搜索到
62
篇与
的结果
-
 fastrcnn网络结构复现 1.backbone-restnet50import math import torch.nn as nn class Bottleneck(nn.Module): expansion = 4 def __init__(self, inplanes, planes, stride=1, downsample=None): super(Bottleneck, self).__init__() self.conv1 = nn.Conv2d(inplanes, planes, kernel_size=1, stride=stride, bias=False) self.bn1 = nn.BatchNorm2d(planes) self.conv2 = nn.Conv2d(planes, planes, kernel_size=3, stride=1, padding=1, bias=False) self.bn2 = nn.BatchNorm2d(planes) self.conv3 = nn.Conv2d(planes, planes * 4, kernel_size=1, bias=False) self.bn3 = nn.BatchNorm2d(planes * 4) self.relu = nn.ReLU(inplace=True) self.downsample = downsample self.stride = stride def forward(self, x): residual = x out = self.conv1(x) out = self.bn1(out) out = self.relu(out) out = self.conv2(out) out = self.bn2(out) out = self.relu(out) out = self.conv3(out) out = self.bn3(out) if self.downsample is not None: residual = self.downsample(x) out += residual out = self.relu(out) return out class ResNet(nn.Module): def __init__(self, block, layers, num_classes=1000): #-----------------------------------# # 假设输入进来的图片是600,600,3 #-----------------------------------# self.inplanes = 64 super(ResNet, self).__init__() # 600,600,3 -> 300,300,64 self.conv1 = nn.Conv2d(3, 64, kernel_size=7, stride=2, padding=3, bias=False) self.bn1 = nn.BatchNorm2d(64) self.relu = nn.ReLU(inplace=True) # 300,300,64 -> 150,150,64 self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=0, ceil_mode=True) # 150,150,64 -> 150,150,256 self.layer1 = self._make_layer(block, 64, layers[0]) # 150,150,256 -> 75,75,512 self.layer2 = self._make_layer(block, 128, layers[1], stride=2) # 75,75,512 -> 38,38,1024 到这里可以获得一个38,38,1024的共享特征层 self.layer3 = self._make_layer(block, 256, layers[2], stride=2) # self.layer4被用在classifier模型中 self.layer4 = self._make_layer(block, 512, layers[3], stride=2) self.avgpool = nn.AvgPool2d(7) self.fc = nn.Linear(512 * block.expansion, num_classes) for m in self.modules(): if isinstance(m, nn.Conv2d): n = m.kernel_size[0] * m.kernel_size[1] * m.out_channels m.weight.data.normal_(0, math.sqrt(2. / n)) elif isinstance(m, nn.BatchNorm2d): m.weight.data.fill_(1) m.bias.data.zero_() def _make_layer(self, block, planes, blocks, stride=1): downsample = None #-------------------------------------------------------------------# # 当模型需要进行高和宽的压缩的时候,就需要用到残差边的downsample #-------------------------------------------------------------------# if stride != 1 or self.inplanes != planes * block.expansion: downsample = nn.Sequential( nn.Conv2d(self.inplanes, planes * block.expansion,kernel_size=1, stride=stride, bias=False), nn.BatchNorm2d(planes * block.expansion), ) layers = [] layers.append(block(self.inplanes, planes, stride, downsample)) self.inplanes = planes * block.expansion for i in range(1, blocks): layers.append(block(self.inplanes, planes)) return nn.Sequential(*layers) def forward(self, x): x = self.conv1(x) x = self.bn1(x) x = self.relu(x) x = self.maxpool(x) x = self.layer1(x) x = self.layer2(x) x = self.layer3(x) x = self.layer4(x) x = self.avgpool(x) x = x.view(x.size(0), -1) x = self.fc(x) return x def resnet50(): model = ResNet(Bottleneck, [3, 4, 6, 3]) #----------------------------------------------------------------------------# # 获取特征提取部分,从conv1到model.layer3,最终获得一个38,38,1024的特征层 #----------------------------------------------------------------------------# features = list([model.conv1, model.bn1, model.relu, model.maxpool, model.layer1, model.layer2, model.layer3]) #----------------------------------------------------------------------------# # 获取分类部分,从model.layer4到model.avgpool #----------------------------------------------------------------------------# classifier = list([model.layer4, model.avgpool]) features = nn.Sequential(*features) classifier = nn.Sequential(*classifier) return features, classifier extractor,classifier = resnet50() print(extractor)Sequential( (0): Conv2d(3, 64, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3), bias=False) (1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (2): ReLU(inplace=True) (3): MaxPool2d(kernel_size=3, stride=2, padding=0, dilation=1, ceil_mode=True) (4): Sequential( (0): Bottleneck( (conv1): Conv2d(64, 64, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (conv3): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn3): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (relu): ReLU(inplace=True) (downsample): Sequential( (0): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False) (1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) ) ) (1): Bottleneck( (conv1): Conv2d(256, 64, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (conv3): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn3): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (relu): ReLU(inplace=True) ) (2): Bottleneck( (conv1): Conv2d(256, 64, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (conv3): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn3): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (relu): ReLU(inplace=True) ) ) (5): Sequential( (0): Bottleneck( (conv1): Conv2d(256, 128, kernel_size=(1, 1), stride=(2, 2), bias=False) (bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (conv3): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn3): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (relu): ReLU(inplace=True) (downsample): Sequential( (0): Conv2d(256, 512, kernel_size=(1, 1), stride=(2, 2), bias=False) (1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) ) ) (1): Bottleneck( (conv1): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (conv3): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn3): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (relu): ReLU(inplace=True) ) (2): Bottleneck( (conv1): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (conv3): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn3): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (relu): ReLU(inplace=True) ) (3): Bottleneck( (conv1): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (conv3): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn3): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (relu): ReLU(inplace=True) ) ) (6): Sequential( (0): Bottleneck( (conv1): Conv2d(512, 256, kernel_size=(1, 1), stride=(2, 2), bias=False) (bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (relu): ReLU(inplace=True) (downsample): Sequential( (0): Conv2d(512, 1024, kernel_size=(1, 1), stride=(2, 2), bias=False) (1): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) ) ) (1): Bottleneck( (conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (relu): ReLU(inplace=True) ) (2): Bottleneck( (conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (relu): ReLU(inplace=True) ) (3): Bottleneck( (conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (relu): ReLU(inplace=True) ) (4): Bottleneck( (conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (relu): ReLU(inplace=True) ) (5): Bottleneck( (conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (relu): ReLU(inplace=True) ) ) )2.RPNimport numpy as np def generate_anchor_base(base_size=16, ratios=[0.5, 1, 2], anchor_scales=[8, 16, 32]): anchor_base = np.zeros((len(ratios) * len(anchor_scales), 4), dtype=np.float32) for i in range(len(ratios)): for j in range(len(anchor_scales)): h = base_size * anchor_scales[j] * np.sqrt(ratios[i]) w = base_size * anchor_scales[j] * np.sqrt(1. / ratios[i]) index = i * len(anchor_scales) + j anchor_base[index, 0] = - h / 2. anchor_base[index, 1] = - w / 2. anchor_base[index, 2] = h / 2. anchor_base[index, 3] = w / 2. return anchor_base # 产生特征图上每个点对应的9个base anchor def _enumerate_shifted_anchor(anchor_base, feat_stride, height, width): # 计算网格中心点 shift_x = np.arange(0, width * feat_stride, feat_stride) shift_y = np.arange(0, height * feat_stride, feat_stride) shift_x, shift_y = np.meshgrid(shift_x, shift_y) shift = np.stack((shift_x.ravel(),shift_y.ravel(), shift_x.ravel(),shift_y.ravel(),), axis=1) # 每个网格点上的9个先验框 A = anchor_base.shape[0] K = shift.shape[0] anchor = anchor_base.reshape((1, A, 4)) + \ shift.reshape((K, 1, 4)) # 所有的先验框 anchor = anchor.reshape((K * A, 4)).astype(np.float32) return anchor import matplotlib.pyplot as plt nine_anchors = generate_anchor_base() # 产生特征图上每个点对应的9个base anchor height, width, feat_stride = 38,38,16 # 特征图的shape feature_map_w,feature_map_h,feature_map_c = 38,38,16 # 生成整个特征图对应的所有的base anchor ,总计feature_map_w*feature_map_h*9个 anchors_all = _enumerate_shifted_anchor(nine_anchors,feat_stride,height,width) print(np.shape(anchors_all)) fig = plt.figure() ax = fig.add_subplot(111) plt.ylim(-300,900) plt.xlim(-300,900) # 模拟绘制特征提取之前的原图 shift_x = np.arange(0, width * feat_stride, feat_stride) shift_y = np.arange(0, height * feat_stride, feat_stride) shift_x, shift_y = np.meshgrid(shift_x, shift_y) plt.scatter(shift_x,shift_y) # 绘制特征图上像素点(pix_x,pix_y)对应原图的所有anchor pix_x,pix_y = 12,0 index_begin = pix_y*width*9 + pix_x*9 index_end = pix_y*width*9 + pix_x*9 + 9 print(index_begin) box_widths = anchors_all[:,2]-anchors_all[:,0] box_heights = anchors_all[:,3]-anchors_all[:,1] for i in range(index_begin,index_end): rect = plt.Rectangle([anchors_all[i, 0],anchors_all[i, 1]],box_widths[i],box_heights[i],color="r",fill=False) ax.add_patch(rect) plt.show()# 将RPN网络预测结果转化成建议框 def loc2bbox(src_bbox, loc): if src_bbox.size()[0] == 0: return torch.zeros((0, 4), dtype=loc.dtype) src_width = torch.unsqueeze(src_bbox[:, 2] - src_bbox[:, 0], -1) src_height = torch.unsqueeze(src_bbox[:, 3] - src_bbox[:, 1], -1) src_ctr_x = torch.unsqueeze(src_bbox[:, 0], -1) + 0.5 * src_width src_ctr_y = torch.unsqueeze(src_bbox[:, 1], -1) + 0.5 * src_height dx = loc[:, 0::4] dy = loc[:, 1::4] dw = loc[:, 2::4] dh = loc[:, 3::4] ctr_x = dx * src_width + src_ctr_x ctr_y = dy * src_height + src_ctr_y w = torch.exp(dw) * src_width h = torch.exp(dh) * src_height dst_bbox = torch.zeros_like(loc) dst_bbox[:, 0::4] = ctr_x - 0.5 * w dst_bbox[:, 1::4] = ctr_y - 0.5 * h dst_bbox[:, 2::4] = ctr_x + 0.5 * w dst_bbox[:, 3::4] = ctr_y + 0.5 * h return dst_bboxclass ProposalCreator(): def __init__(self, mode, nms_thresh=0.7, n_train_pre_nms=12000, n_train_post_nms=600, n_test_pre_nms=3000, n_test_post_nms=300, min_size=16): self.mode = mode self.nms_thresh = nms_thresh self.n_train_pre_nms = n_train_pre_nms self.n_train_post_nms = n_train_post_nms self.n_test_pre_nms = n_test_pre_nms self.n_test_post_nms = n_test_post_nms self.min_size = min_size def __call__(self, loc, score, anchor, img_size, scale=1.): if self.mode == "training": n_pre_nms = self.n_train_pre_nms n_post_nms = self.n_train_post_nms else: n_pre_nms = self.n_test_pre_nms n_post_nms = self.n_test_post_nms anchor = torch.from_numpy(anchor) if loc.is_cuda: anchor = anchor.cuda() #-----------------------------------# # 将RPN网络预测结果转化成建议框 #-----------------------------------# roi = loc2bbox(anchor, loc) #-----------------------------------# # 防止建议框超出图像边缘 #-----------------------------------# roi[:, [0, 2]] = torch.clamp(roi[:, [0, 2]], min = 0, max = img_size[1]) roi[:, [1, 3]] = torch.clamp(roi[:, [1, 3]], min = 0, max = img_size[0]) #-----------------------------------# # 建议框的宽高的最小值不可以小于16 #-----------------------------------# min_size = self.min_size * scale keep = torch.where(((roi[:, 2] - roi[:, 0]) >= min_size) & ((roi[:, 3] - roi[:, 1]) >= min_size))[0] roi = roi[keep, :] score = score[keep] #-----------------------------------# # 根据得分进行排序,取出建议框 #-----------------------------------# order = torch.argsort(score, descending=True) if n_pre_nms > 0: order = order[:n_pre_nms] roi = roi[order, :] score = score[order] #-----------------------------------# # 对建议框进行非极大抑制 #-----------------------------------# keep = nms(roi, score, self.nms_thresh) keep = keep[:n_post_nms] roi = roi[keep] return roi3.合并backbone与rpn--记为FRCNN_RPNclass FRCNN_RPN(nn.Module): def __init__(self,extractor,rpn): super(FRCNN_RPN, self).__init__() self.extractor = extractor self.rpn = rpn def forward(self, x, img_size): print(img_size) feature_map = self.extractor(x) rpn_locs, rpn_scores, rois, roi_indices, anchor = self.rpn(feature_map,img_size) return rpn_locs, rpn_scores, rois, roi_indices, anchor# 加载模型参数 param = torch.load("./frcnn-restnet50.pth") param.keys() rpn = RegionProposalNetwork(in_channels=1024,mode="predict") frcnn_rpn = FRCNN_RPN(extractor,rpn) frcnn_rpn_state_dict = frcnn_rpn.state_dict() for key in frcnn_rpn_state_dict.keys(): frcnn_rpn_state_dict[key] = param[key] frcnn_rpn.load_state_dict(frcnn_rpn_state_dict)from PIL import Image import copy def get_new_img_size(width, height, img_min_side=600): if width <= height: f = float(img_min_side) / width resized_height = int(f * height) resized_width = int(img_min_side) else: f = float(img_min_side) / height resized_width = int(f * width) resized_height = int(img_min_side) return resized_width, resized_height img_path = os.path.join("xx.jpg") image = Image.open(img_path) image = image.convert("RGB") # 转换成RGB图片,可以用于灰度图预测。 image_shape = np.array(np.shape(image)[0:2]) old_width, old_height = image_shape[1], image_shape[0] old_image = copy.deepcopy(image) # 给原图像进行resize,resize到短边为600的大小上 width,height = get_new_img_size(old_width, old_height) image = image.resize([width,height], Image.BICUBIC) print(image.size) # 图片预处理,归一化。 photo = np.transpose(np.array(image,dtype = np.float32)/255, (2, 0, 1)) with torch.no_grad(): images = torch.from_numpy(np.asarray([photo])) rpn_locs, rpn_scores, rois, roi_indices, anchor = frcnn_rpn(images,[height,width]) fig = plt.figure(dpi=200) ax = fig.add_subplot(111) ax.imshow(image) # 绘制RPN的结果 for i in range(rois.shape[0]): x1,y1,x2,y2 = rois[i] w,h = x2-x1,y2-y1 rect = plt.Rectangle([x1,y1],w,h,color="r",fill=False) ax.add_patch(rect) plt.xticks([]) plt.yticks([]) plt.show() print(anchor.shape) print(rois.shape)
fastrcnn网络结构复现 1.backbone-restnet50import math import torch.nn as nn class Bottleneck(nn.Module): expansion = 4 def __init__(self, inplanes, planes, stride=1, downsample=None): super(Bottleneck, self).__init__() self.conv1 = nn.Conv2d(inplanes, planes, kernel_size=1, stride=stride, bias=False) self.bn1 = nn.BatchNorm2d(planes) self.conv2 = nn.Conv2d(planes, planes, kernel_size=3, stride=1, padding=1, bias=False) self.bn2 = nn.BatchNorm2d(planes) self.conv3 = nn.Conv2d(planes, planes * 4, kernel_size=1, bias=False) self.bn3 = nn.BatchNorm2d(planes * 4) self.relu = nn.ReLU(inplace=True) self.downsample = downsample self.stride = stride def forward(self, x): residual = x out = self.conv1(x) out = self.bn1(out) out = self.relu(out) out = self.conv2(out) out = self.bn2(out) out = self.relu(out) out = self.conv3(out) out = self.bn3(out) if self.downsample is not None: residual = self.downsample(x) out += residual out = self.relu(out) return out class ResNet(nn.Module): def __init__(self, block, layers, num_classes=1000): #-----------------------------------# # 假设输入进来的图片是600,600,3 #-----------------------------------# self.inplanes = 64 super(ResNet, self).__init__() # 600,600,3 -> 300,300,64 self.conv1 = nn.Conv2d(3, 64, kernel_size=7, stride=2, padding=3, bias=False) self.bn1 = nn.BatchNorm2d(64) self.relu = nn.ReLU(inplace=True) # 300,300,64 -> 150,150,64 self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=0, ceil_mode=True) # 150,150,64 -> 150,150,256 self.layer1 = self._make_layer(block, 64, layers[0]) # 150,150,256 -> 75,75,512 self.layer2 = self._make_layer(block, 128, layers[1], stride=2) # 75,75,512 -> 38,38,1024 到这里可以获得一个38,38,1024的共享特征层 self.layer3 = self._make_layer(block, 256, layers[2], stride=2) # self.layer4被用在classifier模型中 self.layer4 = self._make_layer(block, 512, layers[3], stride=2) self.avgpool = nn.AvgPool2d(7) self.fc = nn.Linear(512 * block.expansion, num_classes) for m in self.modules(): if isinstance(m, nn.Conv2d): n = m.kernel_size[0] * m.kernel_size[1] * m.out_channels m.weight.data.normal_(0, math.sqrt(2. / n)) elif isinstance(m, nn.BatchNorm2d): m.weight.data.fill_(1) m.bias.data.zero_() def _make_layer(self, block, planes, blocks, stride=1): downsample = None #-------------------------------------------------------------------# # 当模型需要进行高和宽的压缩的时候,就需要用到残差边的downsample #-------------------------------------------------------------------# if stride != 1 or self.inplanes != planes * block.expansion: downsample = nn.Sequential( nn.Conv2d(self.inplanes, planes * block.expansion,kernel_size=1, stride=stride, bias=False), nn.BatchNorm2d(planes * block.expansion), ) layers = [] layers.append(block(self.inplanes, planes, stride, downsample)) self.inplanes = planes * block.expansion for i in range(1, blocks): layers.append(block(self.inplanes, planes)) return nn.Sequential(*layers) def forward(self, x): x = self.conv1(x) x = self.bn1(x) x = self.relu(x) x = self.maxpool(x) x = self.layer1(x) x = self.layer2(x) x = self.layer3(x) x = self.layer4(x) x = self.avgpool(x) x = x.view(x.size(0), -1) x = self.fc(x) return x def resnet50(): model = ResNet(Bottleneck, [3, 4, 6, 3]) #----------------------------------------------------------------------------# # 获取特征提取部分,从conv1到model.layer3,最终获得一个38,38,1024的特征层 #----------------------------------------------------------------------------# features = list([model.conv1, model.bn1, model.relu, model.maxpool, model.layer1, model.layer2, model.layer3]) #----------------------------------------------------------------------------# # 获取分类部分,从model.layer4到model.avgpool #----------------------------------------------------------------------------# classifier = list([model.layer4, model.avgpool]) features = nn.Sequential(*features) classifier = nn.Sequential(*classifier) return features, classifier extractor,classifier = resnet50() print(extractor)Sequential( (0): Conv2d(3, 64, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3), bias=False) (1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (2): ReLU(inplace=True) (3): MaxPool2d(kernel_size=3, stride=2, padding=0, dilation=1, ceil_mode=True) (4): Sequential( (0): Bottleneck( (conv1): Conv2d(64, 64, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (conv3): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn3): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (relu): ReLU(inplace=True) (downsample): Sequential( (0): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False) (1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) ) ) (1): Bottleneck( (conv1): Conv2d(256, 64, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (conv3): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn3): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (relu): ReLU(inplace=True) ) (2): Bottleneck( (conv1): Conv2d(256, 64, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (conv3): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn3): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (relu): ReLU(inplace=True) ) ) (5): Sequential( (0): Bottleneck( (conv1): Conv2d(256, 128, kernel_size=(1, 1), stride=(2, 2), bias=False) (bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (conv3): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn3): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (relu): ReLU(inplace=True) (downsample): Sequential( (0): Conv2d(256, 512, kernel_size=(1, 1), stride=(2, 2), bias=False) (1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) ) ) (1): Bottleneck( (conv1): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (conv3): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn3): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (relu): ReLU(inplace=True) ) (2): Bottleneck( (conv1): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (conv3): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn3): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (relu): ReLU(inplace=True) ) (3): Bottleneck( (conv1): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (conv3): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn3): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (relu): ReLU(inplace=True) ) ) (6): Sequential( (0): Bottleneck( (conv1): Conv2d(512, 