搜索到
8
篇与
的结果
-
![[视频目标检测]:使用MEGA|DFF|FGFA训练自己的数据集](https://npm.elemecdn.com/typecho-joe-latest/assets/img/lazyload.jpg) [视频目标检测]:使用MEGA|DFF|FGFA训练自己的数据集 1.创建环境创建虚拟环境conda create --name MEGA -y python=3.7 source activate MEGA安装基础包conda install ipython pip pip install ninja yacs cython matplotlib tqdm opencv-python scipy export INSTALL_DIR=$PWD安装pytorch在安装pytorch的时候,原作者是这样的:conda install pytorch=1.3.0 torchvision cudatoolkit=10.0 -c pytorch但实际上使用cuda11.0+pytorch1.7也可以编译跑通,所以在这一步我们将其替换成:conda install pytorch==1.7.0 torchvision==0.8.0 torchaudio==0.7.0 cudatoolkit=11.0 -c pytorch然后就是作者使用到的coco数据集和cityperson数据集的安装:cd $INSTALL_DIR git clone https://github.com/cocodataset/cocoapi.git cd cocoapi/PythonAPId python setup.py build_ext install cd $INSTALL_DIR git clone https://github.com/mcordts/cityscapesScripts.git cd cityscapesScripts/ python setup.py build_ext install安装apex:(可省略) (建议省略,没省略运行报错)git clone https://github.com/NVIDIA/apex.git cd apex python setup.py install --cuda_ext --cpp_ext如果使用的是cuda11.0+pytorch1.7这里会报错deform_conv_cuda.cu(155): error: identifier "AT_CHECK " is undefined解决:在mega_core/csrc/cuda/deform_conv_cuda.cu 和 mega_core/csrc/cuda/deform_pool_cuda.cu文件的开头加上如下代码:#ifndef AT_CHECK #define AT_CHECK TORCH_CHECK #endif实际上原作者并没有使用到apex来进行混合精度训练,这一步也可省略,若省略的话在代码中需要修改几处地方:首先是mega_core/engine/trainer.py中的开头导入apex包注释掉,108-109行改为:losses.backward()还有tools/train_net.py中33行-36行注释掉# try: # from apex import amp # except ImportError: # raise ImportError('Use APEX for multi-precision via apex.amp') 50行也注释掉:#model, optimizer = amp.initialize(model, optimizer, opt_level=amp_opt_level)还有mega_core/layers/nms.py,注释掉第5行第8行改为:nms = _C.nms还有mega_core/layers/roi_align.py注释掉第10、57行还有mega_core/layers/roi_pool.py注释掉第10、56行这样应该就可以了。2.下载和初始化mega.pytorch# install PyTorch Detection cd $INSTALL_DIR git clone https://github.com/Scalsol/mega.pytorch.git cd mega.pytorch # the following will install the lib with # symbolic links, so that you can modify # the files if you want and won't need to # re-build it python setup.py build develop pip install 'pillow<7.0.0'3.制作自己的数据集参考作者提供的customize.md文件3.1 数据集格式参考:https://github.com/Scalsol/mega.pytorch/blob/master/CUSTOMIZE.md【注意事项】1.图片编号是从0开始的6位数字;(不想实现自己的数据加载器这是必要的)2.annotation内的xml文件与train、val钟文件一一对应。datasets ├── vid_custom | |── train | | |── video_snippet_1 | | | |── 000000.JPEG | | | |── 000001.JPEG | | | |── 000002.JPEG | | | ... | | |── video_snippet_2 | | | |── 000000.JPEG | | | |── 000001.JPEG | | | |── 000002.JPEG | | | ... | | ... | |── val | | |── video_snippet_1 | | | |── 000000.JPEG | | | |── 000001.JPEG | | | |── 000002.JPEG | | | ... | | |── video_snippet_2 | | | |── 000000.JPEG | | | |── 000001.JPEG | | | |── 000002.JPEG | | | ... | | ... | |── annotation | | |── train | | | |── video_snippet_1 | | | | |── 000000.xml | | | | |── 000001.xml | | | | |── 000002.xml | | | | ... | | | |── video_snippet_2 | | | | |── 000000.xml | | | | |── 000001.xml | | | | |── 000002.xml | | | | ... | | ... | | |── val | | | |── video_snippet_1 | | | | |── 000000.xml | | | | |── 000001.xml | | | | |── 000002.xml | | | | ... | | | |── video_snippet_2 | | | | |── 000000.xml | | | | |── 000001.xml | | | | |── 000002.xml | | | | ... | | ...3.2 准备自己txt文件具体参考源MEGA代码中datasets\ILSVRC2015\ImageSets提供的文档。格式:每一行4列依次代表:video folder, no meaning(just ignore it),frame number,video length;训练集VID_train.txt 对应vid_custom/train文件夹train/ILSVRC2015_VID_train_0000/ILSVRC2015_train_00000000 1 10 300 train/ILSVRC2015_VID_train_0000/ILSVRC2015_train_00000000 1 30 300 train/ILSVRC2015_VID_train_0000/ILSVRC2015_train_00000000 1 50 300 train/ILSVRC2015_VID_train_0000/ILSVRC2015_train_00000000 1 70 300 train/ILSVRC2015_VID_train_0000/ILSVRC2015_train_00000000 1 90 300 train/ILSVRC2015_VID_train_0000/ILSVRC2015_train_00000000 1 110 300 train/ILSVRC2015_VID_train_0000/ILSVRC2015_train_00000000 1 130 300 train/ILSVRC2015_VID_train_0000/ILSVRC2015_train_00000000 1 150 300 train/ILSVRC2015_VID_train_0000/ILSVRC2015_train_00000000 1 170 300 train/ILSVRC2015_VID_train_0000/ILSVRC2015_train_00000000 1 190 300 train/ILSVRC2015_VID_train_0000/ILSVRC2015_train_00000000 1 210 300 train/ILSVRC2015_VID_train_0000/ILSVRC2015_train_00000000 1 230 300 train/ILSVRC2015_VID_train_0000/ILSVRC2015_train_00000000 1 250 300 train/ILSVRC2015_VID_train_0000/ILSVRC2015_train_00000000 