搜索到
372
篇与
的结果
-
 图像padding为正方形并绘制网格(python+opencv实现) 代码实现import matplotlib.pyplot as plt import cv2 import numpy as np img = cv2.imread("./demo.jpg") """ 图像padding为正方形 """ def square_img(img_cv): # 获取图像的宽高 img_h,img_w = img_cv.shape[0:2] # 计算padding值并将图像padding为正方形 padw,padh = 0,0 if img_h>img_w: padw = (img_h - img_w) // 2 img_pad = np.pad(img_cv,((0,0),(padw,padw),(0,0)),'constant',constant_values=0) elif img_w>img_h: padh = (img_w - img_h) // 2 img_pad = np.pad(img_cv,((padh,padh),(0,0),(0,0)), 'constant', constant_values=0) return img_pad """ 在图像上绘制网格 核心函数 cv2.line(img, (start_x, start_y), (end_x, end_y), (255, 0, 0), 1, 1) """ def draw_grid(img,grid_x,grid_y,line_width=5): img_x,img_y = img.shape[:2] # 绘平行y方向的直线 dx = int(img_x/grid_x) for i in range(0,img_x,dx): cv2.line(img, (i, 0), (i, img_y), (255, 0, 0), line_width) # 绘平行x方向的直线 dy = int(img_y/grid_y) for i in range(0,img_x,dx): cv2.line(img, (0, i), (img_x, i), (255, 0, 0), line_width) return img img = square_img(img) img = draw_grid(img,20,20) # 20,20为网格的shape img = cv2.cvtColor(img,cv2.COLOR_BGR2RGB) plt.figure(dpi=200) plt.xticks([]) plt.yticks([]) plt.imshow(img) plt.show()调用效果代码参数需要稍作修改才能得到如下全部效果
图像padding为正方形并绘制网格(python+opencv实现) 代码实现import matplotlib.pyplot as plt import cv2 import numpy as np img = cv2.imread("./demo.jpg") """ 图像padding为正方形 """ def square_img(img_cv): # 获取图像的宽高 img_h,img_w = img_cv.shape[0:2] # 计算padding值并将图像padding为正方形 padw,padh = 0,0 if img_h>img_w: padw = (img_h - img_w) // 2 img_pad = np.pad(img_cv,((0,0),(padw,padw),(0,0)),'constant',constant_values=0) elif img_w>img_h: padh = (img_w - img_h) // 2 img_pad = np.pad(img_cv,((padh,padh),(0,0),(0,0)), 'constant', constant_values=0) return img_pad """ 在图像上绘制网格 核心函数 cv2.line(img, (start_x, start_y), (end_x, end_y), (255, 0, 0), 1, 1) """ def draw_grid(img,grid_x,grid_y,line_width=5): img_x,img_y = img.shape[:2] # 绘平行y方向的直线 dx = int(img_x/grid_x) for i in range(0,img_x,dx): cv2.line(img, (i, 0), (i, img_y), (255, 0, 0), line_width) # 绘平行x方向的直线 dy = int(img_y/grid_y) for i in range(0,img_x,dx): cv2.line(img, (0, i), (img_x, i), (255, 0, 0), line_width) return img img = square_img(img) img = draw_grid(img,20,20) # 20,20为网格的shape img = cv2.cvtColor(img,cv2.COLOR_BGR2RGB) plt.figure(dpi=200) plt.xticks([]) plt.yticks([]) plt.imshow(img) plt.show()调用效果代码参数需要稍作修改才能得到如下全部效果 -
-
linux下快速安装cmake步骤详解 安装步骤1.获cmake快速安装脚本下载地址https://cmake.org/download/下载对应系统.sh后缀的文件# 创建并进入软件安装目录 mkdir software && cd $_ # 下载快速安装脚本 wget https://github.com/Kitware/CMake/releases/download/v3.21.4/cmake-3.21.4-linux-x86_64.sh2.运行快速安装脚本安装bash cmake-3.21.4-linux-x86_64.sh3.配置环境变量vim ~/.bashrc # 在文件末尾加上这个--根据自己的实际安装路径填写 export PATH="$PATH:/home/admin/software/cmake-3.21.4-linux-x86_64/bin" # 激活环境变量 source ~/.bashrc4.验证是否安装成功$ cmake --version cmake version 3.21.4 CMake suite maintained and supported by Kitware (kitware.com/cmake).