256, kernel_size=(1, 1), stride=(2, 2), bias=False) (bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (relu): ReLU(inplace=True) (downsample): Sequential( (0): Conv2d(512, 1024, kernel_size=(1, 1), stride=(2, 2), bias=False) (1): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) ) ) (1): Bottleneck( (conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (relu): ReLU(inplace=True) ) (2): Bottleneck( (conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (relu): ReLU(inplace=True) ) (3): Bottleneck( (conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (relu): ReLU(inplace=True) ) (4): Bottleneck( (conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (relu): ReLU(inplace=True) ) (5): Bottleneck( (conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (relu): ReLU(inplace=True) ) ) )2.RPNimport numpy as np def generate_anchor_base(base_size=16, ratios=[0.5, 1, 2], anchor_scales=[8, 16, 32]): anchor_base = np.zeros((len(ratios) * len(anchor_scales), 4), dtype=np.float32) for i in range(len(ratios)): for j in range(len(anchor_scales)): h = base_size * anchor_scales[j] * np.sqrt(ratios[i]) w = base_size * anchor_scales[j] * np.sqrt(1. / ratios[i]) index = i * len(anchor_scales) + j anchor_base[index, 0] = - h / 2. anchor_base[index, 1] = - w / 2. anchor_base[index, 2] = h / 2. anchor_base[index, 3] = w / 2. return anchor_base # 产生特征图上每个点对应的9个base anchor def _enumerate_shifted_anchor(anchor_base, feat_stride, height, width): # 计算网格中心点 shift_x = np.arange(0, width * feat_stride, feat_stride) shift_y = np.arange(0, height * feat_stride, feat_stride) shift_x, shift_y = np.meshgrid(shift_x, shift_y) shift = np.stack((shift_x.ravel(),shift_y.ravel(), shift_x.ravel(),shift_y.ravel(),), axis=1) # 每个网格点上的9个先验框 A = anchor_base.shape[0] K = shift.shape[0] anchor = anchor_base.reshape((1, A, 4)) + \ shift.reshape((K, 1, 4)) # 所有的先验框 anchor = anchor.reshape((K * A, 4)).astype(np.float32) return anchor import matplotlib.pyplot as plt nine_anchors = generate_anchor_base() # 产生特征图上每个点对应的9个base anchor height, width, feat_stride = 38,38,16 # 特征图的shape feature_map_w,feature_map_h,feature_map_c = 38,38,16 # 生成整个特征图对应的所有的base anchor ,总计feature_map_w*feature_map_h*9个 anchors_all = _enumerate_shifted_anchor(nine_anchors,feat_stride,height,width) print(np.shape(anchors_all)) fig = plt.figure() ax = fig.add_subplot(111) plt.ylim(-300,900) plt.xlim(-300,900) # 模拟绘制特征提取之前的原图 shift_x = np.arange(0, width * feat_stride, feat_stride) shift_y = np.arange(0, height * feat_stride, feat_stride) shift_x, shift_y = np.meshgrid(shift_x, shift_y) plt.scatter(shift_x,shift_y) # 绘制特征图上像素点(pix_x,pix_y)对应原图的所有anchor pix_x,pix_y = 12,0 index_begin = pix_y*width*9 + pix_x*9 index_end = pix_y*width*9 + pix_x*9 + 9 print(index_begin) box_widths = anchors_all[:,2]-anchors_all[:,0] box_heights = anchors_all[:,3]-anchors_all[:,1] for i in range(index_begin,index_end): rect = plt.Rectangle([anchors_all[i, 0],anchors_all[i, 1]],box_widths[i],box_heights[i],color="r",fill=False) ax.add_patch(rect) plt.show()# 将RPN网络预测结果转化成建议框 def loc2bbox(src_bbox, loc): if src_bbox.size()[0] == 0: return torch.zeros((0, 4), dtype=loc.dtype) src_width = torch.unsqueeze(src_bbox[:, 2] - src_bbox[:, 0], -1) src_height = torch.unsqueeze(src_bbox[:, 3] - src_bbox[:, 1], -1) src_ctr_x = torch.unsqueeze(src_bbox[:, 0], -1) + 0.5 * src_width src_ctr_y = torch.unsqueeze(src_bbox[:, 1], -1) + 0.5 * src_height dx = loc[:, 0::4] dy = loc[:, 1::4] dw = loc[:, 2::4] dh = loc[:, 3::4] ctr_x = dx * src_width + src_ctr_x ctr_y = dy * src_height + src_ctr_y w = torch.exp(dw) * src_width h = torch.exp(dh) * src_height dst_bbox = torch.zeros_like(loc) dst_bbox[:, 0::4] = ctr_x - 0.5 * w dst_bbox[:, 1::4] = ctr_y - 0.5 * h dst_bbox[:, 2::4] = ctr_x + 0.5 * w dst_bbox[:, 3::4] = ctr_y + 0.5 * h return dst_bboxclass ProposalCreator(): def __init__(self, mode, nms_thresh=0.7, n_train_pre_nms=12000, n_train_post_nms=600, n_test_pre_nms=3000, n_test_post_nms=300, min_size=16): self.mode = mode self.nms_thresh = nms_thresh self.n_train_pre_nms = n_train_pre_nms self.n_train_post_nms = n_train_post_nms self.n_test_pre_nms = n_test_pre_nms self.n_test_post_nms = n_test_post_nms self.min_size = min_size def __call__(self, loc, score, anchor, img_size, scale=1.): if self.mode == "training": n_pre_nms = self.n_train_pre_nms n_post_nms = self.n_train_post_nms else: n_pre_nms = self.n_test_pre_nms n_post_nms = self.n_test_post_nms anchor = torch.from_numpy(anchor) if loc.is_cuda: anchor = anchor.cuda() #-----------------------------------# # 将RPN网络预测结果转化成建议框 #-----------------------------------# roi = loc2bbox(anchor, loc) #-----------------------------------# # 防止建议框超出图像边缘 #-----------------------------------# roi[:, [0, 2]] = torch.clamp(roi[:, [0, 2]], min = 0, max = img_size[1]) roi[:, [1, 3]] = torch.clamp(roi[:, [1, 3]], min = 0, max = img_size[0]) #-----------------------------------# # 建议框的宽高的最小值不可以小于16 #-----------------------------------# min_size = self.min_size * scale keep = torch.where(((roi[:, 2] - roi[:, 0]) >= min_size) & ((roi[:, 3] - roi[:, 1]) >= min_size))[0] roi = roi[keep, :] score = score[keep] #-----------------------------------# # 根据得分进行排序,取出建议框 #-----------------------------------# order = torch.argsort(score, descending=True) if n_pre_nms > 0: order = order[:n_pre_nms] roi = roi[order, :] score = score[order] #-----------------------------------# # 对建议框进行非极大抑制 #-----------------------------------# keep = nms(roi, score, self.nms_thresh) keep = keep[:n_post_nms] roi = roi[keep] return roi3.合并backbone与rpn--记为FRCNN_RPNclass FRCNN_RPN(nn.Module): def __init__(self,extractor,rpn): super(FRCNN_RPN, self).__init__() self.extractor = extractor self.rpn = rpn def forward(self, x, img_size): print(img_size) feature_map = self.extractor(x) rpn_locs, rpn_scores, rois, roi_indices, anchor = self.rpn(feature_map,img_size) return rpn_locs, rpn_scores, rois, roi_indices, anchor# 加载模型参数 param = torch.load("./frcnn-restnet50.pth") param.keys() rpn = RegionProposalNetwork(in_channels=1024,mode="predict") frcnn_rpn = FRCNN_RPN(extractor,rpn) frcnn_rpn_state_dict = frcnn_rpn.state_dict() for key in frcnn_rpn_state_dict.keys(): frcnn_rpn_state_dict[key] = param[key] frcnn_rpn.load_state_dict(frcnn_rpn_state_dict)from PIL import Image import copy def get_new_img_size(width, height, img_min_side=600): if width <= height: f = float(img_min_side) / width resized_height = int(f * height) resized_width = int(img_min_side) else: f = float(img_min_side) / height resized_width = int(f * width) resized_height = int(img_min_side) return resized_width, resized_height img_path = os.path.join("xx.jpg") image = Image.open(img_path) image = image.convert("RGB") # 转换成RGB图片,可以用于灰度图预测。 image_shape = np.array(np.shape(image)[0:2]) old_width, old_height = image_shape[1], image_shape[0] old_image = copy.deepcopy(image) # 给原图像进行resize,resize到短边为600的大小上 width,height = get_new_img_size(old_width, old_height) image = image.resize([width,height], Image.BICUBIC) print(image.size) # 图片预处理,归一化。 photo = np.transpose(np.array(image,dtype = np.float32)/255, (2, 0, 1)) with torch.no_grad(): images = torch.from_numpy(np.asarray([photo])) rpn_locs, rpn_scores, rois, roi_indices, anchor = frcnn_rpn(images,[height,width]) fig = plt.figure(dpi=200) ax = fig.add_subplot(111) ax.imshow(image) # 绘制RPN的结果 for i in range(rois.shape[0]): x1,y1,x2,y2 = rois[i] w,h = x2-x1,y2-y1 rect = plt.Rectangle([x1,y1],w,h,color="r",fill=False) ax.add_patch(rect) plt.xticks([]) plt.yticks([]) plt.show() print(anchor.shape) print(rois.shape) -
离线安装pytorch 离线安装pytorch针对网络不稳定在线安装总是中途失败的情况下采用离线安装的方式1.安装前准备1.1 安装显卡驱动略1.2 创建虚拟环境conda create -n torch1.9 python=3.8 conda activate torch1.92.离线安装2.1 版本对应关系2.2 离线下载安装包下载地址:download.pytorch.org/whl/torch_stable.html我们在这里可以找到我们需要的torch-1.9.0+cu111-cp38-cp38-linux_x86_64.whl以及torchvision-0.10.0+cu111-cp38-cp38-linux_x86_64.whl两个文件即可。注意,cu111代表CUDA11.1,cp38表示python3.8的编译环境,linux_x86_64表示x86的平台64位操作系统。下载完成后,我们将这两个文件传入你的离线主机(服务器)中。接着进入刚刚用conda创建好的虚拟环境后依次安装whl包:2.3 离线安装# CPU版 pip install torch-1.9.0+cpu-cp38-cp38-linux_x86_64.whl pip install torchvision-0.10.0+cpu-cp38-cp38-linux_x86_64.whl # GPU版 pip install torch-1.9.0+cu111-cp38-cp38-linux_x86_64.whl pip install torchvision-0.10.0+cu111-cp38-cp38-linux_x86_64.whl参考资料Pytorch1.9 CPU/GPU(CUDA11.1)安装_torch==1.9.0+cu111_太阳花的小绿豆的博客-CSDN博客
-
YOLOv5 四检测头配置 一、网络结构说明Yolov5原网络结构如下:增加一层检测层后,网络结构如下:(其中虚线表示删除的部分,细线表示增加的数据流动方向)二、网络配置第一步,在models文件夹下面创建yolov5s-add-one-layer.yaml文件。第二步,将下面的内容粘贴到新创建的文件中。# YOLOv5 by Ultralytics, GPL-3.0 license # Parameters nc: 2 # number of classes depth_multiple: 0.33 # model depth multiple width_multiple: 0.50 # layer channel multiple anchors: - [4,5, 8,10, 22,18] # P2/4 - [10,13, 16,30, 33,23] # P3/8 - [30,61, 62,45, 59,119] # P4/16 - [116,90, 156,198, 373,326] # P5/32 # YOLOv5 v6.0 backbone backbone: # [from, number, module, args] [[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2 [-1, 1, Conv, [128, 3, 2]], # 1-P2/4 [-1, 3, C3, [128]], [-1, 1, Conv, [256, 3, 2]], # 3-P3/8 [-1, 6, C3, [256]], [-1, 1, Conv, [512, 3, 2]], # 5-P4/16 [-1, 9, C3, [512]], [-1, 1, Conv, [1024, 3, 2]], # 7-P5/32 [-1, 3, C3, [1024]], [-1, 1, SPPF, [1024, 5]], # 9 ] # YOLOv5 v6.0 head head: [[-1, 1, Conv, [512, 1, 1]], [-1, 1, nn.Upsample, [None, 2, 'nearest']], [[-1, 6], 1, Concat, [1]], # cat backbone P4 [-1, 3, C3, [512, False]], # 13 [-1, 1, Conv, [256, 1, 1]], [-1, 1, nn.Upsample, [None, 2, 'nearest']], [[-1, 4], 1, Concat, [1]], # cat backbone P3 # add feature extration layer [-1, 3, C3, [256, False]], # 17 [-1, 1, Conv, [128, 1, 1]], [-1, 1, nn.Upsample, [None, 2, 'nearest']], [[-1, 2], 1, Concat, [1]], # cat backbone P3 # add detect layer [-1, 3, C3, [128, False]], # 21 (P4/4-minium) [-1, 1, Conv, [128, 3, 2]], [[-1, 18], 1, Concat, [1]], # cat head P3 # end [-1, 3, C3, [256, False]], # 24 (P3/8-small) [-1, 1, Conv, [256, 3, 2]], [[-1, 14], 1, Concat, [1]], # cat head P4 [-1, 3, C3, [512, False]], # 27 (P4/16-medium) [-1, 1, Conv, [512, 3, 2]], [[-1, 10], 1, Concat, [1]], # cat head P5 [-1, 3, C3, [1024, False]], # 30 (P5/32-large) [[21, 24, 27, 30], 1, Detect, [nc, anchors]], # Detect(P2, P3, P4, P5) ]第三步,正常执行新模型的训练流程,参考:快速使用YOLOv5进行训练VOC格式的数据集 - jupiter's blog (inat.top)。参考资料【Yolov5】Yolov5添加检测层,四层结构对小目标、密集场景更友好_yolov5增加小目标检测层-CSDN博客