1 270 300 train/ILSVRC2015_VID_train_0000/ILSVRC2015_train_00000000 1 290 300 train/ILSVRC2015_VID_train_0000/ILSVRC2015_train_00001000 1 1 48 train/ILSVRC2015_VID_train_0000/ILSVRC2015_train_00001000 1 4 48 train/ILSVRC2015_VID_train_0000/ILSVRC2015_train_00001000 1 8 48 ···验证集VID_val.txt 对应vid_custom/val文件夹val/ILSVRC2015_val_00000000 1 0 464 val/ILSVRC2015_val_00000000 2 1 464 val/ILSVRC2015_val_00000000 3 2 464 val/ILSVRC2015_val_00000000 4 3 464 val/ILSVRC2015_val_00000000 5 4 464 val/ILSVRC2015_val_00000000 6 5 464 val/ILSVRC2015_val_00000000 7 6 464 val/ILSVRC2015_val_00000000 8 7 464 val/ILSVRC2015_val_00000000 9 8 464 val/ILSVRC2015_val_00000000 10 9 464 val/ILSVRC2015_val_00000000 11 10 464 val/ILSVRC2015_val_00000000 12 11 464 val/ILSVRC2015_val_00000000 13 12 464 val/ILSVRC2015_val_00000000 14 13 464 val/ILSVRC2015_val_00000000 15 14 464 val/ILSVRC2015_val_00000000 16 15 464 ···4.参数修改mega_core/data/datasets/vid.py修改VIDDataset内classes和classes_map:# classes=['__background__',#always index0 'car'] # classes_map=['__background__',# always index0 'n02958343'] # 自己标的数据集两个都填一样的就行 classes = ['__background__', # always index 0 'BridgeVehicle', 'Person', 'FollowMe', 'Plane', 'LuggageTruck', 'RefuelingTruck', 'FoodTruck', 'Tractor'] classes_map = ['__background__', # always index 0 'BridgeVehicle', 'Person', 'FollowMe', 'Plane', 'LuggageTruck', 'RefuelingTruck', 'FoodTruck', 'Tractor']mega_core/config/paths_catalog.py修改 DatasetCatalog.DATASETS,在变量的最后加上如下内容"vid_custom_train":{ "img_dir":"vid_custom/train", "anno_path":"vid_custom/annotation", "img_index":"vid_custom/VID_train.txt" }, "vid_custom_val":{ "img_dir":"vid_custom/val", "anno_path":"vid_custom/annotation", "img_index":"vid_custom/VID_val.txt" }修改if函数下if语句,添加上vid条件if ("DET" in name) or ("VID" in name) or ("vid" in name):修改configs/BASE_RCNN_1gpu.yaml(取决于你用几张gpu训练)NUM_CLASSES: 9#(物体类别数+背景) TRAIN: ("vid_custom_train",)#记得加“,” TEST: ("vid_custom_val",)#记得加“,”修改configs/MEGA/vid_R_101_C4_MEGA_1x.yamlDATASETS: TRAIN: ("vid_custom_train",)#记得加“,” TEST: ("vid_custom_val",)#记得加“,”5.训练和测试代码5.1 开始训练python -m torch.distributed.launch \ --nproc_per_node=1 \ tools/train_net.py \ --master_port=$((RANDOM + 10000)) \ --config-file configs/BASE_RCNN_1gpu.yaml \ OUTPUT_DIR training_dir/BASE_RCNNpython -m torch.distributed.launch \ --nproc_per_node=1 \ tools/train_net.py \ --master_port=$((RANDOM + 10000)) \ --config-file configs/DFF/vid_R_50_C4_DFF_1x.yaml \ OUTPUT_DIR training_dir/vid_R_50_C4_DFF_1x5.2 开始测试python -m torch.distributed.launch \ --nproc_per_node 1 \ tools/test_net.py \ --config-file configs/BASE_RCNN_1gpu.yaml \ MODEL.WEIGHT training_dir/BASE_RCNN/model_0020000.pth python tools/test_prediction.py \ --config-file configs/BASE_RCNN_1gpu.yaml \ --prediction ./ 参考资料MEGA训练自己的数据集-dockerhttps://github.com/Scalsol/mega.pytorch/issues/63
[视频目标检测]:使用MEGA|DFF|FGFA训练自己的数据集 1.创建环境创建虚拟环境conda create --name MEGA -y python=3.7 source activate MEGA安装基础包conda install ipython pip pip install ninja yacs cython matplotlib tqdm opencv-python scipy export INSTALL_DIR=$PWD安装pytorch在安装pytorch的时候,原作者是这样的:conda install pytorch=1.3.0 torchvision cudatoolkit=10.0 -c pytorch但实际上使用cuda11.0+pytorch1.7也可以编译跑通,所以在这一步我们将其替换成:conda install pytorch==1.7.0 torchvision==0.8.0 torchaudio==0.7.0 cudatoolkit=11.0 -c pytorch然后就是作者使用到的coco数据集和cityperson数据集的安装:cd $INSTALL_DIR git clone https://github.com/cocodataset/cocoapi.git cd cocoapi/PythonAPId python setup.py build_ext install cd $INSTALL_DIR git clone https://github.com/mcordts/cityscapesScripts.git cd cityscapesScripts/ python setup.py build_ext install安装apex:(可省略) (建议省略,没省略运行报错)git clone https://github.com/NVIDIA/apex.git cd apex python setup.py install --cuda_ext --cpp_ext如果使用的是cuda11.0+pytorch1.7这里会报错deform_conv_cuda.cu(155): error: identifier "AT_CHECK " is undefined解决:在mega_core/csrc/cuda/deform_conv_cuda.cu 和 mega_core/csrc/cuda/deform_pool_cuda.cu文件的开头加上如下代码:#ifndef AT_CHECK #define AT_CHECK TORCH_CHECK #endif实际上原作者并没有使用到apex来进行混合精度训练,这一步也可省略,若省略的话在代码中需要修改几处地方:首先是mega_core/engine/trainer.py中的开头导入apex包注释掉,108-109行改为:losses.backward()还有tools/train_net.py中33行-36行注释掉# try: # from apex import amp # except ImportError: # raise ImportError('Use APEX for multi-precision via apex.amp') 50行也注释掉:#model, optimizer = amp.initialize(model, optimizer, opt_level=amp_opt_level)还有mega_core/layers/nms.py,注释掉第5行第8行改为:nms = _C.nms还有mega_core/layers/roi_align.py注释掉第10、57行还有mega_core/layers/roi_pool.py注释掉第10、56行这样应该就可以了。