用测试yolov1 = YOLOv1() fake_input = torch.zeros((1,3,448,448)) print(fake_input.shape) output = yolov1(fake_input) print(output.shape)yolov1 = YOLOv1() fake_input = torch.zeros((1,3,448,448)) print(fake_input.shape) output = yolov1(fake_input) print(output.shape)4.YOLOv1损失函数部分损失函数详解模块封装""" + input + pred: (batch_size,30,7,7)的网络输出数据 + labels: (batch_size,30,7,7)的样本标签数据 + output + 当前批次样本的平均损失 """ """ + YOLOv1 的损失分为3部分 + 坐标预测损失 + 置信度预测损失 + 含object的box的confidence预测损失 + 不含object的box的confidence预测损失 + 类别预测损失 """ class YOLOv1_Loss(nn.Module): def __init__(self): super(YOLOv1_Loss,self).__init__() def convert_box_type(self,src_box): """ box格式转换 + input + src_box : [box_x_lefttop,box_y_lefttop,box_w,box_h] + output + dst_box : [box_x1,box_y1,box_x2,box_y2] """ x,y,w,h = tuple(src_box) x1,y1 = x,y x2,y2 = x+w,y+w return [x1,y1,x2,y2] def cal_iou(self,box1,box2): """ iou计算 """ # 求相交区域左上角的坐标和右下角的坐标 box_intersect_x1 = max(box1[0], box2[0]) box_intersect_y1 = max(box1[1], box2[1]) box_intersect_x2 = min(box1[2], box2[2]) box_intersect_y2 = min(box1[3], box2[3]) # 求二者相交的面积 area_intersect = (box_intersect_y2 - box_intersect_y1) * (box_intersect_x2 - box_intersect_x1) # 求box1,box2的面积 area_box1 = (box1[2] - box1[0]) * (box1[3] - box1[1]) area_box2 = (box2[2] - box2[0]) * (box2[3] - box2[1]) # 求二者相并的面积 area_union = area_box1 + area_box2 - area_intersect # 计算iou(交并比) iou = area_intersect / area_union return iou def forward(self,pred,target): batch_size = pred.shape[0] lambda_noobj = 0.5 # lambda_noobj参数 lambda_coord = 5 # lambda_coord参数 site_pred_loss = 0 # 坐标预测损失 obj_confidence_pred_loss = 0 # 含object的box的confidence预测损失 noobj_confidence_pred_loss = 0 #不含object的box的confidence预测损失 class_pred_loss = 0 # 类别预测损失 for batch_size_index in range(batch_size): # batchsize循环 for x_index in range(7): # x方向网格循环 for y_index in range(7): # y方向网格循环 # 获取单个网格的预测数据和真实数据 pred_data = pred[batch_size_index,:,x_index,y_index] # [x,y,w,h,confidence,x,y,w,h,confidence,cls*20] true_data = target[batch_size_index,:,x_index,y_index] #[x,y,w,h,confidence,x,y,w,h,confidence,cls*20] if true_data[4]==1:# 如果包含物体 # 解析预测数据和真实数据 pred_box_confidence_1 = pred_data[0:5] # [x,y,w,h,confidence1] pred_box_confidence_2 = pred_data[5:10] # [x,y,w,h,confidence2] true_box_confidence = true_data[0:5] # [x,y,w,h,confidence] # 获取两个预测box并计算与真实box的iou iou1 = self.cal_iou(self.convert_box_type(pred_box_confidence_1[0:4]),self.convert_box_type(true_box_confidence[0:4])) iou2 = self.cal_iou(self.convert_box_type(pred_box_confidence_2[0:4]),self.convert_box_type(true_box_confidence[0:4])) # 在两个box中选择iou大的box负责预测物体 if iou1 >= iou2: better_box_confidence,bad_box_confidence = pred_box_confidence_1,pred_box_confidence_2 better_iou,bad_iou = iou1,iou2 else: better_box_confidence,bad_box_confidence = pred_box_confidence_2,pred_box_confidence_1 better_iou,bad_iou = iou2,iou1 # 计算坐标预测损失 site_pred_loss += lambda_coord * torch.sum((better_box_confidence[0:2]- true_box_confidence[0:2])**2) # x,y的预测损失 site_pred_loss += lambda_coord * torch.sum((better_box_confidence[2:4].sqrt()-true_box_confidence[2:4].sqrt())**2) # w,h的预测损失 # 计算含object的box的confidence预测损失 obj_confidence_pred_loss += (better_box_confidence[4] - better_iou)**2 # iou比较小的bbox不负责预测物体,因此confidence loss算在noobj中 # 因此还需计算不含object的box的confidence预测损失 noobj_confidence_pred_loss += lambda_noobj * (bad_box_confidence[4] - bad_iou)**2 # 计算类别损失 class_pred_loss += torch.sum((pred_data[10:] - true_data[10:])**2) else: # 如果不包含物体,则只有置信度损失--noobj_confidence_pred_loss # [4,9]代表取两个预测框的confidence noobj_confidence_pred_loss += lambda_noobj * torch.sum(pred[batch_size_index,(4,9),x_index,y_index]**2) loss = site_pred_loss + obj_confidence_pred_loss + noobj_confidence_pred_loss + class_pred_loss return loss/batch_size调用测试loss = YOLOv1_Loss() label1 = torch.zeros([1,30,7,7]) label2 = torch.zeros([1,30,7,7]) print(label1.shape,label2.shape) print(loss(label1,label2)) loss = YOLOv1_Loss() label1 = torch.randn([8,30,7,7]) label2 = torch.randn([8,30,7,7]) print(label1.shape,label2.shape) print(loss(label1,label2))torch.Size([1, 30, 7, 7]) torch.Size([1, 30, 7, 7]) tensor(0.) torch.Size([8, 30, 7, 7]) torch.Size([8, 30, 7, 7]) tensor(46.7713)三.整体封装测试#TODO参考资料【YOLOv1论文翻译】:YOLO: 一体化的,实时的物体检测YOLOv1学习:(一)网络结构推导与实现YOLOv1学习:(二)损失函数理解和实现
-
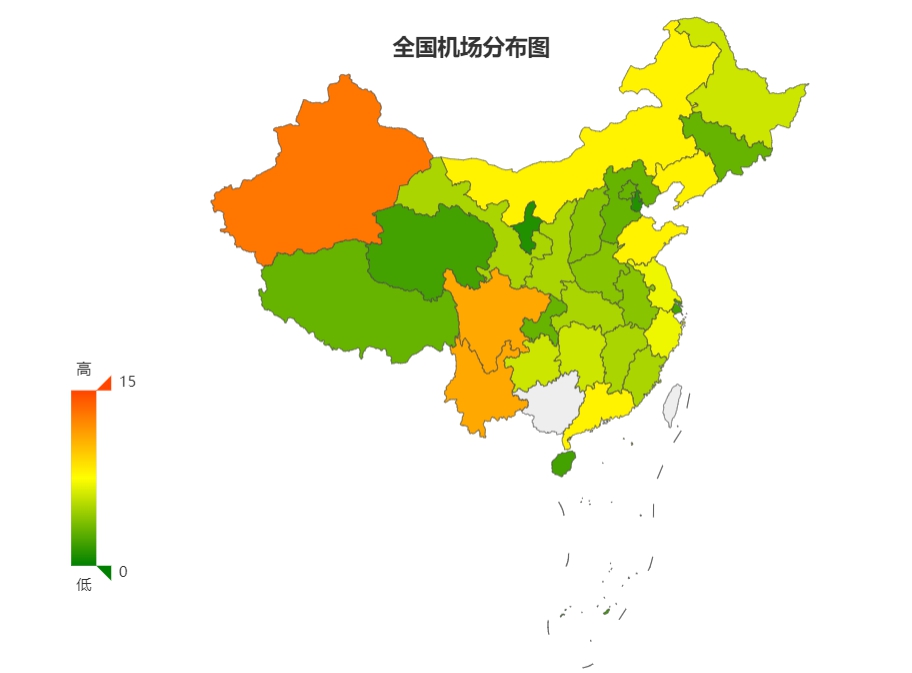
国内机场信息统计:按省份分布进行统计 1.数据获取1.1 相关数据来源https://wenku.baidu.com/view/04382a04cc175527072208cd.htmlhttp://www.6qt.net/index.asp1.2 数据格式[ { "province": "province_name", "airport_list": [ {"name": "首都国际机场","IATA": "PEK","ICAO": "ZBAA"}, ···, {"name": "北京大兴国际机场","IATA": "PKX","ICAO": "ZBAD"} ] }, ··· ]1.3 IATA2ICAO(三字码转四字码)函数封装from bs4 import BeautifulSoup from urllib.request import urlopen def IATA2ICAO(IATA): url = "http://www.6qt.net/index.asp?Field=AreaCode&keyword=" + IATA html = urlopen(url).read().decode('gbk') soup = BeautifulSoup(html, features='html.parser') data_raw = soup.select("body>table tr.tdbg>td")[4] return data_raw.a.u.text1.4 数据处理结果-airports.json[ { "province": "北京市", "airport_list": [ { "name": "首都国际机场", "IATA": "PEK", "ICAO": "ZBAA" }, { "name": "北京南苑机场", "IATA": "NAY", "ICAO": "ZBNY" }, { "name": "北京大兴国际机场", "IATA": "PKX", "ICAO": "ZBAD" } ] }, { "province": "上海市", "airport_list": [ { "name": "上海浦东国际机场", "IATA": "PVG", "ICAO": "ZSPD" }, { "name": "上海虹桥国际机场", "IATA": "SHA", "ICAO": "ZSSS" } ] }, { "province": "天津市", "airport_list": [ { "name": "天滨海国机场", "IATA": "TSN", "ICAO": "ZBTJ" } ] }, { "province": "重庆市", "airport_list": [ { "name": "重庆江北国际机场", "IATA": "CKG", "ICAO": "ZUCK" }, { "name": "重庆万州五桥机场", "IATA": "WXN", "ICAO": "ZUWX" }, { "name": "万县梁平机场", "IATA": "LIA", "ICAO": "ZULP" } ] }, { "province": "广东省", "airport_list": [ { "name": "广州白云国际机场", "IATA": "CAN", "ICAO": "ZGGG" }, { "name": "深圳宝安国际机场", "IATA": "SZX", "ICAO": "ZGSZ" }, { "name": "珠海三灶机场", "IATA": "ZUH", "ICAO": "ZGSD" }, { "name": "梅州梅县机场", "IATA": "MXZ", "ICAO": "ZGMX" }, { "name": "汕头外砂机场", "IATA": "SWA", "ICAO": "ZGOW" }, { "name": "惠州惠东机场", "IATA": "HUZ", "ICAO": "ZGHZ" }, { "name": "佛山沙堤机场", "IATA": "ZCP", "ICAO": "ZGFS" }, { "name": "兴宁机场", "IATA": "XIN", "ICAO": "ZGXN" } ] }, { "province": "湖南省", "airport_list": [ { "name": "长沙黄花国际机场", "IATA": "CSX", "ICAO": "ZGHA" }, { "name": "张家界荷花机场", "IATA": "DYG", "ICAO": "ZGDY" }, { "name": "常德桃花源机场", "IATA": "CGD", "ICAO": "ZGCD" }, { "name": "坏化正江机场", "IATA": "HJJ", "ICAO": "ZGCJ" }, { "name": "永州零陵机场", "IATA": "LLF", "ICAO": "ZGLG" }, { "name": "衡阳机场", "IATA": "HNY", "ICAO": "ZGHY" } ] }, { "province": "湖北省", "airport_list": [ { "name": "武汉天河国际机场", "IATA": "WUH", "ICAO": "ZHHH" }, { "name": "宜昌三峡机场", "IATA": "YIH", "ICAO": "ZHYC" }, { "name": "襄樊刘集机场", "IATA": "XFN", "ICAO": "ZHXF" }, { "name": "恩施许家坪机场", "IATA": "ENH", "ICAO": "ZHES" }, { "name": "沙市机场", "IATA": "SHS", "ICAO": "ZHSS" } ] }, { "province": "江西省", "airport_list": [ { "name": "南昌昌北机场", "IATA": "KHN", "ICAO": "ZSCN" }, { "name": "赣州黄金机场", "IATA": "KOW", "ICAO": "ZSGZ" }, { "name": "九江马回岭机场", "IATA": "JIU", "ICAO": "ZSJJ" }, { "name": "景德镇罗家机场", "IATA": "JDZ", "ICAO": "ZSJD" }, { "name": "井冈山机场", "IATA": "JGS", "ICAO": "ZSGS" } ] }, { "province": "福建省", "airport_list": [ { "name": "厦门高崎国际机场", "IATA": "XMN", "ICAO": "ZSAM" }, { "name": "福州长乐国际机场", "IATA": "FOC", "ICAO": "ZSFZ" }, { "name": "晋江泉州机场", "IATA": "JJN", "ICAO": "ZSQZ" }, { "name": "武夷山机场", "IATA": "WUS", "ICAO": "ZSWY" }, { "name": "连城机场", "IATA": "LCX", "ICAO": "ZSLO" } ] }, { "province": "浙江省", "airport_list": [ { "name": "杭州萧山国际机场", "IATA": "HGH", "ICAO": "ZSHC" }, { "name": "宁波标社机场", "IATA": "NGB", "ICAO": "ZSNB" }, { "name": "温州永强机场", "IATA": "WNZ", "ICAO": "ZSWZ" }, { "name": "义乌机场", "IATA": "YIW", "ICAO": "ZSYW" }, { "name": "舟山普陀山机场", "IATA": "HSN", "ICAO": "ZSZS" }, { "name": "台州黄岩路桥机场", "IATA": "HYN", "ICAO": "ZSLQ" }, { "name": "衢州机场", "IATA": "JUZ", "ICAO": "ZSJU" } ] }, { "province": "江苏省", "airport_list": [ { "name": "南京禄口机场", "IATA": "NKG", "ICAO": "ZSNJ" }, { "name": "无锡机场", "IATA": "WUX", "ICAO": "ZSWX" }, { "name": "常州奔牛机场", "IATA": "CZX", "ICAO": "ZSCG" }, { "name": "连云港白塔埠机场", "IATA": "LYG", "ICAO": "ZSLG" }, { "name": "盐城南洋机场", "IATA": "YNZ", "ICAO": "ZSYN" }, { "name": "徐州观音机场", "IATA": "XUZ", "ICAO": "ZSXZ" }, { "name": "南通兴东机场", "IATA": "NTG", "ICAO": "ZSNT" } ] }, { "province": "山东省", "airport_list": [ { "name": "济南遥墙国际机场", "IATA": "TNA", "ICAO": "ZSJN" }, { "name": "青岛流亭国际机场", "IATA": "TAO", "ICAO": "ZSQD" }, { "name": "烟台莱山国际机场", "IATA": "YNT", "ICAO": "ZSYT" }, { "name": "潍坊机场", "IATA": "WEF", "ICAO": "ZSWF" }, { "name": "威海机场", "IATA": "WEH", "ICAO": "ZSWH" }, { "name": "临沂机场", "IATA": "LYI", "ICAO": "ZSLY" }, { "name": "东营机场", "IATA": "DOY", "ICAO": "ZSDY" }, { "name": "济宁机场", "IATA": "JNG", "ICAO": "ZSJG" } ] }, { "province": "河南省", "airport_list": [ { "name": "郑州新郑机场", "IATA": "CGO", "ICAO": "ZHCC" }, { "name": "南阳姜营机场", "IATA": "NNY", "ICAO": "ZHNY" }, { "name": "洛阳北郊机场", "IATA": "LYA", "ICAO": "ZHLY" }, { "name": "安阳机场", "IATA": "AYN", "ICAO": "ZHAY" } ] }, { "province": "四川省", "airport_list": [ { "name": "成都双流国际机场", "IATA": "CTU", "ICAO": "ZUUU" }, { "name": "攀枝花机场", "IATA": "PZI", "ICAO": "ZUZH" }, { "name": "绵阳南郊机场", "IATA": "MIG", "ICAO": "ZUMY" }, { "name": "南充高坪机场", "IATA": "NAO", "ICAO": "ZUNC" }, { "name": "达县河市机场", "IATA": "DAX", "ICAO": "ZUDX" }, { "name": "宜宾菜坝机场", "IATA": "YBP", "ICAO": "ZUYB" }, { "name": "泸州兰田坝机场", "IATA": "LZO", "ICAO": "ZULZ" }, { "name": "九寨黄龙机场", "IATA": "JZH", "ICAO": "ZUJZ" }, { "name": "西昌青山机场", "IATA": "XIC", "ICAO": "ZUXC" }, { "name": "广元机场", "IATA": "GYS", "ICAO": "ZUGU" }, { "name": "广汉机场", "IATA": "GHN", "ICAO": "ZUGH" } ] }, { "province": "海南省", "airport_list": [ { "name": "三亚凤凰国际机场", "IATA": "SYX", "ICAO": "ZJSY" }, { "name": "美际机场", "IATA": "HAK", "ICAO": "ZJHK" } ] }, { "province": "云南省", "airport_list": [ { "name": "昆明巫家坝国际机场", "IATA": "KMG", "ICAO": "ZPPP" }, { "name": "丽江机场", "IATA": "LJG", "ICAO": "ZPLJ" }, { "name": "大理机场", "IATA": "DLU", "ICAO": "ZPDL" }, { "name": "景洪西双版纳机场", "IATA": "JHG", "ICAO": "ZPJH" }, { "name": "中甸迪庆香格里拉机场", "IATA": "DIG", "ICAO": "ZPDQ" }, { "name": "德宏潞西芒市机场", "IATA": "LUM", "ICAO": "ZPMS" }, { "name": "思茅机场", "IATA": "SYM", "ICAO": "ZPSM" }, { "name": "保山机场", "IATA": "BSD", "ICAO": "ZPBS" }, { "name": "临沧机场", "IATA": "LNJ", "ICAO": "ZPLC" }, { "name": "昭通机场", "IATA": "ZAT", "ICAO": "ZPZT" }, { "name": "元谋机场", "IATA": "YUA", "ICAO": "ZPYM" } ] }, { "province": "贵州省", "airport_list": [ { "name": "遵义新舟机场", "IATA": "ZYI", "ICAO": "ZUZY" }, { "name": "贵阳龙家堡机场", "IATA": "KWE", "ICAO": "ZUGY" }, { "name": "安顺黄果树机场", "IATA": "AVA", "ICAO": "ZUAS" }, { "name": "铜云机场", "IATA": "TEN", "ICAO": "ZUTR" }, { "name": "兴义机场", "IATA": "ACX", "ICAO": "ZUYI" }, { "name": "黎平机场", "IATA": "HZH", "ICAO": "ZUNP" } ] }, { "province": "甘肃省", "airport_list": [ { "name": "兰州中川机场", "IATA": "LHW", "ICAO": "ZLLL" }, { "name": "敦煌机场", "IATA": "DNH", "ICAO": "ZLDH" }, { "name": "嘉裕关机场", "IATA": "JGN", "ICAO": "ZLJQ" }, { "name": "庆阳西峰镇机场", "IATA": "IQN", "ICAO": "ZLQY" }, { "name": "酒泉机场", "IATA": "CHW", "ICAO": "NNNN" } ] }, { "province": "安徽省", "airport_list": [ { "name": "合肥路岗机场", "IATA": "HFE", "ICAO": "ZSOF" }, { "name": "黄山屯溪机场", "IATA": "TXN", "ICAO": "ZSTX" }, { "name": "安庆天柱山机场", "IATA": "AQG", "ICAO": "ZSAQ" }, { "name": "阜阳西关机场", "IATA": "FUG", "ICAO": "ZSFY" } ] }, { "province": "陕西省", "airport_list": [ { "name": "西安咸阳国际机场", "IATA": "XIY", "ICAO": "ZLXY" }, { "name": "延安机场", "IATA": "ENY", "ICAO": "ZLYA" }, { "name": "榆林西沙机场", "IATA": "UYN", "ICAO": "ZLYL" }, { "name": "安康五里铺机场", "IATA": "AKA", "ICAO": "ZLAK" }, { "name": "汉中西关机场", "IATA": "HZG", "ICAO": "ZLHZ" } ] }, { "province": "山西省", "airport_list": [ { "name": "太原武宿机场", "IATA": "TYN", "ICAO": "ZBYN" }, { "name": "长治王村机场", "IATA": "CIH", "ICAO": "ZBCZ" }, { "name": "运城关公机场", "IATA": "YCU", "ICAO": "ZBYC" }, { "name": "大同机场", "IATA": "DAT", "ICAO": "ZBDT" } ] }, { "province": "河北省", "airport_list": [ { "name": "石家庄正定机场", "IATA": "SJW", "ICAO": "ZBSJ" }, { "name": "秦皇岛机场", "IATA": "SHP", "ICAO": "ZBSH" }, { "name": "山海关机场", "IATA": "SHP", "ICAO": "ZBSH" } ] }, { "province": "辽宁省", "airport_list": [ { "name": "沈阳桃仙机场", "IATA": "SHE", "ICAO": "ZYTX" }, { "name": "大连周水子机场", "IATA": "DLC", "ICAO": "ZYTL" }, { "name": "丹东浪头机场", "IATA": "DDG", "ICAO": "ZYDD" }, { "name": "鞍山腾鳌机场", "IATA": "AOG", "ICAO": "ZYAS" }, { "name": "锦州小岭子机场", "IATA": "NZ", "ICAO": "ZSWZ" }, { "name": "朝阳机场", "IATA": "CHG", "ICAO": "ZYCY" }, { "name": "长海市大长山岛机场", "IATA": "CNI", "ICAO": "ZYCH" }, { "name": "兴城机场", "IATA": "XEN", "ICAO": "ZYXC" } ] }, { "province": "吉林省", "airport_list": [ { "name": "长春龙嘉国际机场", "IATA": "CGQ", "ICAO": "ZYCC" }, { "name": "吉林二台子机场", "IATA": "JIL", "ICAO": "ZYJL" }, { "name": "延吉朝阳川机场", "IATA": "YN", "ICAO": "ZSYT" } ] }, { "province": "黑龙江省", "airport_list": [ { "name": "哈尔滨阎家岗国际机场", "IATA": "HRB", "ICAO": "ZYHB" }, { "name": "齐齐哈尔三家子机场", "IATA": "NDG", "ICAO": "ZYQQ" }, { "name": "牡丹江海浪机场", "IATA": "MDG", "ICAO": "ZYMD" }, { "name": "依兰机场", "IATA": "YLN", "ICAO": "ZYYL" }, { "name": "黑河机场", "IATA": "HEK", "ICAO": "ZYHE" }, { "name": "佳木斯东郊机场", "IATA": "MU", "ICAO": "EDDM" } ] }, { "province": "内蒙古自治区", "airport_list": [ { "name": "呼和浩特白塔机场", "IATA": "HET", "ICAO": "ZBHH" }, { "name": "锡林浩特机场", "IATA": "XIL", "ICAO": "ZBXH" }, { "name": "乌兰洁特机场", "IATA": "HLH", "ICAO": "ZBUL" }, { "name": "包头海兰泡机场", "IATA": "BAV", "ICAO": "ZBOW" }, { "name": "乌海机场", "IATA": "WUA", "ICAO": "ZBUH" }, { "name": "海拉尔东山机场", "IATA": "HLD", "ICAO": "ZBLA" }, { "name": "赤峰土城市机场", "IATA": "CIF", "ICAO": "ZBCF" }, { "name": "通辽机场", "IATA": "TGO", "ICAO": "ZBTL" } ] }, { "province": "青海省", "airport_list": [ { "name": "西宁曹家堡机场", "IATA": "XNN", "ICAO": "ZLXN" }, { "name": "格尔木机场", "IATA": "GOQ", "ICAO": "ZLGM" } ] }, { "province": "宁夏回族自治区", "airport_list": [ { "name": "银川河东机场", "IATA": "INC", "ICAO": "ZLIC" } ] }, { "province": "西藏自治区", "airport_list": [ { "name": "拉萨贡嘎机场", "IATA": "LXA", "ICAO": "ZULS" }, { "name": "林芝米林机场", "IATA": "LZY", "ICAO": "ZUNZ" }, { "name": "昌都马草机场", "IATA": "BPX", "ICAO": "ZUBD" } ] }, { "province": "新疆维吾尔自治区", "airport_list": [ { "name": "乌鲁木齐地窝堡机场", "IATA": "URC", "ICAO": "ZWWW" }, { "name": "喀什机场", "IATA": "KHG", "ICAO": "ZWSH" }, { "name": "伊宁机场", "IATA": "YIN", "ICAO": "ZWYN" }, { "name": "库尔勒机场", "IATA": "KRL", "ICAO": "ZWKL" }, { "name": "阿克苏机场", "IATA": "AKU", "ICAO": "ZWAK" }, { "name": "和田机场", "IATA": "HTN", "ICAO": "ZWTN" }, { "name": "阿勒泰机场", "IATA": "AAT", "ICAO": "ZWAT" }, { "name": "且末机场", "IATA": "IQM", "ICAO": "ZWCM" }, { "name": "库车机场", "IATA": "KCA", "ICAO": "ZWKC" }, { "name": "塔城机场", "IATA": "TCG", "ICAO": "ZWTC" }, { "name": "富蕴可可托海机场", "IATA": "FYN", "ICAO": "ZWFY" }, { "name": "克拉马依机场", "IATA": "KRY", "ICAO": "ZWKM" }, { "name": "哈密机场", "IATA": "HMI", "ICAO": "ZWHM" } ] } ]2.数据分析与可视化-绘制全国机场分布情况2.1 获取目标地图的json文件首先要获取目标地图的json文件,去阿里云就可以获取:阿里云地理2.2 使用echarts渲染数据<!DOCTYPE html> <html> <head> <meta charset="utf-8"> <title>ECharts</title> <!-- 引入 echarts.js --> <script src="echarts.min.js"></script> <script src="jquery.min.js"></script> </head> <body> <!-- 为ECharts准备一个具备大小(宽高)的Dom --> <div id="main" style="width: 1000px;height:650px;"></div> <script type="text/javascript"> $.get('https://geo.datav.aliyun.com/areas_v3/bound/100000_full.json', function(cZjson) { echarts.registerMap('中华人民共和国', cZjson); var chart = echarts.init(document.getElementById('main')); option = { title: { text: '全国机场分布图', x: 'center' }, dataRange: { min: 0, max: 15, text: ['高', '低'], realtime: true, calculable: true, color: ['orangered', 'yellow', 'green'] }, series: [{ name: '机场数量', type: 'map', map: '中华人民共和国', mapLocation: { y: 60 }, itemSytle: { emphasis: { label: { show: false } } }, data: [ {name: '北京市',value: 3}, {name: '上海市',value: 2}, {name: '天津市',value: 1}, {name: '重庆市',value: 3}, {name: '广东省',value: 8}, {name: '湖南省',value: 6}, {name: '湖北省',value: 5}, {name: '江西省',value: 5}, {name: '福建省',value: 5}, {name: '浙江省',value: 7}, {name: '江苏省',value: 7}, {name: '山东省',value: 8}, {name: '河南省',value: 4}, {name: '四川省',value: 11}, {name: '海南省',value: 2}, {name: '云南省',value: 11}, {name: '贵州省',value: 6}, {name: '甘肃省',value: 5}, {name: '安徽省',value: 4}, {name: '陕西省',value: 5}, {name: '山西省',value: 4}, {name: '河北省',value: 3}, {name: '辽宁省',value: 8}, {name: '吉林省',value: 3}, {name: '黑龙江省',value: 6}, {name: '内蒙古自治区',value: 8}, {name: '青海省',value: 2}, {name: '宁夏回族自治区',value: 1}, {name: '西藏自治区',value: 3}, {name: '新疆维吾尔自治区',value: 13}, ] }], }; chart.setOption(option); }); </script> </body> </html>工程下载参考资料echarts实现全国及各省市地图(内附地图json文件)http://datav.aliyun.com/portal/school/atlas/area_selector#&lat=31.769817845138945&lng=104.29901249999999&zoom=4