-
[目标检测模型辅助数据标注]YOLOv5检测图片并将结果转为voc的xml格式 1.调用YOLOv5检测模型对图片文件夹执行检测并保存txt和confpython detect.py --weight runs\train\exp3\weights\best.pt --source [待检测的图片文件夹]--save-txt --save-conf2.将检测结果转为voc的xml格式import os import copy from xml.dom import minidom from tqdm import tqdm import cv2 import xmltodict # 图片\YOLO txt\xml对应的文件夹地址 base_dir = "[上面的待检测的图片文件夹]" img_dir = os.path.join(base_dir,"img") txt_dir = os.path.join(base_dir,"labels") xml_dir = os.path.join(base_dir,"xml") class_name_list = "YOLO项目中data.yaml的class_names" obj_base = { 'name':'name', 'bndbox':{ 'xmin':1, 'ymin':1, 'xmax':1, 'ymax':1 } } xml_base = { 'annotation': { 'folder':'img', 'filename':'', 'size':{ 'width':1, 'height':1, 'depth':3 }, 'object':[] } } img_name_list = os.listdir(img_dir) pbar = tqdm(total=len(img_name_list)) pbar.set_description("YOLOTXT2VOC:") for i in range(len(img_name_list)): # 拼接对应文件的地址 img_name = img_name_list[i] img_path = os.path.join(img_dir,img_name) txt_path = os.path.join(txt_dir,img_name.split(".")[0]+".txt") xml_path = os.path.join(xml_dir,img_name.split(".")[0]+".xml") # 初始化xml文件对象 xml_tmp = copy.deepcopy(xml_base) xml_tmp['annotation']['filename'] = img_name # 读取图片对应的宽高信息 img = cv2.imread(img_path) img_height,img_width = img.shape[:2] # 读取txt文件内容 with open(txt_path,'r') as f: content = f.read() # 逐行解析txt内容 for line in content.split("\n"): if not line:continue data_item_list = line.split(" ") # 跳过类别置信度小于0.5的 conf = float(data_item_list[5]) if(conf<0.5):continue # 单行txt转为xml中对应的obj obj_tmp = copy.deepcopy(obj_base) obj_tmp["name"] = class_name_list[int(data_item_list[0])] x_center = int(float(data_item_list[1])*img_width) y_center = int(float(data_item_list[2])*img_height) width = int(float(data_item_list[3])*img_width) height = int(float(data_item_list[4])*img_height) obj_tmp["bndbox"]["xmin"] = int(x_center-width/2.0) obj_tmp["bndbox"]["ymin"] = int(y_center-height/2.0) obj_tmp["bndbox"]["xmax"] = width + obj_tmp["bndbox"]["xmin"] obj_tmp["bndbox"]["ymax"] = height + obj_tmp["bndbox"]["ymin"] xml_tmp['annotation']['object'].append(obj_tmp) # 转为xml并写入对应文件 xmlstr = xmltodict.unparse(xml_tmp) xml = minidom.parseString(xmlstr) xml_pretty_str = xml.toprettyxml() with open(xml_path,"w") as f: f.write(xml_pretty_str) pbar.update(1) pbar.close()
-
[视频目标检测]:使用MEGA|DFF|FGFA训练自己的数据集 1.创建环境创建虚拟环境conda create --name MEGA -y python=3.7 source activate MEGA安装基础包conda install ipython pip pip install ninja yacs cython matplotlib tqdm opencv-python scipy export INSTALL_DIR=$PWD安装pytorch在安装pytorch的时候,原作者是这样的:conda install pytorch=1.3.0 torchvision cudatoolkit=10.0 -c pytorch但实际上使用cuda11.0+pytorch1.7也可以编译跑通,所以在这一步我们将其替换成:conda install pytorch==1.7.0 torchvision==0.8.0 torchaudio==0.7.0 cudatoolkit=11.0 -c pytorch然后就是作者使用到的coco数据集和cityperson数据集的安装:cd $INSTALL_DIR git clone https://github.com/cocodataset/cocoapi.git cd cocoapi/PythonAPId python setup.py build_ext install cd $INSTALL_DIR git clone https://github.com/mcordts/cityscapesScripts.git cd cityscapesScripts/ python setup.py build_ext install安装apex:(可省略) (建议省略,没省略运行报错)git clone https://github.com/NVIDIA/apex.git cd apex python setup.py install --cuda_ext --cpp_ext如果使用的是cuda11.0+pytorch1.7这里会报错deform_conv_cuda.cu(155): error: identifier "AT_CHECK " is undefined解决:在mega_core/csrc/cuda/deform_conv_cuda.cu 和 mega_core/csrc/cuda/deform_pool_cuda.cu文件的开头加上如下代码:#ifndef AT_CHECK #define AT_CHECK TORCH_CHECK #endif实际上原作者并没有使用到apex来进行混合精度训练,这一步也可省略,若省略的话在代码中需要修改几处地方:首先是mega_core/engine/trainer.py中的开头导入apex包注释掉,108-109行改为:losses.backward()还有tools/train_net.py中33行-36行注释掉# try: # from apex import amp # except ImportError: # raise ImportError('Use APEX for multi-precision via apex.amp') 50行也注释掉:#model, optimizer = amp.initialize(model, optimizer, opt_level=amp_opt_level)还有mega_core/layers/nms.py,注释掉第5行第8行改为:nms = _C.nms还有mega_core/layers/roi_align.py注释掉第10、57行还有mega_core/layers/roi_pool.py注释掉第10、56行这样应该就可以了。2.下载和初始化mega.pytorch# install PyTorch Detection cd $INSTALL_DIR git clone https://github.com/Scalsol/mega.pytorch.git cd mega.pytorch # the following will install the lib with # symbolic links, so that you can modify # the files if you want and won't need to # re-build it python setup.py build develop pip install 'pillow<7.0.0'3.制作自己的数据集参考作者提供的customize.md文件3.1 数据集格式参考:https://github.com/Scalsol/mega.pytorch/blob/master/CUSTOMIZE.md【注意事项】1.图片编号是从0开始的6位数字;(不想实现自己的数据加载器这是必要的)2.annotation内的xml文件与train、val钟文件一一对应。datasets ├── vid_custom | |── train | | |── video_snippet_1 | | | |── 000000.JPEG | | | |── 000001.JPEG | | | |── 000002.JPEG | | | ... | | |── video_snippet_2 | | | |── 000000.JPEG | | | |── 000001.JPEG | | | |── 000002.JPEG | | | ... | | ... | |── val | | |── video_snippet_1 | | | |── 000000.JPEG | | | |── 000001.JPEG | | | |── 000002.JPEG | | | ... | | |── video_snippet_2 | | | |── 000000.JPEG | | | |── 000001.JPEG | | | |── 000002.JPEG | | | ... | | ... | |── annotation | | |── train | | | |── video_snippet_1 | | | | |── 000000.xml | | | | |── 000001.xml | | | | |── 000002.xml | | | | ... | | | |── video_snippet_2 | | | | |── 000000.xml | | | | |── 000001.xml | | | | |── 000002.xml | | | | ... | | ... | | |── val | | | |── video_snippet_1 | | | | |── 000000.xml | | | | |── 000001.xml | | | | |── 000002.xml | | | | ... | | | |── video_snippet_2 | | | | |── 000000.xml | | | | |── 000001.xml | | | | |── 000002.xml | | | | ... | | ...3.2 准备自己txt文件具体参考源MEGA代码中datasets\ILSVRC2015\ImageSets提供的文档。格式:每一行4列依次代表:video folder, no meaning(just ignore it),frame number,video length;训练集VID_train.txt 对应vid_custom/train文件夹train/ILSVRC2015_VID_train_0000/ILSVRC2015_train_00000000 1 10 300 train/ILSVRC2015_VID_train_0000/ILSVRC2015_train_00000000 1 30 300 train/ILSVRC2015_VID_train_0000/ILSVRC2015_train_00000000 1 50 300 train/ILSVRC2015_VID_train_0000/ILSVRC2015_train_00000000 1 70 300 train/ILSVRC2015_VID_train_0000/ILSVRC2015_train_00000000 1 90 300 train/ILSVRC2015_VID_train_0000/ILSVRC2015_train_00000000 1 110 300 train/ILSVRC2015_VID_train_0000/ILSVRC2015_train_00000000 1 130 300 train/ILSVRC2015_VID_train_0000/ILSVRC2015_train_00000000 1 150 300 train/ILSVRC2015_VID_train_0000/ILSVRC2015_train_00000000 1 170 300 train/ILSVRC2015_VID_train_0000/ILSVRC2015_train_00000000 1 190 300 train/ILSVRC2015_VID_train_0000/ILSVRC2015_train_00000000 1 210 300 train/ILSVRC2015_VID_train_0000/ILSVRC2015_train_00000000 1 230 300 train/ILSVRC2015_VID_train_0000/ILSVRC2015_train_00000000 1 250 300 train/ILSVRC2015_VID_train_0000/ILSVRC2015_train_00000000 1 270 300 train/ILSVRC2015_VID_train_0000/ILSVRC2015_train_00000000 1 290 300 train/ILSVRC2015_VID_train_0000/ILSVRC2015_train_00001000 1 1 48 train/ILSVRC2015_VID_train_0000/ILSVRC2015_train_00001000 1 4 48 train/ILSVRC2015_VID_train_0000/ILSVRC2015_train_00001000 1 8 48 ···验证集VID_val.txt 对应vid_custom/val文件夹val/ILSVRC2015_val_00000000 1 0 464 val/ILSVRC2015_val_00000000 2 1 464 val/ILSVRC2015_val_00000000 3 2 464 val/ILSVRC2015_val_00000000 4 3 464 val/ILSVRC2015_val_00000000 5 4 464 val/ILSVRC2015_val_00000000 6 5 464 val/ILSVRC2015_val_00000000 7 6 464 val/ILSVRC2015_val_00000000 8 7 464 val/ILSVRC2015_val_00000000 9 8 464 val/ILSVRC2015_val_00000000 10 9 464 val/ILSVRC2015_val_00000000 11 10 464 val/ILSVRC2015_val_00000000 12 11 464 val/ILSVRC2015_val_00000000 13 12 464 val/ILSVRC2015_val_00000000 14 13 464 val/ILSVRC2015_val_00000000 15 14 464 val/ILSVRC2015_val_00000000 16 15 464 ···4.参数修改mega_core/data/datasets/vid.py修改VIDDataset内classes和classes_map:# classes=['__background__',#always index0 'car'] # classes_map=['__background__',# always index0 'n02958343'] # 自己标的数据集两个都填一样的就行 classes = ['__background__', # always index 0 'BridgeVehicle', 'Person', 'FollowMe', 'Plane', 'LuggageTruck', 'RefuelingTruck', 'FoodTruck', 'Tractor'] classes_map = ['__background__', # always index 0 'BridgeVehicle', 'Person', 'FollowMe', 'Plane', 'LuggageTruck', 'RefuelingTruck', 'FoodTruck', 'Tractor']mega_core/config/paths_catalog.py修改 DatasetCatalog.DATASETS,在变量的最后加上如下内容"vid_custom_train":{ "img_dir":"vid_custom/train", "anno_path":"vid_custom/annotation", "img_index":"vid_custom/VID_train.txt" }, "vid_custom_val":{ "img_dir":"vid_custom/val", "anno_path":"vid_custom/annotation", "img_index":"vid_custom/VID_val.txt" }修改if函数下if语句,添加上vid条件if ("DET" in name) or ("VID" in name) or ("vid" in name):修改configs/BASE_RCNN_1gpu.yaml(取决于你用几张gpu训练)NUM_CLASSES: 9#(物体类别数+背景) TRAIN: ("vid_custom_train",)#记得加“,” TEST: ("vid_custom_val",)#记得加“,”修改configs/MEGA/vid_R_101_C4_MEGA_1x.yamlDATASETS: TRAIN: ("vid_custom_train",)#记得加“,” TEST: ("vid_custom_val",)#记得加“,”5.训练和测试代码5.1 开始训练python -m torch.distributed.launch \ --nproc_per_node=1 \ tools/train_net.py \ --master_port=$((RANDOM + 10000)) \ --config-file configs/BASE_RCNN_1gpu.yaml \ OUTPUT_DIR training_dir/BASE_RCNNpython -m torch.distributed.launch \ --nproc_per_node=1 \ tools/train_net.py \ --master_port=$((RANDOM + 10000)) \ --config-file configs/DFF/vid_R_50_C4_DFF_1x.yaml \ OUTPUT_DIR training_dir/vid_R_50_C4_DFF_1x5.2 开始测试python -m torch.distributed.launch \ --nproc_per_node 1 \ tools/test_net.py \ --config-file configs/BASE_RCNN_1gpu.yaml \ MODEL.WEIGHT training_dir/BASE_RCNN/model_0020000.pth python tools/test_prediction.py \ --config-file configs/BASE_RCNN_1gpu.yaml \ --prediction ./ 参考资料MEGA训练自己的数据集-dockerhttps://github.com/Scalsol/mega.pytorch/issues/63