-
python学习:正则表达式re模块的使用 1.常用常量1.1 re.I(re.IGNORECASE)执行不区分大小写的匹配;类似的表达式也[A-Z]将匹配小写字母。re.findall(r"[a-z]", "ah667GHD67DYT78") # Return:['a', 'h'] re.findall(r"[a-z]", "ah667GHD67DYT78",flags=re.IGNORECASE) # Return:['a', 'h', 'G', 'H', 'D', 'D', 'Y', 'T']1.2 re.S(re.DOTALL)使'.'特殊字符与任何字符都匹配,包括换行符;没有此标志,'.'将匹配除换行符以外的任何内容。s = '''first line second line third line''' re.findall(r".+", s) # Return:['first line', 'second line', 'third line'] re.findall(r".+", s, flags=re.DOTALL) # Return:['first line\nsecond line\nthird line']2.常用方法2.1 re.match(pattern,string,flags = 0 )对字符串从开头进行正则匹配 (匹配零个或者一个对象)如果字符串与模式匹配,则返回相应的匹配对象。re.match('a','abcade') # Return:<re.Match object; span=(0, 1), match='a'> re.match('\w+','abc123de') # Return:<re.Match object; span=(0, 8), match='abc123de'>如果字符串与模式不匹配,则返回None;re.match('z','abcade') # Return:None可以使用group()获取匹配结果re.match('a','abcade').group() # Return:'a'2.2 re.search(pattern,string,flags = 0 )扫描字符串以查找正则表达式模式产生匹配项的第一个位置(匹配零个或者一个对象),与re.match的区别re.match是从字符串的开头进行匹配re.search是从对字符串的挨个位置都进行尝试,指导匹配上或者尝试完所有位置如果匹配上,则返回相应的match对象。re.search('b','abcade') # Return:<re.Match object; span=(1, 2), match='b'> re.search('b','abcade').group() # Return:'b'如果字符串中没有位置与模式匹配,则返回None;re.search('z','abcade') # Return:None2.3 re.compile(pattern,flags = 0 )该方法同re.match和re.search将正则表达式模式编译为正则表达式对象,可使用match(),search()以及下面所述的其他方法将其用于匹配reg = re.compile('\d{2}') # 正则对象-匹配两个数字 reg.search('12abc') # Return:<re.Match object; span=(0, 2), match='12'> reg.search('12abc').group() # Return:12reg = re.compile('\d{2}') # 正则对象-匹配两个数字 reg.match('123abc') # Return:<re.Match object; span=(0, 2), match='12'> reg.match('12abc').group() # Return:122.4 re.fullmatch(pattern,string,flags = 0 )如果整个字符串与正则表达式模式匹配,则返回相应的match对象。re.fullmatch('\w+','abcade') # Return:<re.Match object; span=(0, 6), match='abcade'> re.fullmatch('\w+','abcade').group() # Return:'abcade'否则返回None;re.fullmatch('\w+','abca de') # Return:None2.5 re.split(pattern,string,maxsplit = 0,flags = 0 )通过正则表达式来split字符串。re.split(r'\W+', 'Words, words, words.') # Return:['Words', 'words', 'words', '']如果在pattern中使用了捕获括号,那么模式中所有组的文本也将作为结果列表的一部分返回。