2.下载和初始化mega.pytorch# install PyTorch Detection cd $INSTALL_DIR git clone https://github.com/Scalsol/mega.pytorch.git cd mega.pytorch # the following will install the lib with # symbolic links, so that you can modify # the files if you want and won't need to # re-build it python setup.py build develop pip install 'pillow<7.0.0'3.制作自己的数据集参考作者提供的customize.md文件3.1 数据集格式参考:https://github.com/Scalsol/mega.pytorch/blob/master/CUSTOMIZE.md【注意事项】1.图片编号是从0开始的6位数字;(不想实现自己的数据加载器这是必要的)2.annotation内的xml文件与train、val钟文件一一对应。datasets ├── vid_custom | |── train | | |── video_snippet_1 | | | |── 000000.JPEG | | | |── 000001.JPEG | | | |── 000002.JPEG | | | ... | | |── video_snippet_2 | | | |── 000000.JPEG | | | |── 000001.JPEG | | | |── 000002.JPEG | | | ... | | ... | |── val | | |── video_snippet_1 | | | |── 000000.JPEG | | | |── 000001.JPEG | | | |── 000002.JPEG | | | ... | | |── video_snippet_2 | | | |── 000000.JPEG | | | |── 000001.JPEG | | | |── 000002.JPEG | | | ... | | ... | |── annotation | | |── train | | | |── video_snippet_1 | | | | |── 000000.xml | | | | |── 000001.xml | | | | |── 000002.xml | | | | ... | | | |── video_snippet_2 | | | | |── 000000.xml | | | | |── 000001.xml | | | | |── 000002.xml | | | | ... | | ... | | |── val | | | |── video_snippet_1 | | | | |── 000000.xml | | | | |── 000001.xml | | | | |── 000002.xml | | | | ... | | | |── video_snippet_2 | | | | |── 000000.xml | | | | |── 000001.xml | | | | |── 000002.xml | | | | ... | | ...3.2 准备自己txt文件具体参考源MEGA代码中datasets\ILSVRC2015\ImageSets提供的文档。格式:每一行4列依次代表:video folder, no meaning(just ignore it),frame number,video length;训练集VID_train.txt 对应vid_custom/train文件夹train/ILSVRC2015_VID_train_0000/ILSVRC2015_train_00000000 1 10 300 train/ILSVRC2015_VID_train_0000/ILSVRC2015_train_00000000 1 30 300 train/ILSVRC2015_VID_train_0000/ILSVRC2015_train_00000000 1 50 300 train/ILSVRC2015_VID_train_0000/ILSVRC2015_train_00000000 1 70 300 train/ILSVRC2015_VID_train_0000/ILSVRC2015_train_00000000 1 90 300 train/ILSVRC2015_VID_train_0000/ILSVRC2015_train_00000000 1 110 300 train/ILSVRC2015_VID_train_0000/ILSVRC2015_train_00000000 1 130 300 train/ILSVRC2015_VID_train_0000/ILSVRC2015_train_00000000 1 150 300 train/ILSVRC2015_VID_train_0000/ILSVRC2015_train_00000000 1 170 300 train/ILSVRC2015_VID_train_0000/ILSVRC2015_train_00000000 1 190 300 train/ILSVRC2015_VID_train_0000/ILSVRC2015_train_00000000 1 210 300 train/ILSVRC2015_VID_train_0000/ILSVRC2015_train_00000000 1 230 300 train/ILSVRC2015_VID_train_0000/ILSVRC2015_train_00000000 1 250 300 train/ILSVRC2015_VID_train_0000/ILSVRC2015_train_00000000 1 270 300 train/ILSVRC2015_VID_train_0000/ILSVRC2015_train_00000000 1 290 300 train/ILSVRC2015_VID_train_0000/ILSVRC2015_train_00001000 1 1 48 train/ILSVRC2015_VID_train_0000/ILSVRC2015_train_00001000 1 4 48 train/ILSVRC2015_VID_train_0000/ILSVRC2015_train_00001000 1 8 48 ···验证集VID_val.txt 对应vid_custom/val文件夹val/ILSVRC2015_val_00000000 1 0 464 val/ILSVRC2015_val_00000000 2 1 464 val/ILSVRC2015_val_00000000 3 2 464 val/ILSVRC2015_val_00000000 4 3 464 val/ILSVRC2015_val_00000000 5 4 464 val/ILSVRC2015_val_00000000 6 5 464 val/ILSVRC2015_val_00000000 7 6 464 val/ILSVRC2015_val_00000000 8 7 464 val/ILSVRC2015_val_00000000 9 8 464 val/ILSVRC2015_val_00000000 10 9 464 val/ILSVRC2015_val_00000000 11 10 464 val/ILSVRC2015_val_00000000 12 11 464 val/ILSVRC2015_val_00000000 13 12 464 val/ILSVRC2015_val_00000000 14 13 464 val/ILSVRC2015_val_00000000 15 14 464 val/ILSVRC2015_val_00000000 16 15 464 ···4.参数修改mega_core/data/datasets/vid.py修改VIDDataset内classes和classes_map:# classes=['__background__',#always index0 'car'] # classes_map=['__background__',# always index0 'n02958343'] # 自己标的数据集两个都填一样的就行 classes = ['__background__', # always index 0 'BridgeVehicle', 'Person', 'FollowMe', 'Plane', 'LuggageTruck', 'RefuelingTruck', 'FoodTruck', 'Tractor'] classes_map = ['__background__', # always index 0 'BridgeVehicle', 'Person', 'FollowMe', 'Plane', 'LuggageTruck', 'RefuelingTruck', 'FoodTruck', 'Tractor']mega_core/config/paths_catalog.py修改 DatasetCatalog.DATASETS,在变量的最后加上如下内容"vid_custom_train":{ "img_dir":"vid_custom/train", "anno_path":"vid_custom/annotation", "img_index":"vid_custom/VID_train.txt" }, "vid_custom_val":{ "img_dir":"vid_custom/val", "anno_path":"vid_custom/annotation", "img_index":"vid_custom/VID_val.txt" }修改if函数下if语句,添加上vid条件if ("DET" in name) or ("VID" in name) or ("vid" in name):修改configs/BASE_RCNN_1gpu.yaml(取决于你用几张gpu训练)NUM_CLASSES: 9#(物体类别数+背景) TRAIN: ("vid_custom_train",)#记得加“,” TEST: ("vid_custom_val",)#记得加“,”修改configs/MEGA/vid_R_101_C4_MEGA_1x.yamlDATASETS: TRAIN: ("vid_custom_train",)#记得加“,” TEST: ("vid_custom_val",)#记得加“,”5.