-
快速使用mobiledets-yolov4 1.下载项目git clone https://github.com/inacmor/mobiledets-yolov4-pytorch.git2.准备数据2.1 准备VOC格式的数据集put your trainset and labels(xml) in data/Imgs and data/Annotations.这里选择直接将一个VOC格式的数据集通过软链接链接过来ln -s /data_jupiter/dataset/209_VOC_new/Annotations ./ ln -s /data_jupiter/dataset/209_VOC_new/JPEGImages ./Imgs 2.2 修改classes.txtLuggageVehicle BridgeVehicle Plane RefuelVehicle Person FoodVehicle LuggageVehicleHead FollowMe TractorVehicle3.开始训练3.0 环境安装安装pytorch(略)安装apexgit clone https://github.com/NVIDIA/apex cd apex python setup.py install3.1 训练前准备工作python ready.py python kmeans.py3.2 开始训练没有预训练模型的话需要将模型加载注释掉,修改train.py#model.load_state_dict(torch.load(pretrained_weights), strict=False)# 执行训练 python train.py
-
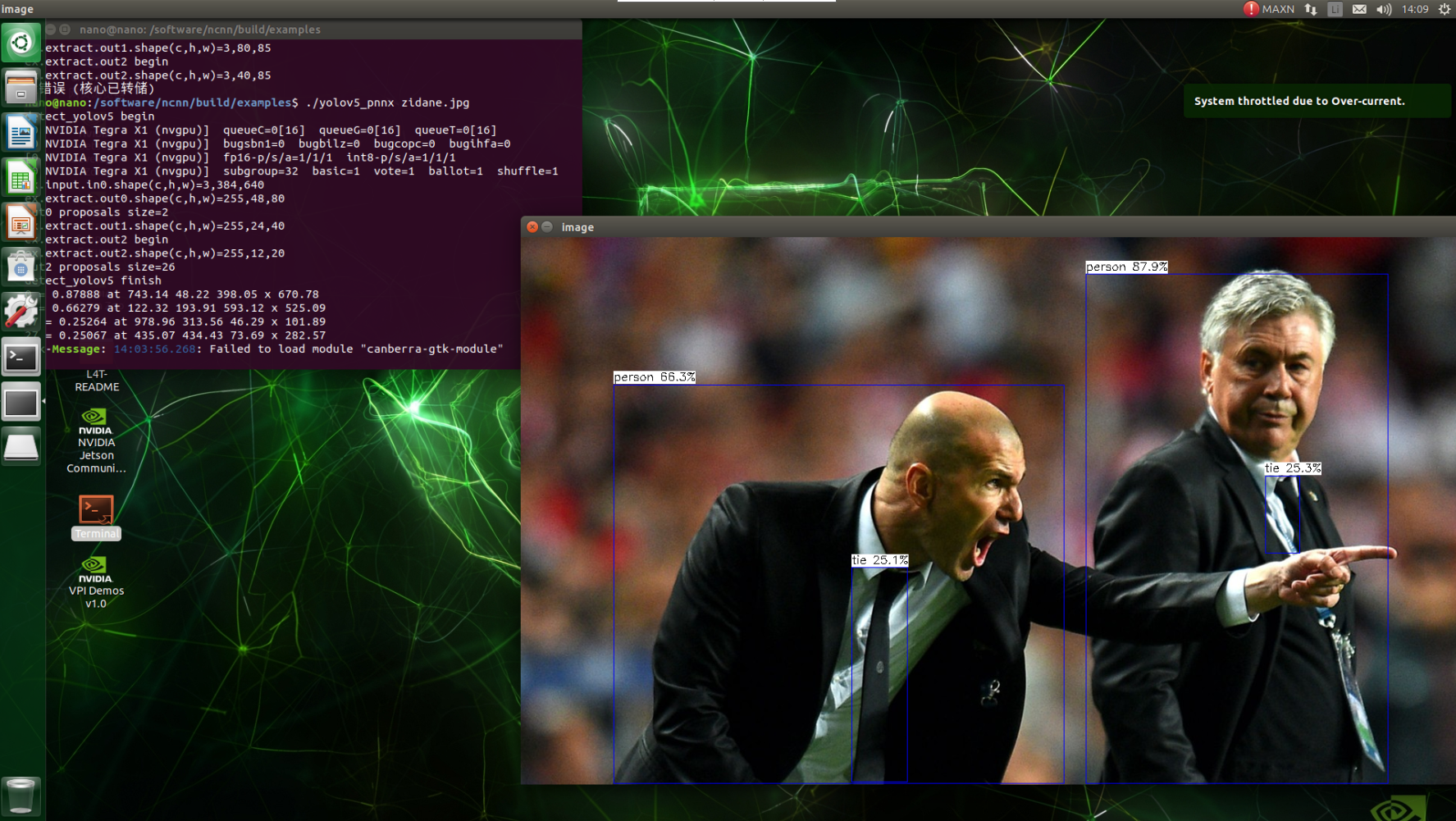
NCNN部署yolov5s 1.NCNN编译安装参考:Linux下如何安装ncnn2.模型转换(pt->onnx->ncnn)$\color{red}{此路不通,转出来的param文件中的Reshape的参数是错的}$2.1 pt模型转换onnx# pt-->onnx python export.py --weights yolov5s.pt --img 640 --batch 1#安装onnx-simplifier pip install onnx-simplifier # onnxsim 精简模型 python -m onnxsim yolov5s.onnx yolov5s-sim.onnx Simplifying... Finish! Here is the difference: ┏━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━┓ ┃ ┃ Original Model ┃ Simplified Model ┃ ┡━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━┩ │ Add │ 10 │ 10 │ │ Concat │ 17 │ 17 │ │ Constant │ 20 │ 0 │ │ Conv │ 60 │ 60 │ │ MaxPool │ 3 │ 3 │ │ Mul │ 69 │ 69 │ │ Pow │ 3 │ 3 │ │ Reshape │ 6 │ 6 │ │ Resize │ 2 │ 2 │ │ Sigmoid │ 60 │ 60 │ │ Split │ 3 │ 3 │ │ Transpose │ 3 │ 3 │ │ Model Size │ 28.0MiB │ 28.0MiB │ └────────────┴────────────────┴──────────────────┘2.2 使用onnx2ncnn.exe 转换模型把你的ncnn/build/tools/onnx加入到环境变量onnx2ncnn yolov5s-sim.onnx yolov5s_6.0.param yolov5s_6.0.bin2.3 调用测试将yolov5s_6.0.param 、yolov5s_6.0.bin模型copy到ncnn/build/examples/位置,运行下面命令./yolov5 image-path就会出现Segmentation fault (core dumped)的报错3.模型转换(pt->torchscript->ncnn)3.1 pt模型转换torchscript# pt-->torchscript python export.py --weights yolov5s.pt --include torchscript --train3.2 下载编译好的 pnnx 工具包执行转换pnnx下载地址:https://github.com/pnnx/pnnx执行转换,获得 yolov5s.ncnn.param 和 yolov5s.ncnn.bin 模型文件,指定 inputshape 并且额外指定 inputshape2 转换成支持动态 shape 输入的模型 ./pnnx yolov5s.torchscript inputshape=[1,3,640,640] inputshape2=[1,3,320,320]3.3 调用测试直接测试的相关文件下载:yolov5_pnnx.zip将 yolov5s.ncnn.param 和 yolov5s.ncnn.bin 模型copy到ncnn/build/examples/位置,运行下面命令./yolov5_pnnx image-path参考资料yolov5 模型部署NCNN(详细过程)Linux&Jetson Nano下编译安装ncnnYOLOv5转NCNN过程Jetson Nano 移植ncnn详细记录u版YOLOv5目标检测ncnn实现(第二版)
-
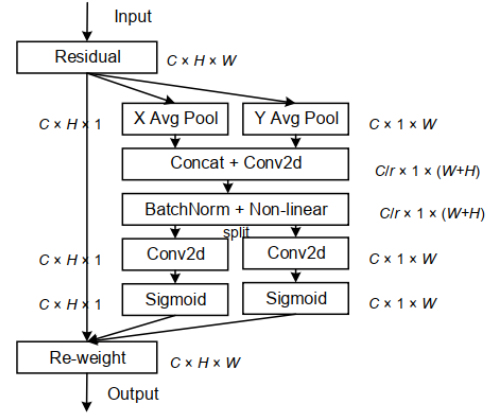
YOLOV5 加入注意力机制(以CA注意力机制为例) 0.CA注意力机制网络结构图1.在common.py中先添加你想添加的注意力模块### 常用注意力机制模块实现 class h_sigmoid(nn.Module): def __init__(self, inplace=True): super(h_sigmoid, self).__init__() self.relu = nn.ReLU6(inplace=inplace) def forward(self, x): return self.relu(x + 3) / 6 class h_swish(nn.Module): def __init__(self, inplace=True): super(h_swish, self).__init__() self.sigmoid = h_sigmoid(inplace=inplace) def forward(self, x): return x * self.sigmoid(x) class CoordAtt(nn.Module): def __init__(self, inp, oup, reduction=32): super(CoordAtt, self).__init__() self.pool_h = nn.AdaptiveAvgPool2d((None, 1)) self.pool_w = nn.AdaptiveAvgPool2d((1, None)) mip = max(8, inp // reduction) self.conv1 = nn.Conv2d(inp, mip, kernel_size=1, stride=1, padding=0) self.bn1 = nn.BatchNorm2d(mip) self.act = h_swish() self.conv_h = nn.Conv2d(mip, oup, kernel_size=1, stride=1, padding=0) self.conv_w = nn.Conv2d(mip, oup, kernel_size=1, stride=1, padding=0) def forward(self, x): identity = x n, c, h, w = x.size() x_h = self.pool_h(x) x_w = self.pool_w(x).permute(0, 1, 3, 2) y = torch.cat([x_h, x_w], dim=2) y = self.conv1(y) y = self.bn1(y) y = self.act(y) x_h, x_w = torch.split(y, [h, w], dim=2) x_w = x_w.permute(0, 1, 3, 2) a_h = self.conv_h(x_h).sigmoid() a_w = self.conv_w(x_w).sigmoid() out = identity * a_w * a_h return out class SELayer(nn.Module): def __init__(self, c1, r=16): super(SELayer, self).__init__() self.avgpool = nn.AdaptiveAvgPool2d(1) self.l1 = nn.Linear(c1, c1 // r, bias=False) self.relu = nn.ReLU(inplace=True) self.l2 = nn.Linear(c1 // r, c1, bias=False) self.sig = nn.Sigmoid() def forward(self, x): b, c, _, _ = x.size() y = self.avgpool(x).view(b, c) y = self.l1(y) y = self.relu(y) y = self.l2(y) y = self.sig(y) y = y.view(b, c, 1, 1) return x * y.expand_as(x) class eca_layer(nn.Module): """Constructs a ECA module. Args: channel: Number of channels of the input feature map k_size: Adaptive selection of kernel size """ def __init__(self, channel, k_size=3): super(eca_layer, self).__init__() self.avg_pool = nn.AdaptiveAvgPool2d(1) self.conv = nn.Conv1d(1, 1, kernel_size=k_size, padding=(k_size - 1) // 2, bias=False) self.sigmoid = nn.Sigmoid() def forward(self, x): # feature descriptor on the global spatial information y = self.avg_pool(x) # Two different branches of ECA module y = self.conv(y.squeeze(-1).transpose(-1, -2)).transpose(-1, -2).unsqueeze(-1) # Multi-scale information fusion y = self.sigmoid(y) x = x * y.expand_as(x) return x * y.expand_as(x) class ChannelAttention(nn.Module): def __init__(self, in_planes, ratio=16): super(ChannelAttention, self).__init__() self.avg_pool = nn.AdaptiveAvgPool2d(1) self.max_pool = nn.AdaptiveMaxPool2d(1) self.f1 = nn.Conv2d(in_planes, in_planes // ratio, 1, bias=False) self.relu = nn.ReLU() self.f2 = nn.Conv2d(in_planes // ratio, in_planes, 1, bias=False) # 写法二,亦可使用顺序容器 # self.sharedMLP = nn.Sequential( # nn.Conv2d(in_planes, in_planes // ratio, 1, bias=False), nn.ReLU(), # nn.Conv2d(in_planes // rotio, in_planes, 1, bias=False)) self.sigmoid = nn.Sigmoid() def forward(self, x): avg_out = self.f2(self.relu(self.f1(self.avg_pool(x)))) max_out = self.f2(self.relu(self.f1(self.max_pool(x)))) out = self.sigmoid(avg_out + max_out) return out class SpatialAttention(nn.Module): def __init__(self, kernel_size=7): super(SpatialAttention, self).__init__() assert kernel_size in (3, 7), 'kernel size must be 3 or 7' padding = 3 if kernel_size == 7 else 1 self.conv = nn.Conv2d(2, 1, kernel_size, padding=padding, bias=False) self.sigmoid = nn.Sigmoid() def forward(self, x): avg_out = torch.mean(x, dim=1, keepdim=True) max_out, _ = torch.max(x, dim=1, keepdim=True) x = torch.cat([avg_out, max_out], dim=1) x = self.conv(x) return self.sigmoid(x) class CBAMC3(nn.Module): # CSP Bottleneck with 3 convolutions def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5): # ch_in, ch_out, number, shortcut, groups, expansion super(CBAMC3, self).__init__() c_ = int(c2 * e) # hidden channels self.cv1 = Conv(c1, c_, 1, 1) self.cv2 = Conv(c1, c_, 1, 1) self.cv3 = Conv(2 * c_, c2, 1) self.m = nn.Sequential(*[Bottleneck(c_, c_, shortcut, g, e=1.0) for _ in range(n)]) self.channel_attention = ChannelAttention(c2, 16) self.spatial_attention = SpatialAttention(7) # self.m = nn.Sequential(*[CrossConv(c_, c_, 3, 1, g, 1.0, shortcut) for _ in range(n)]) def forward(self, x): out = self.channel_attention(x) * x print('outchannels:{}'.format(out.shape)) out = self.spatial_attention(out) * out return out 2.修改yolo.py在def parse_model(d, ch):函数的代码中增加你想添加的注意力名称添加前 if m in [Conv, GhostConv, Bottleneck, GhostBottleneck, SPP, SPPF, DWConv, MixConv2d, Focus, CrossConv, BottleneckCSP, C3, C3TR, C3SPP, C3Ghost]: c1, c2 = ch[f], args[0] if c2 != no: # if not output c2 = make_divisible(c2 * gw, 8)添加后 if m in [Conv, GhostConv, Bottleneck, GhostBottleneck, SPP, SPPF, DWConv, MixConv2d, Focus, CrossConv, BottleneckCSP, C3, C3TR, C3SPP, C3Ghost, CoordAtt]: c1, c2 = ch[f], args[0] if c2 != no: # if not output c2 = make_divisible(c2 * gw, 8)3.修改yaml文件/创建自定义的yaml文件示例-yolov5s-CA.yaml
-
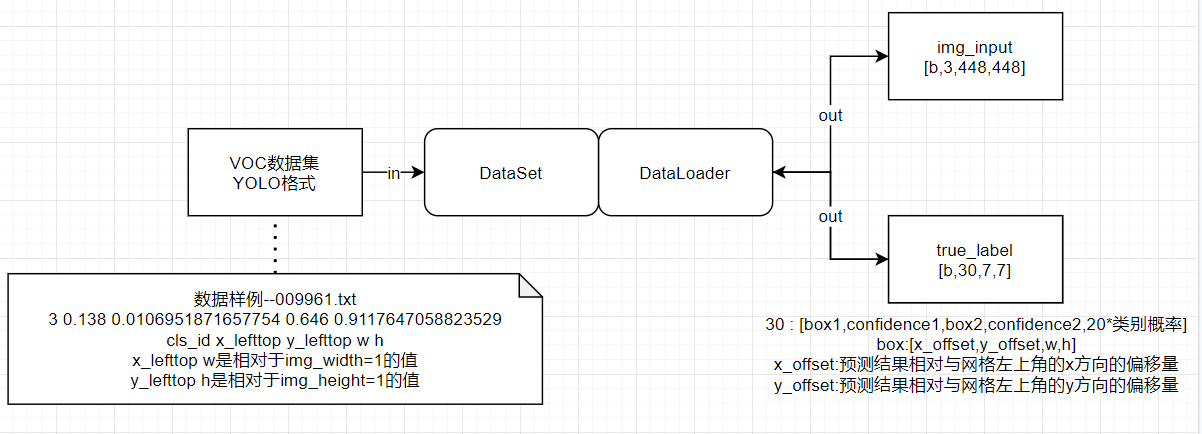
YOLOv1论文复现 一.整理结构概览1.数据格式转换部分2.DataSet,DateLoader部分2.1 主模块2.2 DataSet辅助模块--boxs2yololabel将单个图片中yolo格式的所有box转为yolov1网络模型所需要的label3.YOLOv1网络部分4.YOLOv1损失函数部分二.对每部分逐一进行实现1.数据格式转换部分--VOC2YOLO.py模块封装import xmltodict import os from progressbar import * """ 将单个xml文件中的单个object转换为yolov1格式 """ def get_yolo_data(obj,img_width,img_height): # 获取voc格式的数据信息 name = obj['name'] xmin = float(obj['bndbox']['xmin']) xmax = float(obj['bndbox']['xmax']) ymin = float(obj['bndbox']['ymin']) ymax = float(obj['bndbox']['ymax']) # 计算对应的yolo格式的数据信息,并进行归一化处理 class_idx = class_names.index(name) x_lefttop = xmin / img_width y_lefttop = ymin / img_height box_width = (xmax - xmin) / img_width box_height = (ymax - ymin) / img_height # 组转YOLO格式的数据 yolo_data = "{} {} {} {} {}\n".format(class_idx,x_lefttop,y_lefttop,box_width,box_height) return yolo_data """ 逐一处理xml文件,转换为YOLO所需的格式 + input + voc_xml_dir:VOC数据集的所有xml文件存储的文件夹 + yolo_txt_dir:转化完成后的YOLOv1格式数据的存储文件夹 + class_names:涉及的所有的类别 + output + yolo_txt_dir文件夹下的文件中的对应每张图片的YOLO格式的数据 """ def VOC2YOLOv1(voc_xml_dir,yolo_txt_dir,class_names): #进度条支持 count = 0 #计数器 widgets = ['VOC2YOLO: ',Percentage(), ' ', Bar('#'),' ', Timer(),' ', ETA()] pbar = ProgressBar(widgets=widgets, maxval=len(os.listdir(xml_dir))).start() # 对xml文件进行逐一处理 for xml_file in os.listdir(xml_dir): # 路径组装 xml_file_path = os.path.join(xml_dir,xml_file) txt_file_path = os.path.join(txt_dir,xml_file[:-4]+".txt") yolo_data = "" # 读取xml文件 with open(xml_file_path) as f: xml_str = f.read() # 转为字典 xml_dic = xmltodict.parse(xml_str) # 获取图片的width、height img_width = float(xml_dic["annotation"]["size"]["width"]) img_height = float(xml_dic["annotation"]["size"]["height"]) # 获取xml文件中的所有object objects = xml_dic["annotation"]["object"] # 对所有的object进行逐一处理 if isinstance(objects,list): # xml文件中包含多个object for obj in objects: yolo_data += get_yolo_data(obj,img_width,img_height) else: # xml文件中包含1个object obj = objects yolo_data += get_yolo_data(obj,img_width,img_height) # 将图片对应的yolo格式的数据写入到对应的文件 with open(txt_file_path,'w') as f: f.write(yolo_data) #更新进度 count += 1 