re.split(r'(\W+)', 'Words, words, words.') # Return:['Words', ', ', 'words', ', ', 'words', '.', '']如果分隔符中有捕获组,并且该匹配组在字符串的开头匹配,则结果将从空字符串开始。字符串的末尾也是如此:re.split(r'(\W+)', '...words, words...') # Return:['', '...', 'words', ', ', 'words', '...', '']如果maxsplit不为零,则最多会发生maxsplit分割,并将字符串的其余部分作为列表的最后一个元素返回。re.split(r'\W+', 'Words, words, words.',1) # Return:['Words', 'words, words.']2.6 re.findall(pattern,string,flags = 0 )从左到右扫描该字符串,以列表的形式返回所有的匹配项re.findall('a', 'This is a beautiful place!') # Return:['a', 'a', 'a'] re.findall('z', 'This is a beautiful place!') # Return:[]2.7 re.sub(pattern,repl,string,count = 0,flags = 0 )使用repl替换掉string中pattern成功匹配的匹配项,count参数表示将匹配到的内容进行替换的次数re.sub('\d', 'S', 'abc12jh45li78') #将匹配到所有的数字替换成S # Return:'abcSSjhSSliSS' re.sub('\d', 'S', 'abc12jh45li78', 2) #将匹配到的数字替换成S,只替换2次就停止 # Return:'abcSSjh45li78'如果找不到该模式, 则返回的字符串不变。re.sub('z', 'S', 'abc12jh45li78') # Return:'abc12jh45li78'2.8 re.subn(pattern,repl,string,count = 0,flags = 0 )执行与相同的操作sub(),但返回一个元组。(new_string, number_of_subs_made)re.subn('\d', 'S', 'abc12jh45li78') # Return:('abcSSjhSSliSS', 6) re.subn('\d', 'S', 'abc12jh45li78', 3) # Return:('abcSSjhS5li78', 3)3. 其他补充3.1 使用正则表达式匹配中文 re.findall(r"[\u4e00-\u9fa5]", "沿charlie在charlie五前等待。charlie charlie五前等四川八八六四") # Return:['沿', '在', '五', '前', '等', '待', '五', '前', '等', '四', '川', '八', '八', '六', '四']3.2 贪心匹配和非贪心匹配贪心匹配:正则表达式在有二义的情况下,会尽可能匹配最长的字符串Python的正则表达式默认是”贪心“的,这表示在有二义的情况下,会尽可能匹配最长的字符串。re.search(r'(ha){3,5}','hahahahaha').group() # Return:'hahahahaha'非贪心匹配:匹配尽可能最短的字符串使用方式:在有二义的正则表达式的后面跟一个问号re.search(r'(ha){3,5}?','hahahahaha').group() # Return:'hahaha'参考资料使用正则表达式Python之re模块python 正则表达式详解
-
java学习:BigDecimal的使用 1、简介Java在java.math包中提供的API类BigDecimal,用来对超过16位有效位的数进行精确的运算。双精度浮点型变量double可以处理16位有效数。在实际应用中,需要对更大或者更小的数进行运算和处理。float和double只能用来做科学计算或者是工程计算,在商业计算中要用java.math.BigDecimal(原因见下文)。BigDecimal所创建的是对象,我们不能使用传统的+、-、*、/等算术运算符直接对其对象进行数学运算,而必须调用其相对应的方法。方法中的参数也必须是BigDecimal的对象。构造器是类的特殊方法,专门用来创建对象,特别是带有参数的对象。2、基本使用2.0 头文件导入import java.math.BigDecimal;2.1 Bigdecimal的初始化构造器描述BigDecimal(int) //创建一个具有参数所指定整数值的对象。 BigDecimal(double) //创建一个具有参数所指定双精度值的对象。 //不推荐使用 BigDecimal(long) //创建一个具有参数所指定长整数值的对象。 