-
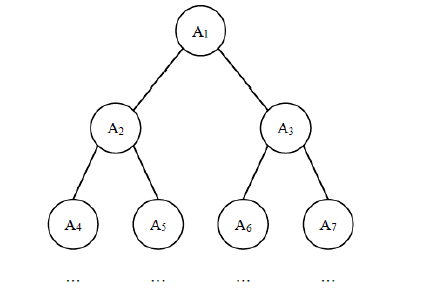
蓝桥杯|历届真题:完全二叉树的权值 1.题目问题描述 给定一棵包含 N 个节点的完全二叉树,树上每个节点都有一个权值,按从 上到下、从左到右的顺序依次是 A1, A2, · · · AN,如下图所示: 现在小明要把相同深度的节点的权值加在一起,他想知道哪个深度的节点 权值之和最大?如果有多个深度的权值和同为最大,请你输出其中最小的深度。 注:根的深度是 1。输入格式 第一行包含一个整数 N。 第二行包含 N 个整数 A1, A2, · · · AN 。输出格式 输出一个整数代表答案。样例输入7 1 6 5 4 3 2 1样例输出2评测用例规模与约定对于所有评测用例,1 ≤ N≤ 100000,−100000 ≤ Ai ≤ 100000。2. 题解2.1 思路分析1.根据节点数量N求解二叉树的高度 完全二叉树为满二叉树或者除去最后一层为满二叉树。 高度为H的满二叉树的节点数量为2^H-1。(根节点记为第1层) 根据这一条件即可求出N个节点对应的完全二叉树的高度treeHeight 2.求解完全二叉树最后一层节点的数量 最后一层节点的数量为N-Math.pow(2,treeHeight-1)+1 3.按层输入每层节点的权值并计算每层的权值和2.2 代码实现import java.util.*; public class Main { static Scanner scanner = new Scanner(System.in); public static void main(String[] args) { int N = scanner.nextInt(); // 求解完全二叉树高度 int treeHeight = 0; int count = 1; while (count<N+1){ count*=2; treeHeight++; } // 记录每层的权值和 int[] weightSumArr = new int[treeHeight+1]; Arrays.fill(weightSumArr,0); // 输入并求权值和 for (int i = 1; i <treeHeight; i++) { for (int j = 0; j < Math.pow(2,i-1); j++) { weightSumArr[i] += scanner.nextInt(); } } for (int i = 0; i < N-Math.pow(2,treeHeight-1)+1; i++) {//最后一层需要单独处理 weightSumArr[treeHeight] += scanner.nextInt(); } int maxWeightHeight = 1; for (int i = 2; i <= treeHeight; i++) { if(weightSumArr[i]>weightSumArr[maxWeightHeight]){ maxWeightHeight = i; } } System.out.println(maxWeightHeight); } }2.3 提交结果评测点序号评测结果得分CPU使用内存使用下载评测数据1正确10.0078ms22.48MB输入 输出2正确10.0062ms22.47MBVIP特权3正确10.0078ms22.51MBVIP特权4正确10.0093ms22.58MBVIP特权5正确10.0093ms25.16MBVIP特权6正确10.00187ms34.37MBVIP特权7正确10.00375ms91.69MBVIP特权8正确10.00390ms91.57MBVIP特权9正确10.00359ms90.37MBVIP特权10正确10.00406ms92.12MBVIP特权参考资料http://lx.lanqiao.cn/problem.page?gpid=T2695
-
JAVA判断一个数是否是质数/批量求质数 1.质数定义:只能被1或者自身整除的自然数(不包括1),称为质数。2.判断一个数是否是质数方法一:根据质数的定义求(效率最低)利用它的定义可以循环判断该数除以比它小的每个自然数(大于1),如果有能被它整除的,则它就不是质数。 时间复杂度:$O(n^2)$/** * 判断传入数值是否为素数 * @param num * @return flag */ private static boolean isPrime1(int num){ boolean flag=true; //判断是否为质数的标记 for (int j=num-1;j>1;j--){ //逐个除以[1,n]区间的数字 if (num%j==0){ flag = false; //若能整除,则置false标记为合数 } } return flag; }方法二:利用合数定理(原理和方法一一致,效率提高了)如果一个数是合数,那么它的最小质因数肯定小于等于他的平方根。 例如,20的最小质因数4必然小于20开方。 时间复杂度:$O(n^{\frac{1}{2}})$/** * 方法二 * @param num * @return */ private static boolean isPrime2(int num){ int s = (int) Math.sqrt(num); //求出数字n的开方 boolean flag = true; //判断是否为质数的标记 for (int j=2;j<=s;j++){ //逐个除以[1,n^1/2]区间的数字 if (num % j == 0){ flag = false; //若能整除,则置false标记为合数 } } return flag; }3.批量求质数--筛法求质数(效率最高,但会比较浪费内存)首先建立一个boolean类型的数组,用来存储你要判断某个范围内自然数中的质数.例:你要输出小于100的质数,可以建立一个大小为101(建立11个存储位置是为了让数组位置与其大小相同)的boolean数组,位置1置false,其他位置初始化为true。即数组初始状态 [null,false,true,true......]然后再获取数字n的开方,即10,然后再从2开始,2的倍数位置置false,即 4 6 8 10....,3的倍数位置置false即 6 9 12..........,以此类推,就把初始数列的合数位置值变成false,true值的位置则为素数。/** * 通过对数组进行标记后,再逐个判断 * @param num * @return */ private static boolean [] isPrime3(int num){ boolean [] array = new boolean[num+1]; //加1为了数组位置一致 array[1] = false; //false为合数,ture为质数 1不是质数 for (int i = 2;i < num;i++){ array[i] = true; //生成一个长度为n的布尔数列 [null,false,true........] } int s = (int)Math.sqrt(num); for (int i = 2;i<=s;i++){ if (array[i]){ //检查是否已经置fales(可以防止重复置false) for (int j=i;j*i<=num;j++){ //将i的倍数下标位置置为false array[j*i] = false; } } } return array; //标记好后的数组返回 }
-
DNS域名解析过程 1.简略版浏览器缓存——》系统hosts文件——》本地DNS解析器缓存——》本地域名服务器(本地配置区域资源、本地域名服务器缓存)——》根域名服务器——》主域名服务器——》下一级域名域名服务器 客户端——》本地域名服务器(递归查询) 本地域名服务器—》DNS服务器的交互查询是迭代查询2.详细解释当我们在浏览器地址栏中输入某个Web服务器的域名时。用户主机首先用户主机会首先在自己的DNS高速缓存中查找该域名所应的IP地址。如果没有找到,则会向网络中的某台DNS服务器查询,DNS服务器中有域名和IP地映射关系的数据库。当DNS服务器收到DNS查询报文后,在其数据库中查询,之后将查询结果发送给用户主机。现在,用户主机中的浏览器可以通过Web服务器的IP地址对其进行访问了。如果上级的DNS没有该域名的DNS缓存,则会继续向更上级查询,包含两种查询方式,分别是递归查询和迭代查询。递归查询如果主机所询问的本地域名服务器不知道被查询域名的 IP 地址,那么本地域名服务器就以 DNS 客户端的身份,向其他根域名服务器继续发出查询请求报文,即替主机继续查询,而不是让主机自己进行下一步查询。我们以一个例子来了解DNS递归查询的工作原理,假设图中的主机 (IP地址为m.xyz.com) 想知道域名y.abc.com的IP地址。1、主机首先向其本地域名服务器进行递归查询。2、本地域名服务器收到递归查询的委托后,也采用递归查询的方式向某个根域名服务器查询。3、根域名服务器收到递归查询的委托后,也采用递归查询的方式向某个顶级域名服务器查询。4、顶级域名服务器收到递归查询的委托后,也采用递归查询的方式向某个权限域名服务器查询。过程如图所示:迭代查询当根域名服务器收到本地域名服务器发出的迭代查询请求报文时,要么给出所要查询的IP 地址,要么告诉本地服务器下一步应该找哪个域名服务器进行查询,然后让本地服务器进行后续的查询。迭代查询过程如下:1、主机首先向其本地域名服务器进行递归查询。2、本地域名服务器采用迭代查询,它先向某个根域名服务器查询。3、根域名服务器告诉本地域名服务器,下一次应查询的顶级域名服务器的IP地址。4、本地域名服务器向顶级域名服务器进行迭代查询。5、顶级域名服务器告诉本地域名服务器,下一次应查询的权限域名服务器的IP地址。6、本地域名服务器向权限域名服务器进行迭代查询。7、权限域名服务器告诉本地域名服务器所查询的域名的IP地址。8、本地域名服务器最后把查询的结果告诉主机。过程如图所示:由于递归查询对于被查询的域名服务器负担太大,通常采用以下模式:从请求主机到本地域名服务器的查询是递归查询,而其余的查询是迭代查询。参考资料DNS解析过程及原理DNS域名解析过程多张图带你彻底搞懂DNS域名解析过程
-
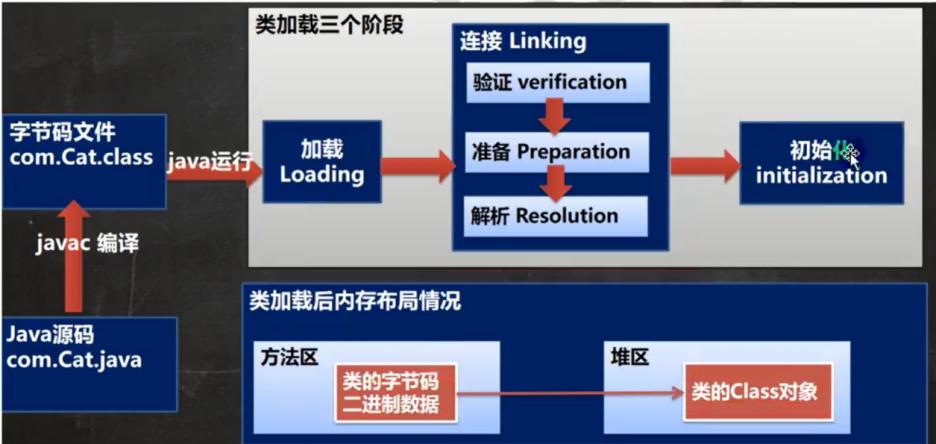
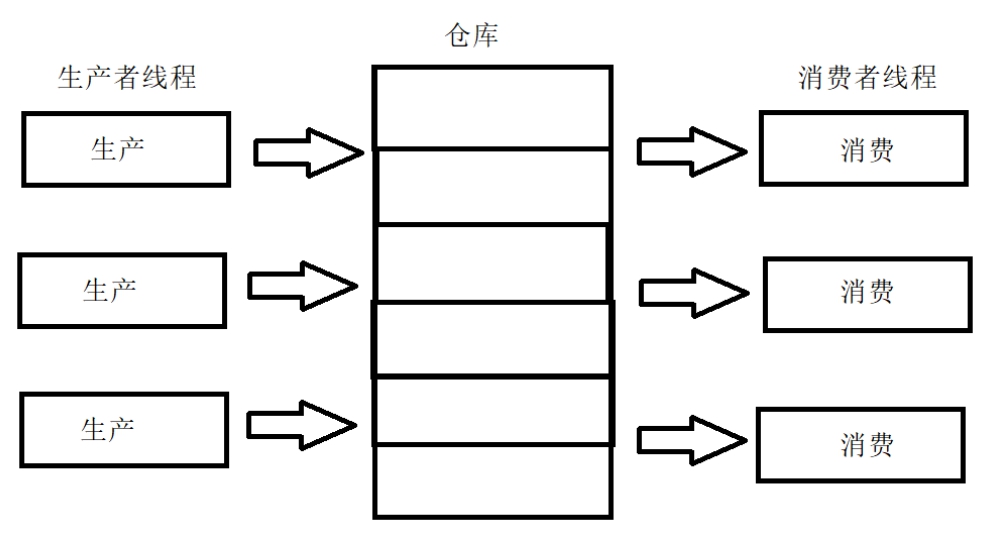