pbar.update(count) pbar.finish() # 释放进度条调用测试voc_xml_dir='../VOC2007/Annotations/' #原xml路径 yolo_txt_dir='../VOC2007/labels/' #转换后txt文件存放路径 # 所有待检测的labels class_names = ['aeroplane', 'cat', 'car', 'dog', 'chair', 'person', 'horse', 'bird', 'tvmonitor', 'bus', 'boat', 'diningtable', 'bicycle', 'bottle', 'sofa', 'pottedplant', 'motorbike', 'cow', 'train', 'sheep'] VOC2YOLOv1(voc_xml_dir,yolo_txt_dir,class_names)VOC2YOLO: 100% |##########################| Elapsed Time: 0:01:18 Time: 0:01:182.DataSet,DateLoader部分模块封装from torch.utils.data import Dataset,DataLoader from PIL import Image """ 构建YOLOv1的dataset,用于加载VOC数据集(已对其进行了YOLO格式转换) + input + mode:调用模式,train/val + DATASET_PATH:VOC数据集的根目录,已对其进行了YOLO格式转换 + yolo_input_size:训练和测试所用的图片大小,通常为448 """ class Dataset_VOC(Dataset): def __init__(self,mode = "train",DATASET_PATH = "../VOC2007/",yolo_input_size = 448): self.filenames = [] # 储存数据集的文件名称 # 获取数据集的文件夹列表 if mode == "train": with open(DATASET_PATH + "ImageSets/Main/train.txt", 'r') as f: # 调用包含训练集图像名称的txt文件 self.filenames = [x.strip() for x in f] elif mode =='val': with open(DATASET_PATH + "ImageSets/Main/val.txt", 'r') as f: # 调用包含训练集图像名称的txt文件 self.filenames = [x.strip() for x in f] # 图像文件所在的文件夹 self.img_dir = os.path.join(DATASET_PATH,"JPEGImages") # 图像对应的label文件(.txt文件)的文件夹 self.label_dir = os.path.join(DATASET_PATH,"labels") def boxs2yololabel(self,boxs): """ 将boxs数据转换为训练时方便计算Loss的数据形式(7,7,5*B+cls_num) 单个box数据格式:(cls,x_rela_width,y_rela_height,w_rela_width,h_rela_height) x_rela_width:相对width=1的x的取值 """ gridsize = 1.0/7 # 网格大小 # 初始化result,此处需要根据不同数据集的类别个数进行修改 label = np.zeros((7,7,30)) # 根据box的数据填充label for i in range(len(boxs)//5): # 计算当前box会位于哪个网格 gridx = int(boxs[i*5+1] // gridsize) # 当前bbox中心落在第gridx个网格,列 gridy = int(boxs[i*5+2] // gridsize) # 当前bbox中心落在第gridy个网格,行 # 计算box相对于网格的左上角的点的相对位置 # box中心坐标 - 网格左上角点的坐标)/网格大小 ==> box中心点的相对位置 x_offset = boxs[i*5+1] / gridsize - gridx y_offset = boxs[i*5+2] / gridsize - gridy # 将第gridy行,gridx列的网格设置为负责当前ground truth的预测,置信度和对应类别概率均置为1 label[gridy, gridx, 0:5] = np.array([x_offset, y_offset, boxs[i*5+3], boxs[i*5+4], 1]) label[gridy, gridx, 5:10] = np.array([x_offset, y_offset, boxs[i*5+3], boxs[i*5+4], 1]) label[gridy, gridx, 10+int(boxs[i*5])] = 1 return label def __len__(self): return len(self.filenames) def __getitem__(self, index): # 构建image部分 # 读取图片 img_path = os.path.join(self.img_dir,self.filenames[index]+".jpg") img = cv2.imread(img_path) # 计算padding值将图像padding为正方形 h,w = img.shape[0:2] padw,padh = 0,0 if h>w: padw = (h - w) // 2 img = np.pad(img,((0,0),(padw,padw),(0,0)),'constant',constant_values=0) elif w>h: padh = (w - h) // 2 img = np.pad(img,((padh,padh),(0,0),(0,0)), 'constant', constant_values=0) # 然后resize为yolo网络所需要的尺寸448x448 yolo_input_size = 448 # 输入YOLOv1网络的图像尺寸为448x448 img = cv2.resize(img,(yolo_input_size,yolo_input_size)) # 构建label部分 # 读取图像对应的box信息,按1维的方式储存,每5个元素表示一个bbox的(cls_id,x_lefttop,y_lefttop,w,h) label_path = os.path.join(self.label_dir,self.filenames[index]+".txt") with open(label_path) as f: boxs = f.read().split('\n') boxs = [x.split() for x in boxs] boxs = [float(x) for y in boxs for x in y] # 根据padding、图像增广等操作,将原始的box数据转换为修改后图像的box数据 for i in range(len(boxs)//5): if padw != 0: boxs[i*5+1] = (boxs[i*5+1] * w + padw) / h boxs[i*5+3] = (boxs[i*5+3] * w) / h elif padh != 0: boxs[i*5+2] = (boxs[i*5+2] * h + padh) / w boxs[i*5+4] = (boxs[i*5+4] * h) / w # boxs转为yololabel label = self.boxs2yololabel(boxs) # img,label转为tensor img = transforms.ToTensor()(img) label = transforms.ToTensor()(label) return img,label调用测试train_dataset = Dataset_VOC(mode="train") val_dataset = Dataset_VOC(mode="val") train_dataloader = DataLoader(train_dataset,batch_size=2,shuffle=True) val_dataloader = DataLoader(val_dataset,batch_size=2,shuffle=True) for i,(inputs,labels) in enumerate(train_dataloader): print(inputs.shape,labels.shape) break for i,(inputs,labels) in enumerate(val_dataloader): print(inputs.shape,labels.shape) breaktorch.Size([2, 3, 448, 448]) torch.Size([2, 30, 7, 7]) torch.Size([2, 3, 448, 448]) torch.Size([2, 30, 7, 7])3.YOLOv1网络部分网络结构模块封装import torch import torch.nn as nn class YOLOv1(nn.Module): def __init__(self): super(YOLOv1,self).__init__() self.feature = nn.Sequential( nn.Conv2d(in_channels=3,out_channels=64,kernel_size=7,stride=2,padding=3), nn.LeakyReLU(), nn.MaxPool2d(kernel_size=2,stride=2), nn.Conv2d(in_channels=64,out_channels=192,kernel_size=3,stride=1,padding=1), nn.LeakyReLU(), nn.MaxPool2d(kernel_size=2,stride=2), nn.Conv2d(in_channels=192,out_channels=128,kernel_size=1,stride=1,padding=0), nn.LeakyReLU(), nn.Conv2d(in_channels=128,out_channels=256,kernel_size=3,stride=1,padding=1), nn.LeakyReLU(), nn.Conv2d(in_channels=256,out_channels=256,kernel_size=1,stride=1,padding=0), nn.LeakyReLU(), nn.Conv2d(in_channels=256,out_channels=512,kernel_size=3,stride=1,padding=1), nn.LeakyReLU(), nn.MaxPool2d(kernel_size=2,stride=2), nn.Conv2d(in_channels=512,out_channels=256,kernel_size=1,stride=1,padding=0), nn.LeakyReLU(), nn.Conv2d(in_channels=256,out_channels=512,kernel_size=3,stride=1,padding=1), nn.LeakyReLU(), nn.Conv2d(in_channels=512,out_channels=256,kernel_size=1,stride=1,padding=0), nn.LeakyReLU(), nn.Conv2d(in_channels=256,out_channels=512,kernel_size=3,stride=1,padding=1), nn.LeakyReLU(), nn.Conv2d(in_channels=512,out_channels=256,kernel_size=1,stride=1,padding=0), nn.LeakyReLU(), nn.Conv2d(in_channels=256,out_channels=512,kernel_size=3,stride=1,padding=1), nn.LeakyReLU(), nn.Conv2d(in_channels=512,out_channels=256,kernel_size=1,stride=1,padding=0), nn.LeakyReLU(), nn.Conv2d(in_channels=256,out_channels=512,kernel_size=3,stride=1,padding=1), nn.Conv2d(in_channels=512,out_channels=512,kernel_size=1,stride=1,padding=0), nn.LeakyReLU(), nn.Conv2d(in_channels=512,out_channels=1024,kernel_size=3,stride=1,padding=1), nn.LeakyReLU(), nn.MaxPool2d(kernel_size=2,stride=2), nn.Conv2d(in_channels=1024,out_channels=512,kernel_size=1,stride=1,padding=0), nn.LeakyReLU(), nn.Conv2d(in_channels=512,out_channels=1024,kernel_size=3,stride=1,padding=1), nn.LeakyReLU(), nn.Conv2d(in_channels=1024,out_channels=512,kernel_size=1,stride=1,padding=0), nn.LeakyReLU(), nn.Conv2d(in_channels=512,out_channels=1024,kernel_size=3,stride=1,padding=1), nn.LeakyReLU(), nn.Conv2d(in_channels=1024,out_channels=1024,kernel_size=3,stride=1,padding=1), nn.LeakyReLU(), nn.Conv2d(in_channels=1024,out_channels=1024,kernel_size=3,stride=2,padding=1), nn.LeakyReLU(), nn.Conv2d(in_channels=1024,out_channels=1024,kernel_size=3,stride=1,padding=1), nn.LeakyReLU(), nn.Conv2d(in_channels=1024,out_channels=1024,kernel_size=3,stride=1,padding=1), nn.LeakyReLU(), ) self.classify = nn.Sequential( nn.Flatten(), nn.Linear(1024 * 7 * 7, 4096), nn.Dropout(0.5), nn.Linear(4096, 1470) #1470=7*7*30 ) def forward(self,x): x = self.feature(x) x = self.classify(x) return x调用测试yolov1 = YOLOv1() fake_input = torch.zeros((1,3,448,448)) print(fake_input.shape) output = yolov1(fake_input) print(output.shape)yolov1 = YOLOv1() fake_input = torch.zeros((1,3,448,448)) print(fake_input.shape) output = yolov1(fake_input) print(output.shape)4.YOLOv1损失函数部分损失函数详解模块封装""" + input + pred: (batch_size,30,7,7)的网络输出数据 + labels: (batch_size,30,7,7)的样本标签数据 + output + 当前批次样本的平均损失 """ """ + YOLOv1 的损失分为3部分 + 坐标预测损失 + 置信度预测损失 + 含object的box的confidence预测损失 + 不含object的box的confidence预测损失 + 类别预测损失 """ class YOLOv1_Loss(nn.Module): def __init__(self): super(YOLOv1_Loss,self).__init__() def convert_box_type(self,src_box): """ box格式转换 + input + src_box : [box_x_lefttop,box_y_lefttop,box_w,box_h] + output + dst_box : [box_x1,box_y1,box_x2,box_y2] """ x,y,w,h = tuple(src_box) x1,y1 = x,y x2,y2 = x+w,y+w return [x1,y1,x2,y2] def cal_iou(self,box1,box2): """ iou计算 """ # 求相交区域左上角的坐标和右下角的坐标 box_intersect_x1 = max(box1[0], box2[0]) box_intersect_y1 = max(box1[1], box2[1]) box_intersect_x2 = min(box1[2], box2[2]) box_intersect_y2 = min(box1[3], box2[3]) # 求二者相交的面积 area_intersect = (box_intersect_y2 - box_intersect_y1) * (box_intersect_x2 - box_intersect_x1) # 求box1,box2的面积 area_box1 = (box1[2] - box1[0]) * (box1[3] - box1[1]) area_box2 = (box2[2] - box2[0]) * (box2[3] - box2[1]) # 求二者相并的面积 area_union = area_box1 + area_box2 - area_intersect # 计算iou(交并比) iou = area_intersect / area_union return iou def forward(self,pred,target): batch_size = pred.shape[0] lambda_noobj = 0.5 # lambda_noobj参数 lambda_coord = 5 # lambda_coord参数 site_pred_loss = 0 # 坐标预测损失 obj_confidence_pred_loss = 0 # 含object的box的confidence预测损失 noobj_confidence_pred_loss = 0 #不含object的box的confidence预测损失 class_pred_loss = 0 # 类别预测损失 for batch_size_index in range(batch_size): # batchsize循环 for x_index in range(7): # x方向网格循环 for y_index in range(7): # y方向网格循环 # 获取单个网格的预测数据和真实数据 pred_data = pred[batch_size_index,:,x_index,y_index] # [x,y,w,h,confidence,x,y,w,h,confidence,cls*20] true_data = target[batch_size_index,:,x_index,y_index] #[x,y,w,h,confidence,x,y,w,h,confidence,cls*20] if true_data[4]==1:# 如果包含物体 # 解析预测数据和真实数据 pred_box_confidence_1 = pred_data[0:5] # [x,y,w,h,confidence1] pred_box_confidence_2 = pred_data[5:10] # [x,y,w,h,confidence2] true_box_confidence = true_data[0:5] # [x,y,w,h,confidence] # 获取两个预测box并计算与真实box的iou iou1 = self.cal_iou(self.convert_box_type(pred_box_confidence_1[0:4]),self.convert_box_type(true_box_confidence[0:4])) iou2 = self.cal_iou(self.convert_box_type(pred_box_confidence_2[0:4]),self.convert_box_type(true_box_confidence[0:4])) # 在两个box中选择iou大的box负责预测物体 if iou1 >= iou2: better_box_confidence,bad_box_confidence = pred_box_confidence_1,pred_box_confidence_2 better_iou,bad_iou = iou1,iou2 else: better_box_confidence,bad_box_confidence = pred_box_confidence_2,pred_box_confidence_1 better_iou,bad_iou = iou2,iou1 # 计算坐标预测损失 site_pred_loss += lambda_coord * torch.sum((better_box_confidence[0:2]- true_box_confidence[0:2])**2) # x,y的预测损失 site_pred_loss += lambda_coord * torch.sum((better_box_confidence[2:4].sqrt()-true_box_confidence[2:4].sqrt())**2) # w,h的预测损失 # 计算含object的box的confidence预测损失 obj_confidence_pred_loss += (better_box_confidence[4] - better_iou)**2 # iou比较小的bbox不负责预测物体,因此confidence loss算在noobj中 # 因此还需计算不含object的box的confidence预测损失 noobj_confidence_pred_loss += lambda_noobj * (bad_box_confidence[4] - bad_iou)**2 # 计算类别损失 class_pred_loss += torch.sum((pred_data[10:] - true_data[10:])**2) else: # 如果不包含物体,则只有置信度损失--noobj_confidence_pred_loss # [4,9]代表取两个预测框的confidence noobj_confidence_pred_loss += lambda_noobj * torch.sum(pred[batch_size_index,(4,9),x_index,y_index]**2) loss = site_pred_loss + obj_confidence_pred_loss + noobj_confidence_pred_loss + class_pred_loss return loss/batch_size调用测试loss = YOLOv1_Loss() label1 = torch.zeros([1,30,7,7]) label2 = torch.zeros([1,30,7,7]) print(label1.shape,label2.shape) print(loss(label1,label2)) loss = YOLOv1_Loss() label1 = torch.randn([8,30,7,7]) label2 = torch.randn([8,30,7,7]) print(label1.shape,label2.shape) print(loss(label1,label2))torch.Size([1, 30, 7, 7]) torch.Size([1, 30, 7, 7]) tensor(0.) torch.Size([8, 30, 7, 7]) torch.Size([8, 30, 7, 7]) tensor(46.7713)三.整体封装测试#TODO参考资料【YOLOv1论文翻译】:YOLO: 一体化的,实时的物体检测YOLOv1学习:(一)网络结构推导与实现YOLOv1学习:(二)损失函数理解和实现