BigDecimal(String) //创建一个具有参数所指定以字符串表示的数值的对象。//推荐使用示例BigDecimal num3 = new BigDecimal(100); BigDecimal num2 = new BigDecimal(10L); BigDecimal num1 = new BigDecimal(0.005);//不推荐BigDecimal(double) //尽量用字符串的形式初始化 BigDecimal num12 = new BigDecimal("0.005"); BigDecimal num22 = new BigDecimal("10000"); BigDecimal num32 = new BigDecimal("-1000");为什么BigDecimal(double)不推荐使用+在商业计算中要用java.math.BigDecimal示例代码import java.math.BigDecimal; public class Solution { public static void main(String[] args){ BigDecimal doubleStr = new BigDecimal(1.11111111); System.out.println(doubleStr); } }运行结果C:\Users\itrb\Desktop\java>javac Solution.java C:\Users\itrb\Desktop\java>java Solution 1.111111109999999957409499984350986778736114501953125分析根本原因是:十进制值通常没有完全相同的二进制表示形式;十进制数的二进制表示形式可能不精确。只能无限接近于那个值但是,在项目中,我们不可能让这种情况出现,特别是金融项目,因为涉及金额的计算都必须十分精确,你想想,如果你的支付宝账户余额显示193.99999999999998,那是一种怎么样的体验?这也是在商业计算中要用java.math.BigDecimal的原因2.2 BigDecimal转回基本类型APItoString() //将BigDecimal对象的数值转换成字符串。 doubleValue() //将BigDecimal对象中的值以双精度数返回。 floatValue() //将BigDecimal对象中的值以单精度数返回。 longValue() //将BigDecimal对象中的值以长整数返回。 intValue() //将BigDecimal对象中的值以整数返回。2.3 Bigdecimal的基本运算APIadd(BigDecimal) //BigDecimal对象中的值相加,然后返回这个对象。 subtract(BigDecimal) //BigDecimal对象中的值相减,然后返回这个对象。 multiply(BigDecimal) //BigDecimal对象中的值相乘,然后返回这个对象。 divide(BigDecimal) //BigDecimal对象中的值相除,然后返回这个对象。 示例//加法 BigDecimal result1 = num1.add(num2); BigDecimal result12 = num12.add(num22); //减法 BigDecimal result2 = num1.subtract(num2); BigDecimal result22 = num12.subtract(num22); //乘法 BigDecimal result3 = num1.multiply(num2); BigDecimal result32 = num12.multiply(num22); //绝对值 BigDecimal result4 = num3.abs(); BigDecimal result42 = num32.abs(); //除法 BigDecimal result5 = num2.divide(num1,20,BigDecimal.ROUND_HALF_UP); BigDecimal result52 = num22.divide(num12,20,BigDecimal.ROUND_HALF_UP);备注如果进行除法运算的时候,结果不能整除,有余数,这个时候会报java.lang.ArithmeticException:这边要避免这个错误产生,在进行除法运算的时候,针对可能出现的小数产生的计算,必须要多传两个参数divide(BigDecimal,保留小数点后几位小数,舍入模式)舍入模式ROUND_CEILING //向正无穷方向舍入 ROUND_DOWN //向零方向舍入 ROUND_FLOOR //向负无穷方向舍入 ROUND_HALF_DOWN //向(距离)最近的一边舍入,除非两边(的距离)是相等,如果是这样,向下舍入, 例如1.55 