训练和测试代码5.1 开始训练python -m torch.distributed.launch \ --nproc_per_node=1 \ tools/train_net.py \ --master_port=$((RANDOM + 10000)) \ --config-file configs/BASE_RCNN_1gpu.yaml \ OUTPUT_DIR training_dir/BASE_RCNNpython -m torch.distributed.launch \ --nproc_per_node=1 \ tools/train_net.py \ --master_port=$((RANDOM + 10000)) \ --config-file configs/DFF/vid_R_50_C4_DFF_1x.yaml \ OUTPUT_DIR training_dir/vid_R_50_C4_DFF_1x5.2 开始测试python -m torch.distributed.launch \ --nproc_per_node 1 \ tools/test_net.py \ --config-file configs/BASE_RCNN_1gpu.yaml \ MODEL.WEIGHT training_dir/BASE_RCNN/model_0020000.pth python tools/test_prediction.py \ --config-file configs/BASE_RCNN_1gpu.yaml \ --prediction ./ 参考资料MEGA训练自己的数据集-dockerhttps://github.com/Scalsol/mega.pytorch/issues/63 -
快速使用mobiledets-yolov4 1.下载项目git clone https://github.com/inacmor/mobiledets-yolov4-pytorch.git2.准备数据2.1 准备VOC格式的数据集put your trainset and labels(xml) in data/Imgs and data/Annotations.这里选择直接将一个VOC格式的数据集通过软链接链接过来ln -s /data_jupiter/dataset/209_VOC_new/Annotations ./ ln -s /data_jupiter/dataset/209_VOC_new/JPEGImages ./Imgs 2.2 修改classes.txtLuggageVehicle BridgeVehicle Plane RefuelVehicle Person FoodVehicle LuggageVehicleHead FollowMe TractorVehicle3.开始训练3.0 环境安装安装pytorch(略)安装apexgit clone https://github.com/NVIDIA/apex cd apex python setup.py install3.1 训练前准备工作python ready.py python kmeans.py3.2 开始训练没有预训练模型的话需要将模型加载注释掉,修改train.py#model.load_state_dict(torch.load(pretrained_weights), strict=False)# 执行训练 python train.py
-
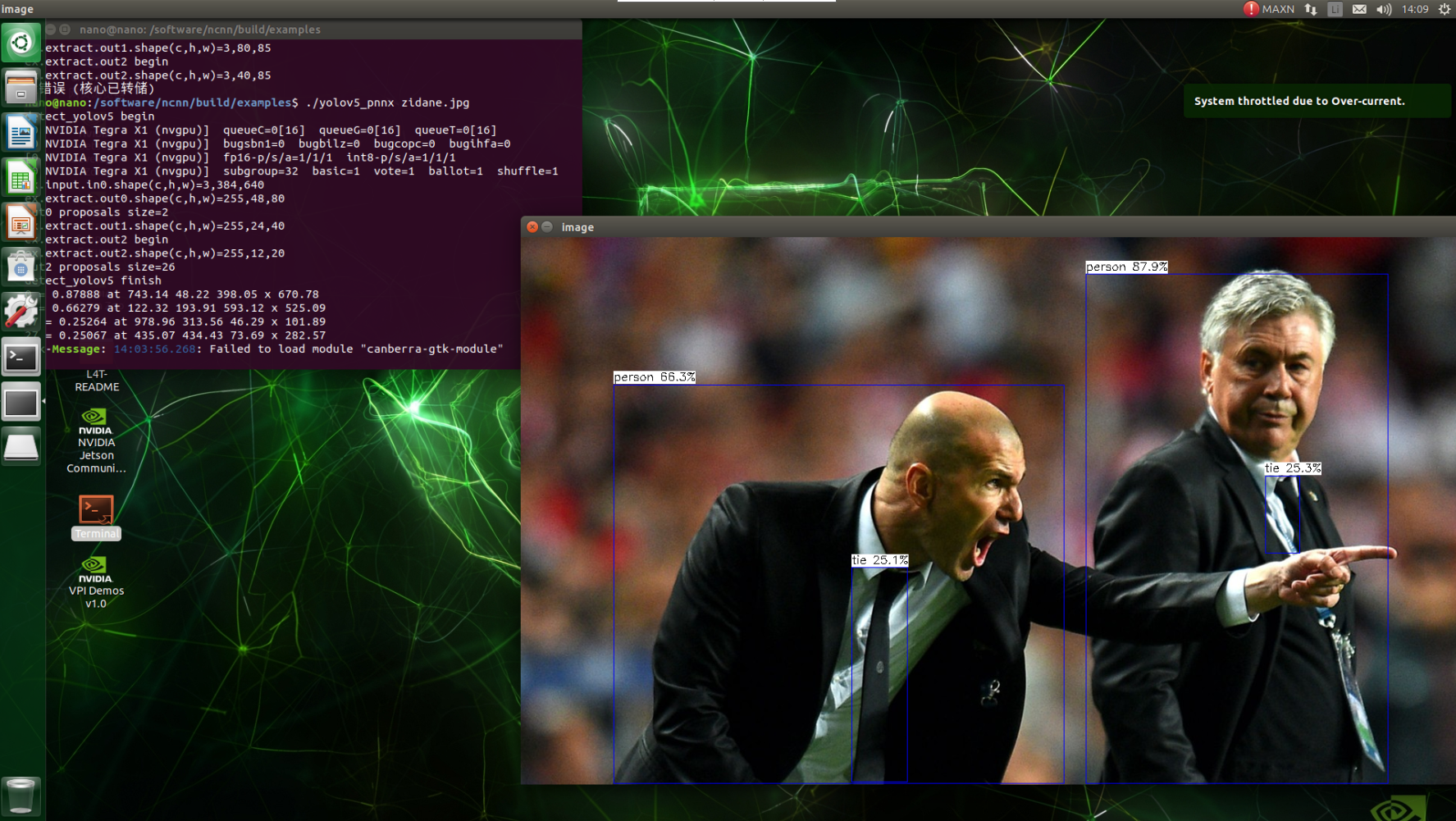
NCNN部署yolov5s 1.NCNN编译安装参考:Linux下如何安装ncnn2.模型转换(pt->onnx->ncnn)$\color{red}{此路不通,转出来的param文件中的Reshape的参数是错的}$2.1 pt模型转换onnx# pt-->onnx python export.py --weights yolov5s.pt --img 640 --batch 1#安装onnx-simplifier pip install onnx-simplifier # onnxsim 精简模型 python -m onnxsim yolov5s.onnx yolov5s-sim.onnx Simplifying... Finish! Here is the difference: ┏━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━┓ ┃ ┃ Original Model ┃ Simplified Model ┃ ┡━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━┩ │ Add │ 10 │ 10 │ │ Concat │ 17 │ 17 │ │ Constant │ 20 │ 0 │ │ Conv │ 60 │ 60 │ │ MaxPool │ 3 │ 3 │ │ Mul │ 69 │ 69 │ │ Pow │ 3 │ 3 │ │ Reshape │ 6 │ 6 │ │ Resize │ 2 │ 2 │ │ Sigmoid │ 60 │ 60 │ │ Split │ 3 │ 3 │ │ Transpose │ 3 │ 3 │ │ Model Size │ 28.0MiB │ 28.0MiB │ └────────────┴────────────────┴──────────────────┘2.2 使用onnx2ncnn.exe 转换模型把你的ncnn/build/tools/onnx加入到环境变量onnx2ncnn yolov5s-sim.onnx yolov5s_6.0.param yolov5s_6.0.bin2.3 调用测试将yolov5s_6.0.param 、yolov5s_6.0.bin模型copy到ncnn/build/examples/位置,运行下面命令./yolov5 image-path就会出现Segmentation fault (core dumped)的报错3.模型转换(pt->torchscript->ncnn)3.1 pt模型转换torchscript# pt-->torchscript python export.py --weights yolov5s.pt --include torchscript --train3.2 下载编译好的 pnnx 工具包执行转换pnnx下载地址:https://github.com/pnnx/pnnx执行转换,获得 yolov5s.ncnn.param 和 yolov5s.ncnn.bin 模型文件,指定 inputshape 并且额外指定 inputshape2 转换成支持动态 shape 输入的模型 ./pnnx yolov5s.torchscript inputshape=[1,3,640,640] inputshape2=[1,3,320,320]3.3 调用测试直接测试的相关文件下载:yolov5_pnnx.zip将 yolov5s.ncnn.param 和 yolov5s.ncnn.bin 模型copy到ncnn/build/examples/位置,运行下面命令./yolov5_pnnx image-path参考资料yolov5 模型部署NCNN(详细过程)Linux&Jetson Nano下编译安装ncnnYOLOv5转NCNN过程Jetson Nano 移植ncnn详细记录u版YOLOv5目标检测ncnn实现(第二版)
-
快速使用Yolov5_DeepSort_Pytorch 1.项目地址https://github.com/mikel-brostrom/Yolov5_DeepSort_Pytorch2.运行步骤2.1 clone项目+ 配置环境git clone --recurse-submodules https://github.com/mikel-brostrom/Yolov5_DeepSort_Pytorch.gitpip install -r requirements.txt2.2训练YOLOv5子模块参考资料:快速使用YOLOv5进行训练VOC格式的数据集2.3 安装Torchreidcd deep_sort/deep rm -r reid git clone https://github.com/KaiyangZhou/deep-person-reid.git mv deep-person-reid reid cd reid python setup.py develop2.4 调用python track.py --source vid.mp4 --yolo_model yolov5s.pt --deep_sort_model osnet_x1_0 --save-txt --save-vid参考资料https://github.com/mikel-brostrom/Yolov5_DeepSort_Pytorchhttps://github.com/KaiyangZhou/deep-person-reid.git新版Yolov5_DeepSort_Pytorch使用ZQPei行人模型的方法