麒麟软件面试题整理 1.“equal”、“==” 和 “hashCode” 的区别和使用场景三者都是用于判断对象之间是否相等的,判断的方式不一样。==对于基本类型,==是比较其值是不是相等,对于引用类型,==比较两个对象是否相同。equals方法equals 方法是用于比较两个独立对象的内容是否相同:如果一个类没有重写 equals(Object obj)方法,则等价于通过 == 比较两个对象,即比较的是对象在内存中的空间地址是否相等。如果重写了equals(Object ibj)方法,则根据重写的方法内容去比较相等,返回 true 则相等,false 则不相等。hashcode()hashCode 是用来在散列存储结构中确定对象的存储地址的。hashCode 的存在主要用于查找的快捷性,如 Hashtable, HashMap 等,如果两个对象相同,就是适用于 euqals(java.lang.Object) 方法,那么这两个对象的 hashCode一定相同。如果对象的euqals 方法被重写,那么对象的 hashCode 也尽量重写,并且产生 hashCode 使用的对象,一定要和 equals 方法中使用的一致。两个对象的 hashCode 相同,并不一定表示这两个对象就相同,也就是不一定适用于equals() 方法,只能够说明这两个对象在散列存储结构中,如 Hashtable.,他们存在同一个篮子里。使用场景:equals 方法是用于比较两个独立对象的内容是否相同。hashCode方法存在的主要目的就是提高判断效率,如用来在散列存储结构中确定对象的存储地址的。因为 hashCode 并不是完全可靠,有时候不同的对象他们生成的 hashcode 也会一样(hash冲突),所以 hashCode只能说是大部分时候可靠,并不是绝对可靠,所以可以得出:equals 相等的两个对象他们的 hashCode 肯定相等,也就是用 equals 对比是绝对可靠的hashCode 相等的两个对象他们的 equals 不一定相等,也就是 hashCode 不是绝对可靠的。对于需要大量并且快速的对比的话如果都用 equals 去做显然效率太低,解决方式是,每当需要对比的时候,首先用 hashCode 去对比,如果 hashCode 不一样,则表示这两个对象肯定不相等(也就是不必再用 equals 去再对比了),如果 hashCode 相同,此时再对比他们的 equals,如果 equals 也相同,则表示这两个对象是真的相同了2.DNS域名解析过程简略版浏览器缓存——》系统hosts文件——》本地DNS解析器缓存——》本地域名服务器(本地配置区域资源、本地域名服务器缓存)——》根域名服务器——》主域名服务器——》下一级域名域名服务器 客户端——》本地域名服务器(递归查询) 本地域名服务器—》DNS服务器的交互查询是迭代查询详细解释当我们在浏览器地址栏中输入某个Web服务器的域名时。用户主机首先用户主机会首先在自己的DNS高速缓存中查找该域名所应的IP地址。如果没有找到,则会向网络中的某台DNS服务器查询,DNS服务器中有域名和IP地映射关系的数据库。当DNS服务器收到DNS查询报文后,在其数据库中查询,之后将查询结果发送给用户主机。现在,用户主机中的浏览器可以通过Web服务器的IP地址对其进行访问了。如果上级的DNS没有该域名的DNS缓存,则会继续向更上级查询,包含两种查询方式,分别是递归查询和迭代查询。递归查询如果主机所询问的本地域名服务器不知道被查询域名的 IP 地址,那么本地域名服务器就以 DNS 客户端的身份,向其他根域名服务器继续发出查询请求报文,即替主机继续查询,而不是让主机自己进行下一步查询。我们以一个例子来了解DNS递归查询的工作原理,假设图中的主机 (IP地址为m.xyz.com) 想知道域名y.abc.com的IP地址。1、主机首先向其本地域名服务器进行递归查询。2、本地域名服务器收到递归查询的委托后,也采用递归查询的方式向某个根域名服务器查询。3、根域名服务器收到递归查询的委托后,也采用递归查询的方式向某个顶级域名服务器查询。4、顶级域名服务器收到递归查询的委托后,也采用递归查询的方式向某个权限域名服务器查询。过程如图所示:迭代查询当根域名服务器收到本地域名服务器发出的迭代查询请求报文时,要么给出所要查询的IP 地址,要么告诉本地服务器下一步应该找哪个域名服务器进行查询,然后让本地服务器进行后续的查询。迭代查询过程如下:1、主机首先向其本地域名服务器进行递归查询。2、本地域名服务器采用迭代查询,它先向某个根域名服务器查询。3、根域名服务器告诉本地域名服务器,下一次应查询的顶级域名服务器的IP地址。4、本地域名服务器向顶级域名服务器进行迭代查询。5、顶级域名服务器告诉本地域名服务器,下一次应查询的权限域名服务器的IP地址。6、本地域名服务器向权限域名服务器进行迭代查询。7、权限域名服务器告诉本地域名服务器所查询的域名的IP地址。8、本地域名服务器最后把查询的结果告诉主机。过程如图所示:由于递归查询对于被查询的域名服务器负担太大,通常采用以下模式:从请求主机到本地域名服务器的查询是递归查询,而其余的查询是迭代查询。3.synchronized关键字及加到方法和对象上的区别Synchronized是Java提供的同步关键字,在多线程场景下,对共享资源代码段进行读写操作(必须包含写操作,光读不会有线程安全问题,因为读操作天然具备线程安全特性),可能会出现线程安全问题,我们可以使用Synchronized锁定共享资源代码段,达到互斥(mutualexclusion)效果,保证线程安全。synchronized 既可以加在一段代码上,也可以加在方法上。加到对象上(加到代码块上)使用synchronized(object) { 代码块.... } 能对代码块进行加锁,不允许其他线程访问,其的作用原理是:在object内有一个变量,当有线程进入时,判断是否为0,如果为0,表示可进入执行该段代码,同时将该变量设置为1,这时其他线程就不能进入;当执行完这段代码时,再将变量设置为0。加到方法上synchronized加在方法上本质上还是等价于加在对象上的。如果synchronized加在一个类的普通方法上,那么相当于synchronized(this)。如果synchronized加载一个类的静态方法上,那么相当于synchronized(Class.this)。4.HTTP/HTTPS区别HTTP协议传输的数据都是未加密的,也就是明文的,因此使用HTTP协议传输隐私信息非常不安全,为了保证这些隐私数据能加密传输,于是网景公司设计了SSL(Secure Sockets Layer)协议用于对HTTP协议传输的数据进行加密,从而就诞生了HTTPS。为了数据传输的安全,HTTPS在HTTP的基础上加入了SSL/TLS协议,SSL/TLS依靠证书来验证服务器的身份,并为浏览器和服务器之间的通信加密。HTTPS和HTTP的区别主要如下:1、https协议需要到ca申请证书,一般免费证书较少,因而需要一定费用。2、http的信息是明文传输,https则是具有安全性的ssl加密传输协议。3、http和https使用的是完全不同的连接方式,用的端口也不一样,前者是80,后者是443。4、http的连接很简单,是无状态的;HTTPS协议是由SSL+HTTP协议构建的可进行加密传输、身份认证的网络协议,比http协议安全。5.MySQL删除数据的方式都有哪些?/delete/drop/truncate区别、谁的速度更快以及原因可以这么理解,一本书,delete是把目录撕了,truncate是把书的内容撕下来烧了,drop是把书烧了常用的三种删除方式:通过 delete、truncate、drop 关键字进行删除;这三种都可以用来删除数据,但场景不同。执行速度drop > truncate >> DELETE区别详解delete1、DELETE属于数据库DML操作语言,只删除数据不删除表的结构,会走事务,执行时会触发trigger;2、在 InnoDB 中,DELETE其实并不会真的把数据删除,mysql 实际上只是给删除的数据打了个标记为已删除,因此 delete 删除表中的数据时,表文件在磁盘上所占空间不会变小,存储空间不会被释放,只是把删除的数据行设置为不可见。虽然未释放磁盘空间,但是下次插入数据的时候,仍然可以重用这部分空间(重用 → 覆盖)。3、DELETE执行时,会先将所删除数据缓存到rollback segement中,事务commit之后生效;4、delete from table_name删除表的全部数据,对于MyISAM 会立刻释放磁盘空间,InnoDB 不会释放磁盘空间;5、对于delete from table_name where xxx 带条件的删除, 不管是InnoDB还是MyISAM都不会释放磁盘空间;6、delete操作以后使用optimize table table_name会立刻释放磁盘空间。不管是InnoDB还是MyISAM 。所以要想达到释放磁盘空间的目的,delete以后执行optimize table 操作。7、delete 操作是一行一行执行删除的,并且同时将该行的的删除操作日志记录在redo和undo表空间中以便进行回滚(rollback)和重做操作,生成的大量日志也会占用磁盘空间。truncate1、truncate:属于数据库DDL定义语言,不走事务,原数据不放到 rollback segment 中,操作不触发 trigger。执行后立即生效,无法找回 执行后立即生效,无法找回 执行后立即生效,无法找回2、truncate table table_name立刻释放磁盘空间 ,不管是 InnoDB和MyISAM。truncate table其实有点类似于drop table 然后creat,只不过这个create table 的过程做了优化,比如表结构文件之前已经有了等等。所以速度上应该是接近drop table的速度;3、truncate能够快速清空一个表。并且重置auto_increment的值。小心使用 truncate,尤其没有备份的时候,如果误删除线上的表,记得及时联系中国民航,订票电话:400-806-9553Drop1、drop:属于数据库DDL定义语言,同Truncate;2、drop table table_name 立刻释放磁盘空间 ,不管是 InnoDB 和 MyISAM;drop 语句将删除表的结构被依赖的约束(constrain)、触发器(trigger)、索引(index); 依赖于该表的存储过程/函数将保留,但是变为 invalid 状态。小心使用 drop ,要删表跑路的兄弟,请在订票成功后在执行操作!订票电话:400-806-95536.Linux根目录下有哪些基本目录/bin:里边包含了一般程序工具,用户、管理员、系统都可以调用。比如常用的ls、cp、cat、mv等等。 /sbin:系统和系统管理员用到的程序工具。 /lib、/lib64:库文件,包含了所有系统和用户需要的程序文件,64表示64位,但实际上除特殊的库,大部分还是链接到了lib目录下。 /home:一般用户目录,一般一个用户对应一个目录,保存用户的数据。 /root:root用户的家目录。 /etc:包含了大部分重要的系统配置文件,这里文件的作用类似windows中的控制面板。 /boot:系统启动文件和内核,在有些发行版中还包括grub,grub是一种通用的启动引导程序。 /dev:系统设备文件目录,除cpu外的所有的硬件设备都会抽象成特殊的文件放在这里,虚拟设备也放在这里。 /media:磁盘设备自动挂载的位置。按照用户分类,每一个用户目录下有其磁盘目录。 /cdrom:专门用来挂载光盘的目录,有些发行版将该目录放在media或mnt目录下。 /mnt:标准挂载点,可以挂载外设磁盘。 /opt:一般存放第三方软件。 /tmp:系统使用的临时空间,重启后会清空。 /var:包含一些用户可变的或临时的文件,比如log文件、邮件队列、网络下载的临时文件等等。 /sys:与proc类似的虚拟文件系统,都是内核提供给用户的接口,可读可写。 /proc:包含系统资源信息的虚拟文件系统,提供了一个接触内核数据的接口,大部分是只读的,有些允许改变。系统运行时才有文件。7.Java类加载过程Java类加载过程主要可以分为三个步骤:加载、连接、初始化。加载:是Java将字节码数据从不同的数据源读取到JVM中,映射为JVM认可的数据结构。连接:是把原始的类定义信息平滑地转入JVM运行的过程中。这一阶段可以细分为验证、准备、解析三步。验证:1.格式检查 --> 魔数验证、版本检查、长度检查2.语义检查 --> 是否继承final、是否有父类、是否实现抽象方法3.直接验证 --> 跳转指令是否只想正确的位置,操作数类型是否合理4.符号引用验证 --> 符号引用的直接引用是否存在准备:为类中的所有静态变量分配内存空间,并为其设置一个初始值(由于还没有产生对象,实例变量不在此操作范围内)被final修饰的静态变量, 会直接赋予原值;类字段的字段属性表中存在ConstantValue属性,则在准备阶段,其值就是ConstantValue的值解析:将常量池中的符号引用转为直接引用(得到类或者字段、方法在内存中的指针或者偏移量,以便直接调用该方法),这个可以在初始化之后 再执行。可以认为是一些静态绑定的会被解析,动态绑定则只会在运行是进行解析;静态绑定包括一些final方法(不可以重写),static方法(只 会属于当前类),构造器(不会被重写)初始化:是执行类初始化的代码逻辑,包括静态字段赋值的动作,以及执行类定义中的静态初始化块内的逻辑。8.堆和栈的区别堆和栈的区别主要有五大点,分别是:1、申请方式的不同。栈由系统自动分配,而堆是人为申请开辟;2、申请大小的不同。栈获得的空间较小,而堆获得的空间较大;3、申请效率的不同。栈由系统自动分配,速度较快,而堆一般速度比较慢;4、存储内容的不同。栈内存存储的是局部变量而堆内存存储的是实体; 栈在函数调用时,函数调用语句的下一条可执行语句的地址第一个进栈,然后函数的各个参数进栈,其中静态变量是不入栈的。而堆一般是在头部用一个字节存放堆的大小,堆中的具体内容是人为安排;5、底层不同。栈是连续的空间,而堆是不连续的空间。6、栈内存存放的变量生命周期一旦结束就会被释放,而堆内存存放的实体会被垃圾回收机制不定时的回收。9.生产者消费者模型概念生产者消费者模式就是通过一个容器来解决生产者和消费者的强耦合问题。生产者和消费者彼此之间不直接通讯,而通过阻塞队列来进行通讯,所以生产者生产完数据之后不用等待消费者处理,直接扔给阻塞队列,消费者不找生产者要数据,而是直接从阻塞队列里取,阻塞队列就相当于一个缓冲区,平衡了生产者和消费者的处理能力。