-
mAP计算工具使用|快速计算mAP 计算mAP的工具:https://github.com/Cartucho/mAP1.使用步骤clone代码git clone https://github.com/Cartucho/mAPCreate the ground-truth files(将标签文件转为对应的格式,,工具参考2.1)format<class_name> <left> <top> <right> <bottom> [<difficult>]E.g. "image_1.txt"tvmonitor 2 10 173 238 book 439 157 556 241 book 437 246 518 351 difficult pottedplant 272 190 316 259Copy the ground-truth files into the folder input/ground-truth/Create the detection-results filesformat<class_name> <confidence> <left> <top> <right> <bottom>E.g. "image_1.txt"tvmonitor 0.471781 0 13 174 244 cup 0.414941 274 226 301 265 book 0.460851 429 219 528 247 chair 0.292345 0 199 88 436 book 0.269833 433 260 506 336Copy the detection-results files into the folder input/detection-results/Run the codepython main.py2.工具补充2.1 VOC_2_gt.py设置好xml_dir并执行即可得到对应的gt_txt文件import os import xmltodict import shutil from tqdm import tqdm # TODO:需要修改的内容 xml_dir = "/data/jupiter/project/dataset/帯広空港_per_frame/xml/" gt_dir = "./input/ground-truth/" shutil.rmtree(gt_dir) os.mkdir(gt_dir) """ 将voc xml 的数据转为对应的gt_str """ def voc_2_gt_str(xml_dict): objects = xml_dict["annotation"]["object"] obj_list = [] if isinstance(objects,list): # xml文件中包含多个object for obj in objects: obj_list.append(obj) else: # xml文件中包含1个object obj_list.append(objects) # 获取gt格式的数据信息 gt_str = "" for obj in obj_list: left = int(obj['bndbox']['xmin']) top = int(obj['bndbox']['ymin']) right = int(obj['bndbox']['xmax']) bottom = int(obj['bndbox']['ymax']) obj_name = obj['name'] gt_str += "%s %s %s %s %s\n" % (obj_name, left, top, right, bottom) return gt_str xml_list = os.listdir(xml_dir) pbar = tqdm(total=len(xml_list)) # 加入进度条支持 pbar.set_description("VOC2GT") # 设置前缀 for tmp_file in xml_list: xml_path = os.path.join(xml_dir,tmp_file) gt_txt_path = os.path.join(gt_dir,tmp_file.replace(".xml", ".txt")) # 读取xml文件+转为字典 with open(xml_path,'r',encoding="utf8") as f: xml_str = f.read() xml_dict = xmltodict.parse(xml_str) # 提取对应的数据 gt_str = voc_2_gt_str(xml_dict) # 写入对应的gt_txt文件 with open(gt_txt_path, "w") as f: f.write(gt_str) pbar.update(1) pbar.close()VOC2GT: 27%|██████████████████████████████████████████████████████████████▌ | 24013/89029 [03:25<09:54, 109.31it/s]2.2 YOLOv5_2_dr.py# YOLOv5_2_dr import os import xmltodict import shutil from tqdm import tqdm # TODO:需要修改的内容 yolov5_detect_txt_dir = "/data/jupiter/project/目标检测对比实验/yolov5/runs/detect/exp3/labels" cls_list = ['conveyor', 'refueller', 'aircraft', 'lounge', 'dining car', 'front of baggage car', 'tractor'] img_width = 1632 img_height = 1080 def txt_convert(txt_src,img_width,img_height,cls_list): txt_dst = "" for line in txt_src.split("\n"): if(len(line)==0):continue cls_id,dx,dy,dw,dh,conf = line.split(" ") cls_name = cls_list[int(cls_id)].replace(" ","") x_center = int(float(dx)*img_width) y_center = int(float(dy)*img_height) w = int(float(dw)*img_width) h = int(float(dh)*img_height) x1 = x_center - int(w/2) y1 = y_center - int(h/2) x2 = x1 + w y2 = y1 + h txt_dst += "{} {} {} {} {} {}\n".format(cls_name,conf,x1,y1,x2,y2) return txt_dst dr_dir = "./input/detection-results/" txt_list = os.listdir(yolov5_detect_txt_dir) pbar = tqdm(total=len(txt_list)) # 加入进度条支持 pbar.set_description("YOLOv5_2_dr") # 设置前缀 for file in txt_list: txt_path_src = os.path.join(yolov5_detect_txt_dir,file) txt_path_dst = os.path.join(dr_dir,"{:>05d}.txt".format(int(file.split("_")[1][:-4]))) # 读取原文件 with open(txt_path_src) as f: txt_src = f.read() # 转为目标格式 txt_dst = txt_convert(txt_src,img_width,img_height,cls_list) # 写入对应的dr_txt文件 with open(txt_path_dst,"w") as f: f.write(txt_dst) pbar.update(1) pbar.close()参考资料https://github.com/Cartucho/mAP.git目标检测中的mAP及代码实现
-
VOC2VID:将VOC格式的数据集转为视频进行查看|可视化视频标注结果 通常用于查看针对连续视频标注的结果,因博主有视频目标检测的需求所以写了该小工具# 可视化视频标注结果 import numpy as np import cv2 import xmltodict import os from tqdm import tqdm # 基本信息填充 xml_dir="./data_handle/xml/"# VOC xml文件所在文件夹 img_dir="./data_handle/img/"# VOC img文件所在文件夹 class_list = ['conveyor', 'refueller', 'aircraft', 'lounge', 'dining car', 'front of baggage car', 'tractor'] # class_list """ 将voc xml 的数据转为对应的bbox_list """ def voc_2_yolo_bbox_list(xml_dict): objects = xml_dict["annotation"]["object"] obj_list = [] if isinstance(objects,list): # xml文件中包含多个object for obj in objects: obj_list.append(obj) else: # xml文件中包含1个object obj_list.append(objects) bbox_list = [] for obj in obj_list: # 获取voc格式的数据信息 x1 = int(obj['bndbox']['xmin']) y1 = int(obj['bndbox']['ymin']) x2 = int(obj['bndbox']['xmax']) y2 = int(obj['bndbox']['ymax']) score = 1 cls_id = class_list.index(obj['name']) bbox_list.append([x1,y1,x2,y2,score,cls_id]) return bbox_list """ 生成color_list """ def random_color(color_num): color_list = [] for j in range(color_num): color_single = (int(np.random.randint(0,255)),int(np.random.randint(0,255)),int(np.random.randint(0,255))) color_list.append(tuple(color_single)) return color_list color_list = random_color(len(class_list)) """ 目标检测预测结果可视化函数 + img:进行目标检测的图片 + bbox_list:处理过的预测结果 + class_name_list:用于将cls_is转为cls_name + color_list:绘制不同的类别使用不同的颜色 + thresh:阈值 """ def vis_detections(img, bbox_list,class_name_list=class_list,color_list=color_list,thresh=0.5): for bbox in bbox_list: # 参数解析 x1,y1,x2,y2,score,cls_id = bbox[0],bbox[1],bbox[2], bbox[3],bbox[4],int(bbox[5]) cls_name = class_name_list[cls_id] color = color_list[cls_id] # 跳过低于阈值的框 if score<thresh:continue # 画框 cv2.rectangle(img, (int(x1),int(y1)), (int(x2),int(y2)),color_list[cls_id],2) # 画label label_text = '{:s} {:.3f}'.format(cls_name, score) cv2.putText(img, label_text, (x1-5, y1-5),cv2.FONT_HERSHEY_SIMPLEX, 0.8, color_list[cls_id], 2) return img img_list = os.listdir(img_dir) frame_rate = 30 # 帧率 frame_shape = cv2.imread(os.path.join(img_dir,img_list[0])).shape[:-1] # 图片大小/帧shape frame_shape = (frame_shape[1],frame_shape[0]) # 交换w和h videoWriter = cv2.VideoWriter('result.mp4', cv2.VideoWriter_fourcc(*'MJPG'), frame_rate, frame_shape) # 初始化视频帧writer # 加入进度条支持 pbar = tqdm(total=len(img_list)) pbar.set_description("VOC2VID") # 开始逐帧写入视频帧 frame_id = 1 for file in img_list: img_path = os.path.join(img_dir,file) # img地址 img = cv2.imread(img_path) # 读取img xml_path = os.path.join(xml_dir,file[:-3]+"xml") # xml地址 # 读取xml文件+转为字典+ 转为bbox_list with open(xml_path,'r',encoding="utf8") as f: xml_str = f.read() xml_dict = xmltodict.parse(xml_str) bbox_list = voc_2_yolo_bbox_list(xml_dict) # 绘制xml标注结果 img = vis_detections(img,bbox_list) frame_id += 1 # if frame_id%120 == 0: # break videoWriter.write(img) pbar.update(1) pbar.close() videoWriter.release()
-
目标检测结果可视化 1.核心函数# 目标检测效果可视化 import numpy as np import cv2 # class_list class_list = ['Plane', 'BridgeVehicle', 'Person', 'LuggageVehicle', 'RefuelVehicle', 'FoodVehicle', 'LuggageVehicleHead', 'TractorVehicle', 'RubbishVehicle', 'FollowMe'] """ 生成color_list """ # 生成number个color def random_color(color_num): color_list = [] for j in range(color_num): color_single = (int(np.random.randint(0,255)),int(np.random.randint(0,255)),int(np.random.randint(0,255))) color_list.append(tuple(color_single)) return color_list color_list = random_color(len(class_list)) """ 目标检测预测结果可视化函数 + img:进行目标检测的图片 + bbox_list:处理过的预测结果 + class_name_list:用于将cls_is转为cls_name + color_list:绘制不同的类别使用不同的颜色 + thresh:阈值 """ def vis_detections(img, bbox_list,class_name_list=class_list,color_list=color_list,thresh=0.5): for bbox in bbox_list: # 参数解析 x1,y1,x2,y2,score,cls_id = bbox[0],bbox[1],bbox[2], bbox[3],bbox[4],int(bbox[5]) cls_name = class_name_list[cls_id] color = color_list[cls_id] # 跳过低于阈值的框 if score<thresh:continue # 画框 cv2.rectangle(img, (int(x1),int(y1)), (int(x2),int(y2)),color_list[cls_id],2) # 画label label_text = '{:s} {:.3f}'.format(cls_name, score) cv2.putText(img, label_text, (x1-5, y1-5),cv2.FONT_HERSHEY_SIMPLEX, 0.8, color_list[cls_id], 2) return img2.调用测试img = cv2.imread("./data_handle/img/00001.jpg.") bbox_list = [ [882,549,1365,631,1,1] ] img = vis_detections(img,bbox_list) img_show = cv2.cvtColor(img,cv2.COLOR_BGR2RGB) import matplotlib.pyplot as plt plt.figure(dpi=200) plt.xticks([]) plt.yticks([]) plt.imshow(img_show) plt.show()
-