-
快速使用Mobilenet SSD进行训练VOC格式的数据集 1.训练步骤STEP1:下载代码并配置环境下载代码git clone https://github.com/lufficc/SSD.git cd SSD修改requirements.txttorch==1.5 torchvision==0.5 yacs tqdm opencv-python vizer根据requirements.txt完成环境配置# Required packages: torch torchvision yacs tqdm opencv-python vizer conda create -n ssd-lufficc python=3.8 pip install -r requirements.txt额外补充安装pip install tensorboardX pip install sixSTEP2:在当前目录下建立数据集文件夹的软连接或者复制数据集到当前文件夹完成后文件夹结构├──VOC_data/VOC2007/ ├── Annotations #可以采用软连接的方式避免对大量数据进行复制 ├──放置xml文件 #TODO ├── JPEGImages ├──放置img文件 #TODO ├──ImageSets/Main #可以采用软连接的方式避免对大量数据进行复制 ├── split.py #数据分割脚本,用于生成训练索引文件split.py文件内容import os import random random.seed(0) xmlfilepath=r'./Annotations' saveBasePath=r"./ImageSets/Main/" trainval_percent=0.9 # 可以自己设置 train_percent=0.9 # 可以自己设置 temp_xml = os.listdir(xmlfilepath) total_xml = [] for xml in temp_xml: if xml.endswith(".xml"): total_xml.append(xml) num=len(total_xml) list=range(num) tv=int(num*trainval_percent) tr=int(tv*train_percent) trainval= random.sample(list,tv) train=random.sample(trainval,tr) print("train and val size",tv) print("traub suze",tr) ftrainval = open(os.path.join(saveBasePath,'trainval.txt'), 'w') ftest = open(os.path.join(saveBasePath,'test.txt'), 'w') ftrain = open(os.path.join(saveBasePath,'train.txt'), 'w') fval = open(os.path.join(saveBasePath,'val.txt'), 'w') for i in list: name=total_xml[i][:-4]+'\n' if i in trainval: ftrainval.write(name) if i in train: ftrain.write(name) else: fval.write(name) else: ftest.write(name) ftrainval.close() ftrain.close() fval.close() ftest .close()python split.py配置文件根目录的环境变量export VOC_ROOT="./VOC_data" #/path/to/voc_rootSTEP3:修改配置文件 vim configs/mobilenet_v2_ssd320_voc0712.yamlMODEL: NUM_CLASSES: 11 # 修改NUM_CLASSES BOX_HEAD: PREDICTOR: 'SSDLiteBoxPredictor' BACKBONE: NAME: 'mobilenet_v2' OUT_CHANNELS: (96, 1280, 512, 256, 256, 64) PRIORS: FEATURE_MAPS: [20, 10, 5, 3, 2, 1] STRIDES: [16, 32, 64, 107, 160, 320] MIN_SIZES: [60, 105, 150, 195, 240, 285] MAX_SIZES: [105, 150, 195, 240, 285, 330] ASPECT_RATIOS: [[2, 3], [2, 3], [2, 3], [2, 3], [2, 3], [m2, 3]] BOXES_PER_LOCATION: [6, 6, 6, 6, 6, 6] INPUT: IMAGE_SIZE: 320 DATASETS: TRAIN: ("voc_2007_trainval", "voc_2012_trainval") # TODO TEST: ("voc_2007_test", ) SOLVER: MAX_ITER: 120000 LR_STEPS: [80000, 100000] GAMMA: 0.1 BATCH_SIZE: 32 LR: 1e-3 OUTPUT_DIR: 'outputs/mobilenet_v2_ssd320_voc0712STEP4:修改类别信息vim ssd/data/datasets/voc.pyclass VOCDataset(torch.utils.data.Dataset): class_names = ('person','bridgevehicle','luggagevehicle','plane','refuelvehicle','foodvehicle','rubbishvehicle','watervehicle','platformvehicle','tractorvehicle','bridgeconnector') # 改成自己的class注意,类名必须小写 ······STEP5: 模型训练修改默认所用的device和batch_size vim ssd/config/defaults.py# 修改以下内容 _C.MODEL.DEVICE = "cuda:1" # cpu/cuda/cuda:1 _C.SOLVER.BATCH_SIZE = 128 _C.TEST.BATCH_SIZE = 32单GPU# for example, train SSD300: python train.py --config-file configs/mobilenet_v2_ssd320_voc0712.yaml多GPU# for example, train SSD300 with 2 GPUs: export NGPUS=2 python -m torch.distributed.launch --nproc_per_node=$NGPUS train.py --config-file configs/mobilenet_v2_ssd320_voc0712.yaml SOLVER.WARMUP_FACTOR 0.03333 SOLVER.WARMUP_ITERS 10002.模型评估单GPU# for example, evaluate SSD300: python test.py --config-file configs/mobilenet_v2_ssd320_voc0712.yaml多GPU# for example, evaluate SSD300 with 2 GPUs: export NGPUS=2 python -m torch.distributed.launch --nproc_per_node=$NGPUS test.py --config-file configs/mobilenet_v2_ssd320_voc0712.yaml3.模型调用(预测)#TODO参考资料https://github.com/qfgaohao/pytorch-ssd
-