这个阻塞队列就是用来给生产者和消费者解耦的。321原则三种角色:生产者、消费者、仓库两种关系:生产者与生产者之间是互斥关系,消费者与消费者之间是互斥关系,生产者与消费者之间是同步与互斥关系。一个交易场所:仓库优点解耦–生产者。消费者之间不直接通信,降低了耦合度。支持并发支持忙闲不均PV原语描述s1初始值为缓冲区大小、s2初始值为0 生产者: 生产一个产品; P(s1); 送产品到缓冲区; V(s2); 消费者: P(s2); 从缓冲区取出产品; V(s1); 消费水平;代码实现synchronized + wait() + notify() 方式package ProducerAndConsumer; import java.util.ArrayList; import java.util.List; class Produce extends Thread { List<Object> productBuffer; // 产品缓冲区 int bufferCapacity; // 缓冲区容量 public Produce(int bufferCapacity,List<Object> productBuffer){ this.productBuffer = productBuffer; this.bufferCapacity = bufferCapacity; } @Override public void run() { while (true){ // 生产行为 synchronized (productBuffer){ // 如果某一个生产者能执行进来,说明此线程具有productBuffer对象的控制权,其它线程(生产者&消费者)都必须等待 if(productBuffer.size()==bufferCapacity){ // 缓冲区满了 try { productBuffer.wait(1); // 释放控制权并等待 } catch (InterruptedException e) { e.printStackTrace(); } }else { // 缓冲区没满可以继续生产 productBuffer.add(new Object()); System.out.println("生产者生产了1件物品,当前缓冲区里还有" + productBuffer.size() + "件物品"); productBuffer.notifyAll(); // 唤醒等待队列中所有线程 } } // 模拟生产缓冲时间 try { Thread.sleep(2); } catch (InterruptedException e) { e.printStackTrace(); } } } } class Consumer extends Thread{ List<Object> productBuffer; // 产品缓冲区 int bufferCapacity; // 缓冲区容量 public Consumer(int bufferCapacity,List<Object> productBuffer){ this.productBuffer = productBuffer; this.bufferCapacity = bufferCapacity; } @Override public void run(){ while (true){//消费行为 synchronized (productBuffer){ if(productBuffer.isEmpty()){ //产品缓冲区为空,不能消费,只能等待 try { productBuffer.wait(1); } catch (InterruptedException e) { e.printStackTrace(); } }else { // 缓冲区没空可以继续消费 productBuffer.remove(0); System.out.println("消费者消费了1个物品,当前缓冲区里还有" + productBuffer.size() + "件物品"); productBuffer.notifyAll(); } } // 模拟消费缓冲时间 try { Thread.sleep(2); } catch (InterruptedException e) { e.printStackTrace(); } } } } public class ProducerAndConsumer { public static void main(String[] args) { List<Object> productBuffer = new ArrayList<>(); // 产品缓冲区 int bufferCapacity = 3; // 缓冲区容量 for (int i = 0; i < 3; i++) { new Produce(bufferCapacity,productBuffer).start(); } for (int i = 0; i < 3; i++) { new Consumer(bufferCapacity,productBuffer).start(); } } }10.servlet是线程安全的吗Servlet不是线程安全的。当Tomcat接收到Client的HTTP请求时,Tomcat从线程池中取出一个线程,之后找到该请求对应的Servlet对象并进行初始化,之后调用service()方法。要注意的是每一个Servlet对象再Tomcat容器中只有一个实例对象,即是单例模式。如果多个HTTP请求请求的是同一个Servlet,那么着两个HTTP请求对应的线程将并发调用Servlet的service()方法。11.http请求头和响应头信息请求头信息Accept:浏览器能够处理的内容类型Accept-Charset:浏览器能够显示的字符集Accept-Encoding:浏览器能够处理的压缩编码Accept-Language:浏览器当前设置的语言Connection:浏览器与服务器之间连接的类型Cookie:当前页面设置的任何CookieHost:发出请求的页面所在的域Referer:发出请求的页面的URLUser-Agent:浏览器的用户代理字符串响应头信息Date:表示消息发送的时间,时间的描述格式由rfc822定义server:服务器名字。Connection:浏览器与服务器之间连接的类型content-type:表示后面的文档属于什么MIME类型Cache-Control:控制HTTP缓存参考资料“equal”、“==” 和 “hashCode” 的区别和使用场景?Java 基础 | hashCode 和 equals 在实体类的应用场景 Java的synchronized加在方法上或者对象上有什么区别?13张图,深入理解Synchronized全网最全JAVA面试八股文,终于整理完了面试官灵魂一问:MySQL 的 delete、truncate、drop 有什么区别?Linux根目录下各个目录的介绍HTTP与HTTPS的区别多张图带你彻底搞懂DNS域名解析过程java 类加载过程(步骤)详解堆和栈的区别有哪些?PV操作-生产者/消费者关系Java 学习笔记 使用synchronized实现生产者消费者模式 经典面试题 -- 手写生产者消费者模式Java面试题:Servlet是线程安全的吗?http的请求头都有那些信息
-
生产者消费者模型原理及java实现 1.概念生产者消费者模式就是通过一个容器来解决生产者和消费者的强耦合问题。生产者和消费者彼此之间不直接通讯,而通过阻塞队列来进行通讯,所以生产者生产完数据之后不用等待消费者处理,直接扔给阻塞队列,消费者不找生产者要数据,而是直接从阻塞队列里取,阻塞队列就相当于一个缓冲区,平衡了生产者和消费者的处理能力。这个阻塞队列就是用来给生产者和消费者解耦的。2.321原则三种角色:生产者、消费者、仓库两种关系:生产者与生产者之间是互斥关系,消费者与消费者之间是互斥关系,生产者与消费者之间是同步与互斥关系。一个交易场所:仓库3.优点解耦–生产者。消费者之间不直接通信,降低了耦合度。支持并发支持忙闲不均4.PV原语描述s1初始值为缓冲区大小、s2初始值为0 生产者: 生产一个产品; P(s1); 送产品到缓冲区; V(s2); 消费者: P(s2); 从缓冲区取出产品; V(s2); 消费水平;5.代码实现5.1 synchronized + wait() + notify() 方式package ProducerAndConsumer; import java.util.ArrayList; import java.util.List; class Produce extends Thread { List<Object> productBuffer; // 产品缓冲区 int bufferCapacity; // 缓冲区容量 public Produce(int bufferCapacity,List<Object> productBuffer){ this.productBuffer = productBuffer; this.bufferCapacity = bufferCapacity; } @Override public void run() { while (true){ // 生产行为 synchronized (productBuffer){ // 如果某一个生产者能执行进来,说明此线程具有productBuffer对象的控制权,其它线程(生产者&消费者)都必须等待 if(productBuffer.size()==bufferCapacity){ // 缓冲区满了 try { productBuffer.wait(1); // 释放控制权并等待 } catch (InterruptedException e) { e.printStackTrace(); } }else { // 缓冲区没满可以继续生产 productBuffer.add(new Object()); System.out.println("生产者生产了1件物品,当前缓冲区里还有" + productBuffer.size() + "件物品"); productBuffer.notifyAll(); // 唤醒等待队列中所有线程 } } // 模拟生产缓冲时间 try { Thread.sleep(2); } catch (InterruptedException e) { e.printStackTrace(); } } } } class Consumer extends Thread{ List<Object> productBuffer; // 产品缓冲区 int bufferCapacity; // 缓冲区容量 public Consumer(int bufferCapacity,List<Object> productBuffer){ this.productBuffer = productBuffer; this.bufferCapacity = bufferCapacity; } @Override public void run(){ while (true){//消费行为 synchronized (productBuffer){ if(productBuffer.isEmpty()){ //产品缓冲区为空,不能消费,只能等待 try { productBuffer.wait(1); } catch (InterruptedException e) { e.printStackTrace(); } }else { // 缓冲区没空可以继续消费 productBuffer.remove(0); System.out.println("消费者消费了1个物品,当前缓冲区里还有" + productBuffer.size() + "件物品"); productBuffer.notifyAll(); } } // 模拟消费缓冲时间 try { Thread.sleep(2); } catch (InterruptedException e) { e.printStackTrace(); } } } } public class ProducerAndConsumer { public static void main(String[] args) { List<Object> productBuffer = new ArrayList<>(); // 产品缓冲区 int bufferCapacity = 3; // 缓冲区容量 for (int i = 0; i < 3; i++) { new Produce(bufferCapacity,productBuffer).start(); } for (int i = 0; i < 3; i++) { new Consumer(bufferCapacity,productBuffer).start(); } } }5.2 可重入锁ReentrantLock (配合Condition)方式package ProducerAndConsumer; import java.util.ArrayList; import java.util.List; import java.util.concurrent.locks.Condition; import java.util.concurrent.locks.ReentrantLock; class Produce extends Thread { List<Object> productBuffer; // 产品缓冲区 int bufferCapacity; // 缓冲区容量 ReentrantLock lock; // 可重入锁 Condition producerCondition; // 生产者condition Condition consumerCondition; // 消费者condition public Produce(int bufferCapacity,List<Object> productBuffer,ReentrantLock lock,Condition producerCondition,Condition consumerCondition){ this.productBuffer = productBuffer; this.bufferCapacity = bufferCapacity; this.lock = lock; this.producerCondition = producerCondition; this.consumerCondition = consumerCondition; } @Override public void run() { while (true) { // 生产行为 lock.lock(); //加锁 if (productBuffer.size() == bufferCapacity) { // 缓冲区满了 try { producerCondition.await(); // 释放控制权并等待 } catch (InterruptedException e) { e.printStackTrace(); } } else { // 缓冲区没满可以继续生产 productBuffer.add(new Object()); System.out.println("生产者生产了1件物品,当前缓冲区里还有" + productBuffer.size() + "件物品"); consumerCondition.signal(); // 唤醒消费者线程 } lock.unlock(); //解锁 // 模拟生产缓冲时间 try { Thread.sleep(2); } catch (InterruptedException e) { e.printStackTrace(); } } } } class Consumer extends Thread{ List<Object> productBuffer; // 产品缓冲区 int bufferCapacity; // 缓冲区容量 ReentrantLock lock; // 可重入锁 Condition producerCondition; // 生产者condition Condition consumerCondition; // 消费者condition public Consumer(int bufferCapacity,List<Object> productBuffer,ReentrantLock lock,Condition producerCondition,Condition consumerCondition){ this.productBuffer = productBuffer; this.bufferCapacity = bufferCapacity; this.lock = lock; this.producerCondition = producerCondition; this.consumerCondition = consumerCondition; } @Override public void run(){ while (true){//消费行为 lock.lock();//加锁 if(productBuffer.isEmpty()){ //产品缓冲区为空,不能消费,只能等待 try { consumerCondition.await(); } catch (InterruptedException e) { e.printStackTrace(); } }else { // 缓冲区没空可以继续消费 productBuffer.remove(0); System.out.println("消费者消费了1个物品,当前缓冲区里还有" + productBuffer.size() + "件物品"); producerCondition.signal(); // 唤醒生产者线程继续生产 } lock.unlock(); //解锁 // 模拟消费缓冲时间 try { Thread.sleep(2); } catch (InterruptedException e) { e.printStackTrace(); } } } } public class ProducerAndConsumer { public static void main(String[] args) { List<Object> productBuffer = new ArrayList<>(); // 产品缓冲区 int bufferCapacity = 3; // 缓冲区容量 ReentrantLock lock = new ReentrantLock(); // 可重入锁 Condition producerCondition = lock.newCondition(); // 生产者condition Condition consumerCondition = lock.newCondition(); // 消费者condition for (int i = 0; i < 3; i++) { new Produce(bufferCapacity,productBuffer,lock,producerCondition,consumerCondition).start(); } for (int i = 0; i < 3; i++) { new Consumer(bufferCapacity,productBuffer,lock,producerCondition,consumerCondition).start(); } } }参考资料PV操作-生产者/消费者关系Java 学习笔记 使用synchronized实现生产者消费者模式 经典面试题 -- 手写生产者消费者模式
-
Python字符串处理:过滤字符串中的英文与符号,保留汉字 使用Python 的re模块,re模块提供了re.sub用于替换字符串中的匹配项。1 re.sub(pattern, repl, string, count=0) 参数说明:pattern:正则重的模式字符串repl:被拿来替换的字符串string:要被用于替换的原始字符串count:模式匹配后替换的最大次数,省略则默认为0,表示替换所有的匹配例如import re str = "hello,world!!%[545]你好234世界。。。" str = re.sub("[A-Za-z0-9\!\%\[\]\,\。]", "", str) print(str) 输出结果:你好世界
-
python读写csv文件 逗号分隔值(Comma-Separated Values,CSV,有时也称为字符分隔值,因为分隔字符也可以不是逗号),其文件以纯文本形式存储表格数据(数字和文本)1.读csv文件# coding:utf-8 import csv data_list = csv.reader(open('data.csv','r',encoding="utf8")) for data_item in data_list: print(data_item) 代码结果: ['测试1', '软件测试工程师'] ['测试2', '软件测试工程师'] ['测试3', '软件测试工程师'] ['测试4', '软件测试工程师'] ['测试5', '软件测试工程师']2.写入CSV文件# coding:utf-8 import csv data_list = [ ("测试1",'软件测试工程师'), ("测试2",'软件测试工程师'), ("测试3",'软件测试工程师'), ("测试4",'软件测试工程师'), ("测试5",'软件测试工程师'), ] f = open('data.csv','w',encoding="utf8") csv_writer = csv.writer(f) for data_item in data_list: csv_writer.writerow(data_item) f.close()参考资料python读写csv文件
-
mAP计算工具使用|快速计算mAP 计算mAP的工具:https://github.com/Cartucho/mAP1.使用步骤clone代码git clone https://github.com/Cartucho/mAPCreate the ground-truth files(将标签文件转为对应的格式,,工具参考2.1)format<class_name> <left> <top> <right> <bottom> [<difficult>]E.g. "image_1.txt"tvmonitor 2 10 173 238 book 439 157 556 241 book 437 246 518 351 difficult pottedplant 272 190 316 259Copy the ground-truth files into the folder input/ground-truth/Create the detection-results filesformat<class_name> <confidence> <left> <top> <right> <bottom>E.g. "image_1.txt"tvmonitor 0.471781 0 13 174 244 cup 0.414941 274 226 301 265 book 0.460851 429 219 528 247 chair 0.292345 0 199 88 436 book 0.269833 433 260 506 336Copy the detection-results files into the folder input/detection-results/Run the codepython main.py2.