YOLO2VOC:将YOLO格式的数据转为xml格式的数据 当我们使用训练好的模型进行辅助标记的时候会有将YOLO检测到的数据转为VOC格式的xml的需求import xmltodict from xml.dom import minidom import copy # 待填充数据 frame_id = 3 # 视频帧编号 class_list = ['conveyor', 'refueller', 'aircraft', 'lounge', 'dining car', 'front of baggage car', 'tractor'] #类别信息 bbox_list = [[5, 824, 747, 912, 809], [3, 882, 549, 1365, 631], [4, 536, 768, 1023, 988], [1, 846, 687, 983, 747], [2, 2, 418, 126, 588], [0, 402, 847, 696, 987], [5, 844, 688, 984, 750]] # 准备相关模板 xml_base =""" <annotation> <folder>img</folder> <filename></filename> <path></path> <size> <width>1632</width> <height>1080</height> <depth>3</depth> </size> </annotation> """ obj_base =""" <object> <name></name> <bndbox> <xmin></xmin> <ymin></ymin> <xmax></xmax> <ymax></ymax> </bndbox> </object> """ # 读取模板并填充基本信息 xml_dict = xmltodict.parse(xml_base) frame_id_format = "{:>05d}".format(frame_id) filename = frame_id_format+".jpg" path = "./img/"+filename xml_dict["annotation"]["filename"] = filename xml_dict["annotation"]["path"] = path # 填入obj数据 xml_dict["annotation"]["object"] = [] obj_template = xmltodict.parse(obj_base)["object"] for bbox in bbox_list: tmp_obj = copy.deepcopy(obj_template) cls_id,x1,y1,x2,y2 = bbox tmp_obj["name"] = class_list[cls_id] tmp_obj["bndbox"]["xmin"] = x1 tmp_obj["bndbox"]["ymin"] = y1 tmp_obj["bndbox"]["xmax"] = x2 tmp_obj["bndbox"]["ymax"] = y2 xml_dict["annotation"]["object"].append(tmp_obj) xmlstr = xmltodict.unparse(xml_dict) xml_pretty_str = minidom.parseString(xmlstr).toprettyxml() print(xml_pretty_str)
-
快速使用Yolov5_DeepSort_Pytorch 1.项目地址https://github.com/mikel-brostrom/Yolov5_DeepSort_Pytorch2.运行步骤2.1 clone项目+ 配置环境git clone --recurse-submodules https://github.com/mikel-brostrom/Yolov5_DeepSort_Pytorch.gitpip install -r requirements.txt2.2训练YOLOv5子模块参考资料:快速使用YOLOv5进行训练VOC格式的数据集2.3 安装Torchreidcd deep_sort/deep rm -r reid git clone https://github.com/KaiyangZhou/deep-person-reid.git mv deep-person-reid reid cd reid python setup.py develop2.4 调用python track.py --source vid.mp4 --yolo_model yolov5s.pt --deep_sort_model osnet_x1_0 --save-txt --save-vid参考资料https://github.com/mikel-brostrom/Yolov5_DeepSort_Pytorchhttps://github.com/KaiyangZhou/deep-person-reid.git新版Yolov5_DeepSort_Pytorch使用ZQPei行人模型的方法
-
VOC格式数据集xml文件处理-类别增、删、改工具 1.删除xml中某一类别import xmltodict import os from xml.dom import minidom from tqdm import tqdm # filter class class_filter_list = ["person","baggage car"] xml_dir="./新建文件夹/"# VOC xml文件所在文件夹 # 加入进度条支持 pbar = tqdm(total=len(os.listdir(xml_dir))) pbar.set_description("VOC xml filter") # 设置前缀 # 逐一处理xml文件 for file in os.listdir(xml_dir): if not file.endswith(".xml"): pbar.update(1) continue # 过滤掉非xml文件 xml_path = os.path.join(xml_dir,file) # 拼接xml地址 # 读取xml文件+转为字典 with open(xml_path,'r',encoding="utf8") as f: xml_str = f.read() xml_dic = xmltodict.parse(xml_str) # 删除掉待过滤的类别 tmp_obj_list = xml_dic["annotation"]["object"] tmp_obj_list_fiter = [] for tmp_obj in tmp_obj_list: if not tmp_obj["name"] in class_filter_list: tmp_obj_list_fiter.append(tmp_obj) xml_dic["annotation"]["object"] = tmp_obj_list_fiter xmlstr = xmltodict.unparse(xml_dic) xml_pretty_str = minidom.parseString(xmlstr).toprettyxml() with open(xml_path,"w",encoding="utf8") as f: f.write(xml_pretty_str) pbar.update(1) pbar.close()2.指定帧区间添加特定bbox# 在固定位置添加指定的候选框 import xmltodict import os from xml.dom import minidom from tqdm import tqdm import copy xml_dir="./data_handle/xml/"# 待处理xml文件夹 # 待添加bbox xml = """ <object> <name>LuggageVehicle</name> <pose>Unspecified</pose> <truncated>0</truncated> <difficult>0</difficult> <bndbox> <xmin>212</xmin> <ymin>71</ymin> <xmax>284</xmax> <ymax>110</ymax> </bndbox> </object> """ xml_dict = xmltodict.parse(xml) obj = xml_dict["object"] cls_add = obj["name"] bndbox = obj["bndbox"] bbox_add = [int(bndbox["xmin"]),int(bndbox["ymin"]),int(bndbox["xmax"]),int(bndbox["ymax"])] # 起止帧id frame_begin = 84543 frame_end = 84919 # 加入进度条支持 pbar = tqdm(total=len(os.listdir(xml_dir))) pbar.set_description("VOC xml add class") # 设置前缀 # 逐一处理xml文件 for file in os.listdir(xml_dir): if not file.endswith(".xml"): pbar.update(1) continue # 过滤掉非xml文件 if int(file[:-4])<frame_begin or int(file[:-4])>frame_end: pbar.update(1) continue xml_path = os.path.join(xml_dir,file) # 拼接地址 # 读取xml文件+转为字典 with open(xml_path,'r',encoding="utf8") as f: xml_str = f.read() xml_dic = xmltodict.parse(xml_str) # 添加类别 tmp_obj_list = xml_dic["annotation"]["object"] tmp_obj = copy.deepcopy(tmp_obj_list[0]) tmp_obj["name"] = cls_add tmp_obj["bndbox"]["xmin"]=bbox_add[0] tmp_obj["bndbox"]["ymin"]=bbox_add[1] tmp_obj["bndbox"]["xmax"]=bbox_add[2] tmp_obj["bndbox"]["ymax"]=bbox_add[3] tmp_obj_list.append(tmp_obj) xml_dic["annotation"]["object"] = tmp_obj_list xmlstr = xmltodict.unparse(xml_dic) xml_pretty_str = minidom.parseString(xmlstr).toprettyxml() with open(xml_path,"w",encoding="utf8") as f: f.write(xml_pretty_str) pbar.update(1) pbar.close()3.指定帧区间删除特定的bbox""" IOU计算 + input + box1:[box1_x1,box1_y1,box1_x2,box1_y2] + box2:[box2_x1,box2_y1,box2_x2,box2_y2] + output + iou值 """ def cal_iou(box1,box2): # 判断是否能相交 if abs(box2[2]+box2[0]-box1[2]-box1[0])>box2[2]-box2[0]+box1[2]-box1[0]: return 0 if abs(box2[3]+box2[1]-box1[3]-box1[1])>box2[3]-box2[1]+box1[3]-box1[1]: return 0 # 求相交区域左上角的坐标和右下角的坐标 box_intersect_x1 = max(box1[0], box2[0]) box_intersect_y1 = max(box1[1], box2[1]) box_intersect_x2 = min(box1[2], box2[2]) box_intersect_y2 = min(box1[3], box2[3]) # 求二者相交的面积 area_intersect = (box_intersect_y2 - box_intersect_y1) * (box_intersect_x2 - box_intersect_x1) # 求box1,box2的面积 area_box1 = (box1[2] - box1[0]) * (box1[3] - box1[1]) area_box2 = (box2[2] - box2[0]) * (box2[3] - box2[1]) # 求二者相并的面积 area_union = area_box1 + area_box2 - area_intersect # 计算iou(交并比) iou = area_intersect / area_union return iou# 删除指定的bbox import xmltodict import os from xml.dom import minidom from tqdm import tqdm xml_dir="./data_handle/xml/"# VOC xml文件所在文件夹 # 匹配待删除的bbox xml = """ <object> <name>Person</name> <bndbox> <xmin>901</xmin> <ymin>6</ymin> <xmax>920</xmax> <ymax>31</ymax> </bndbox> </object> """ xml_dict = xmltodict.parse(xml) obj = xml_dict["object"] cls_filter = obj["name"] bndbox = obj["bndbox"] bbox_filter = [int(bndbox["xmin"]),int(bndbox["ymin"]),int(bndbox["xmax"]),int(bndbox["ymax"])] iou_filter = 0.6 # 起止帧id frame_begin = 85000 frame_end = 85427 # 加入进度条支持 pbar = tqdm(total=len(os.listdir(xml_dir))) pbar.set_description("VOC xml filter") # 设置前缀 # 逐一处理xml文件 for file in os.listdir(xml_dir): if not file.endswith(".xml"): pbar.update(1) continue # 过滤掉非xml文件 if int(file[:-4])<frame_begin or int(file[:-4])>frame_end: pbar.update(1) continue xml_path = os.path.join(xml_dir,file) # 拼接xml地址 # 读取xml文件+转为字典 with open(xml_path,'r',encoding="utf8") as f: xml_str = f.read() xml_dic = xmltodict.parse(xml_str) # 删除掉待过滤的类别 tmp_obj_list = xml_dic["annotation"]["object"] tmp_obj_list_fiter = [] for tmp_obj in tmp_obj_list: tmp_bndbox = tmp_obj["bndbox"] tmp_obj_bbox = [int(tmp_bndbox["xmin"]),int(tmp_bndbox["ymin"]),int(tmp_bndbox["xmax"]),int(tmp_bndbox["ymax"])] if tmp_obj["name"]==cls_filter and cal_iou(bbox_filter,tmp_obj_bbox)>iou_filter: print(cal_iou(bbox_filter,tmp_obj_bbox)) pass else: tmp_obj_list_fiter.append(tmp_obj) xml_dic["annotation"]["object"] = tmp_obj_list_fiter xmlstr = xmltodict.unparse(xml_dic) xml_pretty_str = minidom.parseString(xmlstr).toprettyxml() with open(xml_path,"w",encoding="utf8") as f: f.write(xml_pretty_str) pbar.update(1) pbar.close()4.指定帧区间修改指定bbox的类别""" IOU计算 + input + box1:[box1_x1,box1_y1,box1_x2,box1_y2] + box2:[box2_x1,box2_y1,box2_x2,box2_y2] + output + iou值 """ def cal_iou(box1,box2): # 判断是否能相交 if abs(box2[2]+box2[0]-box1[2]-box1[0])>box2[2]-box2[0]+box1[2]-box1[0]: return 0 if abs(box2[3]+box2[1]-box1[3]-box1[1])>box2[3]-box2[1]+box1[3]-box1[1]: return 0 # 求相交区域左上角的坐标和右下角的坐标 box_intersect_x1 = max(box1[0], box2[0]) box_intersect_y1 = max(box1[1], box2[1]) box_intersect_x2 = min(box1[2], box2[2]) box_intersect_y2 = min(box1[3], box2[3]) # 求二者相交的面积 area_intersect = (box_intersect_y2 - box_intersect_y1) * (box_intersect_x2 - box_intersect_x1) # 求box1,box2的面积 area_box1 = (box1[2] - box1[0]) * (box1[3] - box1[1]) area_box2 = (box2[2] - box2[0]) * (box2[3] - box2[1]) # 求二者相并的面积 area_union = area_box1 + area_box2 - area_intersect # 计算iou(交并比) iou = area_intersect / area_union return iou # 修改指定框的类别 import xmltodict import os from xml.dom import minidom from tqdm import tqdm xml_dir="./data_handle/xml/"# VOC xml文件所在文件夹 # 匹配待修改的bbox xml = """ <object> <name>RefuelVehicle</name> <pose>Unspecified</pose> <truncated>0</truncated> <difficult>0</difficult> <bndbox> <xmin>106</xmin> <ymin>389</ymin> <xmax>237</xmax> <ymax>542</ymax> </bndbox> </object> """ xml_dict = xmltodict.parse(xml) obj = xml_dict["object"] cls_filter_src = obj["name"] bndbox = obj["bndbox"] bbox_filter = [int(bndbox["xmin"]),int(bndbox["ymin"]),int(bndbox["xmax"]),int(bndbox["ymax"])] cls_filter_dst = "LuggageVehicle" iou_filter = 0.99 # 起止帧id frame_begin = 59680 frame_end = 60000 # 加入进度条支持 pbar = tqdm(total=len(os.listdir(xml_dir))) pbar.set_description("VOC xml filter") # 设置前缀 # 逐一处理xml文件 for file in os.listdir(xml_dir): if not file.endswith(".xml"): pbar.update(1) continue # 过滤掉非xml文件 if int(file[:-4])<frame_begin or int(file[:-4])>frame_end: pbar.update(1) continue xml_path = os.path.join(xml_dir,file) # 拼接原始地址 # 读取xml文件+转为字典 with open(xml_path,'r',encoding="utf8") as f: xml_str = f.read() xml_dic = xmltodict.parse(xml_str) # 删除掉待过滤的类别 tmp_obj_list = xml_dic["annotation"]["object"] tmp_obj_list_fiter = [] for tmp_obj in tmp_obj_list: tmp_bndbox = tmp_obj["bndbox"] tmp_obj_bbox = [int(tmp_bndbox["xmin"]),int(tmp_bndbox["ymin"]),int(tmp_bndbox["xmax"]),int(tmp_bndbox["ymax"])] if tmp_obj["name"]==cls_filter_src and cal_iou(bbox_filter,tmp_obj_bbox)>iou_filter: tmp_obj["name"]=cls_filter_dst tmp_obj_list_fiter.append(tmp_obj) else: tmp_obj_list_fiter.append(tmp_obj) xml_dic["annotation"]["object"] = tmp_obj_list_fiter xmlstr = xmltodict.unparse(xml_dic) xml_pretty_str = minidom.parseString(xmlstr).toprettyxml() with open(xml_path,"w",encoding="utf8") as f: f.write(xml_pretty_str) pbar.update(1) pbar.close()
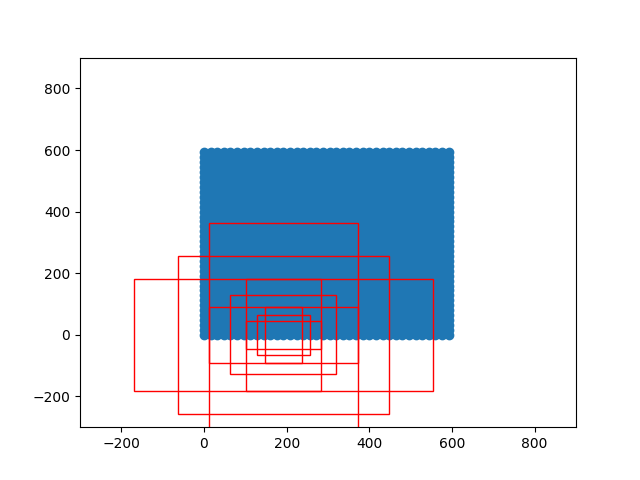
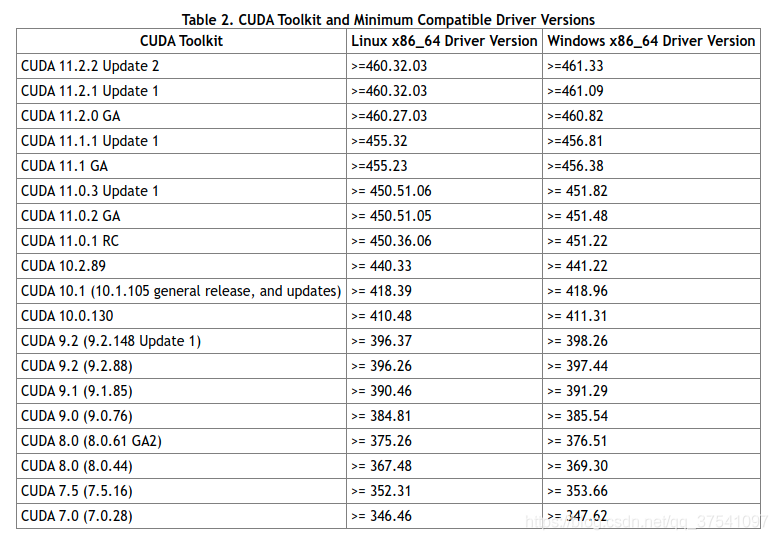
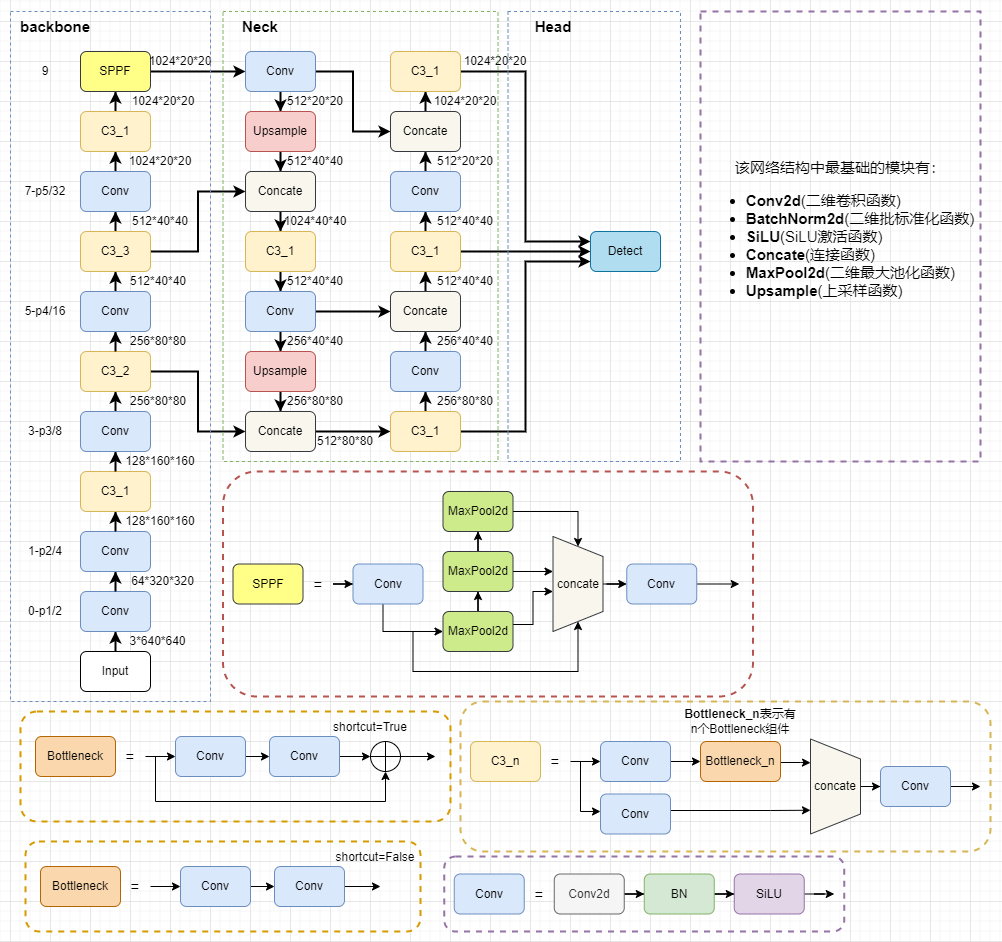
![[目标检测模型辅助数据标注]YOLOv5检测图片并将结果转为voc的xml格式](https://blog.inat.top/usr/themes/Joe/assets/thumb/40.jpg)
![[视频目标检测]:使用MEGA|DFF|FGFA训练自己的数据集](https://blog.inat.top/usr/themes/Joe/assets/thumb/31.jpg)