快速使用Yolov4-tiny训练VOC格式的数据集 1.训练步骤STEP1:下载代码并配置环境git clone https://github.com/bubbliiiing/yolov4-tiny-pytorch.git cd yolov4-tiny-pytorch pip install -r requirements.txtSTEP2:根据文件结构填充VOC格式的数据集数据放置格式(只需完成#TODO部分即可)├──VOCdevkit/VOC2007/ ├── Annotations #可以采用软连接的方式避免对大量数据进行复制 ├──放置xml文件 #TODO ├── JPEGImages ├──放置img文件 #TODO ├──ImageSets/Main #可以采用软连接的方式避免对大量数据进行复制 ├──放置训练索引文件 (无需手动完成,自动生成) ├── voc2yolo.py #数据分割脚本,用于生成训练索引文件编辑voc2yolo.py。设置tarin\val\test数据分割比例#----------------------------------------------------------------------# # 验证集的划分在train.py代码里面进行 # test.txt和val.txt里面没有内容是正常的。训练不会使用到。 #----------------------------------------------------------------------# ''' #--------------------------------注意----------------------------------# 如果在pycharm中运行时提示: FileNotFoundError: [WinError 3] 系统找不到指定的路径。: './VOCdevkit/VOC2007/Annotations' 这是pycharm运行目录的问题,最简单的方法是将该文件复制到根目录后运行。 可以查询一下相对目录和根目录的概念。在VSCODE中没有这个问题。 #--------------------------------注意----------------------------------# ''' import os import random random.seed(0) xmlfilepath=r'./Annotations' saveBasePath=r"./ImageSets/Main/" #----------------------------------------------------------------------# # 想要增加测试集修改trainval_percent # train_percent不需要修改 #----------------------------------------------------------------------# trainval_percent=0.9 train_percent=1 temp_xml = os.listdir(xmlfilepath) total_xml = [] for xml in temp_xml: if xml.endswith(".xml"): total_xml.append(xml) num=len(total_xml) list=range(num) tv=int(num*trainval_percent) tr=int(tv*train_percent) trainval= random.sample(list,tv) train=random.sample(trainval,tr) print("train and val size",tv) print("traub suze",tr) ftrainval = open(os.path.join(saveBasePath,'trainval.txt'), 'w') ftest = open(os.path.join(saveBasePath,'test.txt'), 'w') ftrain = open(os.path.join(saveBasePath,'train.txt'), 'w') fval = open(os.path.join(saveBasePath,'val.txt'), 'w') for i in list: name=total_xml[i][:-4]+'\n' if i in trainval: ftrainval.write(name) if i in train: ftrain.write(name) else: fval.write(name) else: ftest.write(name) ftrainval.close() ftrain.close() fval.close() ftest .close()生成训练索引文件python voc2yolo.pySTEP3:对VOC数据集将进行类别统计├──VOCdevkit/VOC2007/ ├── get_all_class.py #VOC类别统计脚本在其中写入以下内容import xmltodict import os # VOC xml文件所在文件夹 annotation_dir="./Annotations/" label_list = list() # 逐一处理xml文件 for file in os.listdir(annotation_dir): annotation_path = os.path.join(annotation_dir,file) # 读取xml文件 with open(annotation_path,'r') as f: xml_str = f.read() #转为字典 xml_dic = xmltodict.parse(xml_str) # 获取label并去重加入到label_list objects = xml_dic["annotation"]["object"] if isinstance(objects,list): # xml文件中包含多个object for obj in objects: label = obj['name'] if label not in label_list: label_list.append(label) else:# xml文件中只包含1个object obj = objects label = obj['name'] if label not in label_list: label_list.append(label) print(label_list)然后运行get_all_class.py获取所有的类别信息['Person', 'BridgeVehicle', 'LuggageVehicle', 'Plane', 'RefuelVehicle', 'FoodVehicle', 'RubbishVehicle', 'WaterVehicle', 'PlatformVehicle', 'TractorVehicle', 'BridgeConnector']STEP4:编辑model_data/voc_classes.txt 和下载权重文件将其中的类别数改为自己的,文件内容为Person BridgeVehicle LuggageVehicle Plane RefuelVehicle FoodVehicle RubbishVehicle WaterVehicle PlatformVehicle TractorVehicle BridgeConnector下载权重文件到model_data文件夹下wget https://github.com/bubbliiiing/yolov4-tiny-pytorch/releases/download/v1.0/yolov4_tiny_weights_coco.pthSTEP4:生成最终训练所需的txt文件然后运行voc_annotation.pypython voc_annotation.py此时会生成对应的2007_train.txt,每一行对应其图片位置及其真实框的位置。STEP5:修改train.py的NUM_CLASSSES将train.py的NUM_CLASSSES修改成所需要分的类的个数(不需要+1)STEP6:开始训练python train.py2.模型预测在yolo.py文件里面,在如下部分修改model_path和classes_path使其对应训练好的文件;model_path对应logs文件夹下面的权值文件,classes_path是model_path对应分的类。_defaults = { #--------------------------------------------------------------------------# # 使用自己训练好的模型进行预测一定要修改model_path和classes_path! # model_path指向logs文件夹下的权值文件,classes_path指向model_data下的txt # 如果出现shape不匹配,同时要注意训练时的model_path和classes_path参数的修改 #--------------------------------------------------------------------------# "model_path" : 'model_data/yolov4_tiny_weights_coco.pth', "classes_path" : 'model_data/coco_classes.txt', #---------------------------------------------------------------------# # anchors_path代表先验框对应的txt文件,一般不修改。 # anchors_mask用于帮助代码找到对应的先验框,一般不修改。 #---------------------------------------------------------------------# "anchors_path" : 'model_data/yolo_anchors.txt', "anchors_mask" : [[3,4,5], [1,2,3]], #-------------------------------# # 所使用的注意力机制的类型 # phi = 0为不使用注意力机制 # phi = 1为SE # phi = 2为CBAM # phi = 3为ECA #-------------------------------# "phi" : 0, #---------------------------------------------------------------------# # 输入图片的大小,必须为32的倍数。 #---------------------------------------------------------------------# "input_shape" : [416, 416], #---------------------------------------------------------------------# # 只有得分大于置信度的预测框会被保留下来 #---------------------------------------------------------------------# "confidence" : 0.5, #---------------------------------------------------------------------# # 非极大抑制所用到的nms_iou大小 #---------------------------------------------------------------------# "nms_iou" : 0.3, #---------------------------------------------------------------------# # 该变量用于控制是否使用letterbox_image对输入图像进行不失真的resize, # 在多次测试后,发现关闭letterbox_image直接resize的效果更好 #---------------------------------------------------------------------# "letterbox_image" : False, #-------------------------------# # 是否使用Cuda # 没有GPU可以设置成False #-------------------------------# "cuda" : True, }运行predict.py,输入待测试的图片路径img/street.jpg在predict.py里面进行设置可以进行fps测试和video视频检测。3.评估自己的数据集前往get_map.py文件修改classes_path,classes_path用于指向检测类别所对应的txt,这个txt和训练时的txt一样。评估自己的数据集必须要修改。在yolo.py里面修改model_path以及classes_path。model_path指向训练好的权值文件,在logs文件夹里。classes_path指向检测类别所对应的txt。运行get_map.py即可获得评估结果,评估结果会保存在map_out文件夹中。参考资料https://github.com/bubbliiiing/yolov4-tiny-pytorch
-
快速使用Faster RCNN进行训练VOC格式的数据集 训练步骤STEP1:下载代码并配置环境git clone https://github.com/bubbliiiing/faster-rcnn-pytorch.git cd faster-rcnn-pytorch pip install -r requirements.txtSTEP2:根据文件结构填充VOC格式的数据集数据放置格式(只需完成#TODO部分即可)├──VOCdevkit/VOC2007/ ├── Annotations ├──放置xml文件 #TODO ├── JPEGImages ├──放置img文件 #TODO ├──ImageSets/Main ├──放置训练索引文件 (无需手动完成,自动生成) ├── voc2frcnn.py #数据分割脚本,用于生成训练索引文件编辑voc2frcnn.py。设置tarin\val\test数据分割比例#----------------------------------------------------------------------# # 想要增加测试集修改trainval_percent # train_percent不需要修改 #----------------------------------------------------------------------# trainval_percent=1 train_percent=1生成训练索引文件python voc2frcnn.pySTEP3:生成最终训练所需的txt文件编辑根目录下的voc_annotation.py,将classes改成你自己的classes(注意不要使用中文标签,文件夹中不要有空格!)classes = ["aeroplane", "bicycle", "bird", "boat", "bottle", "bus", "car", "cat", "chair", "cow", "diningtable", "dog", "horse", "motorbike", "person", "pottedplant", "sheep", "sofa", "train", "tvmonitor"]然后运行voc_annotation.pypython voc_annotation.py此时会生成对应的2007_train.txt,每一行对应其图片位置及其真实框的位置。STEP4:编辑model_data/voc_classes.txt将其中的类别数改为自己的,文件内容为cat dog ...STEP5:修改train.py的NUM_CLASSSES将train.py的NUM_CLASSSES修改成所需要分的类的个数(不需要+1)STEP6:开始训练python train.pySTEP7:模型效果评估评估过程可参考视频https://www.bilibili.com/video/BV1zE411u7Vw参考资料https://github.com/bubbliiiing/faster-rcnn-pytorch
-
快速使用YOLOv5进行训练VOC格式的数据集 训练步骤STEP1:下载官方YOLOv5的代码并配置环境git clone https://github.com/ultralytics/yolov5 cd yolov5 pip install -r requirements.txtSTEP2:准备VOC格式的数据集数据放置格式├──train_data_VOC ├── Annotations ├──放置xml文件 ├── JPEGImages ├──防止img文件STEP3:将数据集转为YOLOv5所需要的COCO格式mkdir train_data_COCO vim VOC2COCO.pyimport os import shutil import random import xmltodict from progressbar import * #================================================================================================================ # 函数定义区 # 函数-将voc xml中的object转化为对应的一条yolo数据 def get_yolo_data(obj,img_width,img_height): # 获取voc格式的数据信息 name = obj['name'] xmin = float(obj['bndbox']['xmin']) xmax = float(obj['bndbox']['xmax']) ymin = float(obj['bndbox']['ymin']) ymax = float(obj['bndbox']['ymax']) # 计算yolo格式的数据信息 class_idx = class_names.index(name) x_center,y_center = (xmin+xmax)/2,(ymin+ymax)/2 box_width = xmax - xmin box_height = ymax - ymin yolo_data = "{} {} {} {} {}\n".format(class_idx,x_center/img_width,y_center/img_height,box_width/img_width,box_height/img_height) return yolo_data # 函数-将xml文件转为txt文件 def convert_annotations(image_name): in_file = xml_file_path + image_name + '.xml' out_file = txt_file_path + image_name + '.txt' yolo_data = "" with open(in_file) as f: xml_str = f.read() # 转为字典 xml_dic = xmltodict.parse(xml_str) # 获取图片的width、height img_width = float(xml_dic["annotation"]["size"]["width"]) img_height = float(xml_dic["annotation"]["size"]["height"]) # 获取xml文件中的object objects = xml_dic["annotation"]["object"] if isinstance(objects,list): # xml文件中包含多个object for obj in objects: yolo_data += get_yolo_data(obj,img_width,img_height) else: # xml文件中包含1个object obj = objects yolo_data += get_yolo_data(obj,img_width,img_height) with open(out_file,'w') as f: f.write(yolo_data) # 函数-创建最终用于训练的COCO格式数据集的文件夹 def create_dir(): if not os.path.exists('train_data_COCO/images/'): os.makedirs('train_data_COCO/images/') if not os.path.exists('train_data_COCO/labels/'): os.makedirs('train_data_COCO/labels/') if