工具补充2.1 VOC_2_gt.py设置好xml_dir并执行即可得到对应的gt_txt文件import os import xmltodict import shutil from tqdm import tqdm # TODO:需要修改的内容 xml_dir = "/data/jupiter/project/dataset/帯広空港_per_frame/xml/" gt_dir = "./input/ground-truth/" shutil.rmtree(gt_dir) os.mkdir(gt_dir) """ 将voc xml 的数据转为对应的gt_str """ def voc_2_gt_str(xml_dict): objects = xml_dict["annotation"]["object"] obj_list = [] if isinstance(objects,list): # xml文件中包含多个object for obj in objects: obj_list.append(obj) else: # xml文件中包含1个object obj_list.append(objects) # 获取gt格式的数据信息 gt_str = "" for obj in obj_list: left = int(obj['bndbox']['xmin']) top = int(obj['bndbox']['ymin']) right = int(obj['bndbox']['xmax']) bottom = int(obj['bndbox']['ymax']) obj_name = obj['name'] gt_str += "%s %s %s %s %s\n" % (obj_name, left, top, right, bottom) return gt_str xml_list = os.listdir(xml_dir) pbar = tqdm(total=len(xml_list)) # 加入进度条支持 pbar.set_description("VOC2GT") # 设置前缀 for tmp_file in xml_list: xml_path = os.path.join(xml_dir,tmp_file) gt_txt_path = os.path.join(gt_dir,tmp_file.replace(".xml", ".txt")) # 读取xml文件+转为字典 with open(xml_path,'r',encoding="utf8") as f: xml_str = f.read() xml_dict = xmltodict.parse(xml_str) # 提取对应的数据 gt_str = voc_2_gt_str(xml_dict) # 写入对应的gt_txt文件 with open(gt_txt_path, "w") as f: f.write(gt_str) pbar.update(1) pbar.close()VOC2GT: 27%|██████████████████████████████████████████████████████████████▌ | 24013/89029 [03:25<09:54, 109.31it/s]2.2 YOLOv5_2_dr.py# YOLOv5_2_dr import os import xmltodict import shutil from tqdm import tqdm # TODO:需要修改的内容 yolov5_detect_txt_dir = "/data/jupiter/project/目标检测对比实验/yolov5/runs/detect/exp3/labels" cls_list = ['conveyor', 'refueller', 'aircraft', 'lounge', 'dining car', 'front of baggage car', 'tractor'] img_width = 1632 img_height = 1080 def txt_convert(txt_src,img_width,img_height,cls_list): txt_dst = "" for line in txt_src.split("\n"): if(len(line)==0):continue cls_id,dx,dy,dw,dh,conf = line.split(" ") cls_name = cls_list[int(cls_id)].replace(" ","") x_center = int(float(dx)*img_width) y_center = int(float(dy)*img_height) w = int(float(dw)*img_width) h = int(float(dh)*img_height) x1 = x_center - int(w/2) y1 = y_center - int(h/2) x2 = x1 + w y2 = y1 + h txt_dst += "{} {} {} {} {} {}\n".format(cls_name,conf,x1,y1,x2,y2) return txt_dst dr_dir = "./input/detection-results/" txt_list = os.listdir(yolov5_detect_txt_dir) pbar = tqdm(total=len(txt_list)) # 加入进度条支持 pbar.set_description("YOLOv5_2_dr") # 设置前缀 for file in txt_list: txt_path_src = os.path.join(yolov5_detect_txt_dir,file) txt_path_dst = os.path.join(dr_dir,"{:>05d}.txt".format(int(file.split("_")[1][:-4]))) # 读取原文件 with open(txt_path_src) as f: txt_src = f.read() # 转为目标格式 txt_dst = txt_convert(txt_src,img_width,img_height,cls_list) # 写入对应的dr_txt文件 with open(txt_path_dst,"w") as f: f.write(txt_dst) pbar.update(1) pbar.close()参考资料https://github.com/Cartucho/mAP.git目标检测中的mAP及代码实现
-
leetcode|中等:15. 三数之和 1.题目给你一个包含 n 个整数的数组 nums,判断 nums 中是否存在三个元素 a,b,c ,使得 a + b + c = 0 ?请你找出所有和为 0 且不重复的三元组。注意:答案中不可以包含重复的三元组。示例 1:输入:nums = [-1,0,1,2,-1,-4] 输出:[[-1,-1,2],[-1,0,1]]示例 2:输入:nums = [] 输出:[]示例 3:输入:nums = [0] 输出:[]提示:$0 <= nums.length <= 3000$$-10^5 <= nums[i] <= 10^5$2. 题解2.1 思路分析首先对数组进行排序,排序后固定一个数 nums[i] 如果 nums[i]大于 0,则三数之和必然无法等于 0,结束循环 否则使用左右指针指向nums[i]后面的两端,数字分别为 nums[L]和 nums[R]计算三个数的和 sum 判断是否满足等于0 等于0则添加进结果集 小于0则L++(L<R) 大于0则R--(L<R) 关于去重: 如果 nums[i]== nums[i-1],则说明该数字重复,会导致结果重复,所以应该跳过 当 sum == 0 时,nums[L] == nums[L+1]则会导致结果重复,应该跳过,L++ 当 sum == 0 时,nums[R] == nums[R-1] 则会导致结果重复,应该跳过,R--2.2 代码实现import java.util.*; public class Solution { public List<List<Integer>> threeSum(int[] nums) { // 数组排序 Arrays.sort(nums); List<List<Integer>> res = new ArrayList<>(); if(nums.length>=3) { for (int i = 0; i < nums.length; i++) { if (nums[i] > 0) break; if(i > 0 && nums[i] == nums[i-1]) continue; // 去重 int L = i + 1; // 左指针 int R = nums.length - 1; // 右指针 while (L < R) { while (L < R && nums[L] == nums[L + 1]) L++; // 去重 while (L < R && nums[R] == nums[R - 1]) R--; // 去重 int sum = nums[i] + nums[L] + nums[R]; if (sum == 0) { res.add(Arrays.asList(nums[i], nums[L], nums[R])); L++; R--; } else if (sum < 0) { L++; } else { R--; } } } } return res; } public static void main(String[] args) { Solution solution = new Solution(); System.out.println(solution.threeSum(new int[]{-1, 0, 1, 2, -1, -4})); } }2.3 提交结果提交结果执行用时内存消耗语言提交时间备注通过19 ms45.6 MBJava2022/03/24 20:29添加备注参考资料https://leetcode-cn.com/problems/3sum/https://leetcode-cn.com/problems/3sum/solution/hua-jie-suan-fa-15-san-shu-zhi-he-by-guanpengchn/
-
leetcode|中等:12. 整数转罗马数字 1.题目罗马数字包含以下七种字符: I, V, X, L,C,D 和 M。字符 数值 I 1 V 5 X 10 L 50 C 100 D 500 M 1000例如, 罗马数字 2 写做 II ,即为两个并列的 1。12 写做 XII ,即为 X + II 。 27 写做 XXVII, 即为 XX + V + II 。通常情况下,罗马数字中小的数字在大的数字的右边。但也存在特例,例如 4 不写做 IIII,而是 IV。数字 1 在数字 5 的左边,所表示的数等于大数 5 减小数 1 得到的数值 4 。同样地,数字 9 表示为 IX。这个特殊的规则只适用于以下六种情况:I 可以放在 V (5) 和 X (10) 的左边,来表示 4 和 9。X 可以放在 L (50) 和 C (100) 的左边,来表示 40 和 90。C 可以放在 D (500) 和 M (1000) 的左边,来表示 400 和 900。给你一个整数,将其转为罗马数字。示例 1:输入: num = 3 输出: "III"示例 2:输入: num = 4 输出: "IV"示例 3:输入: num = 9 输出: "IX"示例 4:输入: num = 58 输出: "LVIII" 解释: L = 50, V = 5, III = 3.示例 5:输入: num = 1994 输出: "MCMXCIV" 解释: M = 1000, CM = 900, XC = 90, IV = 4.提示:1 <= num <= 39992. 题解2.1 思路分析思路1:贪心 首先我们构造出所有可能会出现的元素 vals = {1,4,5,9,10,40,50,90,100,400,500,900,1000}; keys = {"I","IV","V","IX","X","XL","L","XC","C","CD","D","CM","M"}; 然后我们每次尽量使用最大的数来表示。 比如对于 1994 这个数,如果我们每次尽量用最大的数来表示,依次选 1000,900,90,4,会得到正确结果 MCMXCIV。2.2 代码实现public class Solution { public String intToRoman(int num) { int[] vals = {1,4,5,9,10,40,50,90,100,400,500,900,1000}; String[] keys = {"I","IV","V","IX","X","XL","L","XC","C","CD","D","CM","M"}; StringBuilder sb = new StringBuilder(); while (num>0){ // 先确定是要减哪一个 int targetIndex = vals.length-1; while (vals[targetIndex]>num){targetIndex--;}; sb.append(keys[targetIndex]); num -= vals[targetIndex]; } return sb.toString(); } public static void main(String[] args) { Solution solution = new Solution(); System.out.println(solution.intToRoman(1994)); } } 2.3 提交结果提交结果执行用时内存消耗语言提交时间备注通过3 ms40.7 MBJava2022/03/24 13:07添加备注参考资料https://leetcode-cn.com/problems/integer-to-roman/