not os.path.exists('train_data_COCO/images/train/'): os.makedirs('train_data_COCO/images/train') if not os.path.exists('train_data_COCO/images/val/'): os.makedirs('train_data_COCO/images/val/') if not os.path.exists('train_data_COCO/images/test/'): os.makedirs('train_data_COCO/images/test/') if not os.path.exists('train_data_COCO/labels/train/'): os.makedirs('train_data_COCO/labels/train/') if not os.path.exists('train_data_COCO/labels/val/'): os.makedirs('train_data_COCO/labels/val/') if not os.path.exists('train_data_COCO/labels/test/'): os.makedirs('train_data_COCO/labels/test/') return #================================================================================================================ # 功能实现区 """ STEP1:准备工作:数据准备+创建各种所需的文件夹 """ # 对应的VOC数据集的路径参数+类别参数 xml_file_path = './train_data_VOC/Annotations/' # 检查和自己的xml文件夹名称是否一致 images_file_path = './train_data_VOC/JPEGImages/' # 检查和自己的图像文件夹名称是否一致 class_names = ['Person', 'BridgeVehicle', 'LuggageVehicle', 'Plane', 'RefuelVehicle', 'FoodVehicle', 'RubbishVehicle', 'WaterVehicle', 'PlatformVehicle', 'TractorVehicle'] # 创一个临时文件夹用来存放xml文件转换出来的对应的txt文件 if not os.path.exists('train_data_COCO/temp_labels/'): os.makedirs('train_data_COCO/temp_labels/') txt_file_path = 'train_data_COCO/temp_labels/' # 执行xml到txt的转换,存储到一个临时文件夹 total_xml = os.listdir(xml_file_path) num_xml = len(total_xml) # XML文件总数 for i in range(num_xml): name = total_xml[i][:-4] convert_annotations(name) # 创建COCO格式的数据所需要的各种文件夹 create_dir() # 读取所有的txt文件 total_txt = os.listdir(txt_file_path) print("数据准备工作完成,开始进行数据分配") """ STEP2:数据分配:按比例对数据集进行划分 """ # 设置数据集划分比例,训练集75%,验证集15%,测试集15% train_percent = 0.8 val_percent = 0.15 test_percent = 0.05 # 计算train,val,test每一类的数据数量 num_txt = len(total_txt) num_train = int(num_txt * train_percent) num_val = int(num_txt * val_percent) num_test = num_txt - num_train - num_val # 根据计算出的每类的数据数量计算出进行数据分配的索引 list_all_txt = range(num_txt) # 范围 range(0, num) train = random.sample(list_all_txt, num_train)# train从list_all_txt取出num_train个元素 val_test = [i for i in list_all_txt if not i in train]# 所以list_all_txt列表只剩下了这些元素:val_test val = random.sample(val_test, num_val)# 再从val_test取出num_val个元素,val_test剩下的元素就是test # 根据采样的索引结果进行文件分配工作 print("训练集数目:{}, 验证集数目:{},测试集数目:{}".format(len(train), len(val), len(val_test) - len(val))) #进度条功能 widgets = ['VOC2COCO: ',Percentage(), ' ', Bar('#'),' ', Timer(),' ', ETA()] pbar = ProgressBar(widgets=widgets, maxval=num_txt).start() count = 0 for i in list_all_txt: name = total_txt[i][:-4] srcImage = images_file_path + name + '.jpg' srcLabel = txt_file_path + name + '.txt' if i in train: dst_train_Image = 'train_data_COCO/images/train/' + name + '.jpg' dst_train_Label = 'train_data_COCO/labels/train/' + name + '.txt' shutil.copyfile(srcImage, dst_train_Image) shutil.copyfile(srcLabel, dst_train_Label) elif i in val: dst_val_Image = 'train_data_COCO/images/val/' + name + '.jpg' dst_val_Label = 'train_data_COCO/labels/val/' + name + '.txt' shutil.copyfile(srcImage, dst_val_Image) shutil.copyfile(srcLabel, dst_val_Label) else: dst_test_Image = 'train_data_COCO/images/test/' + name + '.jpg' dst_test_Label = 'train_data_COCO/labels/test/' + name + '.txt' shutil.copyfile(srcImage, dst_test_Image) shutil.copyfile(srcLabel, dst_test_Label) #更新进度条 count += 1 pbar.update(count) #释放进度条 pbar.finish() print("数据分配工作完成,开始释放临时文") """ STEP3:释放临时文件 """ shutil.rmtree(txt_file_path) print("临时文件释放完成,VOC2COCO执行结束")python VOC2COCO.pySTEP4:在data下创建与数据对应的data.yaml文件文件内容按照数据的数据情况填写path: train_data_COCO # root train: # train images (relative to 'path') - images/train val: # val images (relative to 'path') - images/val test: # test images (optional) - images/test # Classes nc: 10 # number of classes names: ['Person', 'BridgeVehicle', 'LuggageVehicle', 'Plane', 'RefuelVehicle', 'FoodVehicle', 'RubbishVehicle', 'WaterVehicle', 'PlatformVehicle', 'TractorVehicle'] # class namesSTEP5:下载预训练模型mkdir weights cd weights wget https://github.com/ultralytics/yolov5/releases/download/v5.0/yolov5s.ptSTEP6:开始训练python train.py --data data/data.yaml --cfg models/yolov5s.yaml --weights weights/yolov5s.pt --batch-size 64 --epochs 60 参考资料https://github.com/ultralytics/yolov5
![[视频目标检测]:使用MEGA|DFF|FGFA训练自己的数据集](https://blog.inat.top/usr/themes/Joe/assets/thumb/7.jpg)