保留一位小数结果为1.5 ROUND_HALF_EVEN //向(距离)最近的一边舍入,除非两边(的距离)是相等,如果是这样,如果保留位数是奇数,使用ROUND_HALF_UP,如果是偶数,使用ROUND_HALF_DOWN ROUND_HALF_UP //向(距离)最近的一边舍入,除非两边(的距离)是相等,如果是这样,向上舍入, 1.55保留一位小数结果为1.6,也就是我们常说的“四舍五入” ROUND_UNNECESSARY //计算结果是精确的,不需要舍入模式 ROUND_UP //向远离0的方向舍入需要对BigDecimal进行截断和四舍五入可用setScale方法import java.math.BigDecimal; public class Solution { public static void main(String[] args){ BigDecimal a = new BigDecimal("2.3366"); a = a.setScale(2,BigDecimal.ROUND_HALF_UP); //保留2位有效数字,且四舍五入 System.out.println(a); } }C:\Users\itrb\Desktop\java λ javac Solution.java C:\Users\itrb\Desktop\java λ java Solution 2.342.3 BigDecimal 比较大小BigDecimal a = new BigDecimal (101); BigDecimal b = new BigDecimal (111); //使用compareTo方法比较 //注意:a、b均不能为null,否则会报空指针 if(a.compareTo(b) == -1){ System.out.println("a小于b"); } if(a.compareTo(b) == 0){ System.out.println("a等于b"); } if(a.compareTo(b) == 1){ System.out.println("a大于b"); } if(a.compareTo(b) > -1){ System.out.println("a大于等于b"); } if(a.compareTo(b) < 1){ System.out.println("a小于等于b"); }参考资料java 中 BigDecimal 详解BigDecimal 比较大小BigDecimal加减乘除计算
-
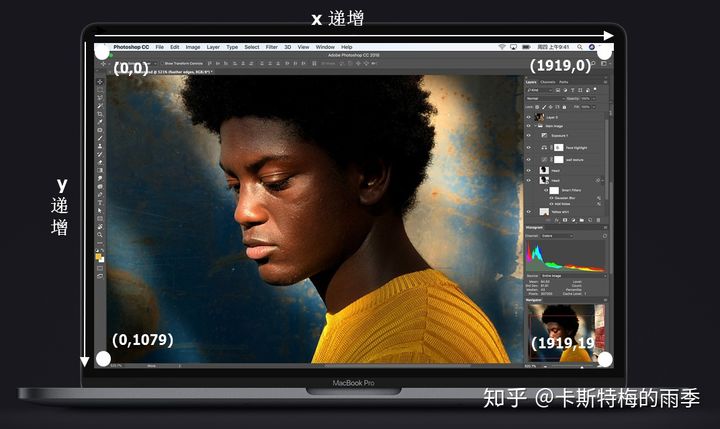
PyAutoGUI—通过python控制鼠标与键盘实现图形界面自动化 简介基本信息PyAutoGUI是一个Python语言的键鼠自动化库,简单来说和按键精灵的功能一样。但是因为是Python的类库,所以可以使用Python代码配合一些其他类库完成更加强大的功能坐标轴系统pyautogui的鼠标函数使用x,y坐标,原点在屏幕左上角,向右x坐标增加,向下y坐标增加,所有坐标都是正整数,没有负数坐标。如图所示:功能使用1.获取屏幕宽高pyautogui.size() #返回屏幕宽高像素数的元组 #例如,如果屏幕分辨率为1920*1080,那么左上角的坐标为(0,0), #右下角的坐标是(1919,1079)2.控制鼠标确定鼠标当前位置pyautogui.position() #确定鼠标当前位置,返回x,y坐标的元组移动pyautogui.moveTo(x,y[,duration = t]) # 将鼠标移动到屏幕指定位置, #x,y是目标位置的横纵坐标,duration指定鼠标光标移动到目标位置 #所需要的秒数,t可以为整数或浮点数,省略duration参数表示 #立即将光标移动到指定位置(在PyAutoGUI函数中,所有的duration #关键字参数都是可选的) #Attention:所有传入x,y坐标的地方,都可以用坐标x,y #的元组或列表替代,(x,y)/[x,y] pyautogui.moveRel(x,y[,duration = t]) #相对于当前位置移动光标, #这里的x,y不再是目标位置的坐标,而是偏移量, #如,pyautogui.moveRel(100,0,duration=0.25) #表示光标相对于当前所在位置向右移动100个像素点击:按下鼠标按键,然后放开,同时不移动位置pyautogui.mouseDown() #按下鼠标按键(左键) pyautogui.mouseUp() #释放鼠标按键(左键) pyautogui.click() #向计算机发送虚拟的鼠标点击(click()函数只是前面两个函数调用的方便封装) #默认在当前光标位置,使用鼠标左键点击 pyautogui.click([x,y,button='left/right/middle']) #在(x,y)处点击鼠标左键、右键、中键 #但不推荐使用这种方法,下面这种方法效果更好 #pyautogui.moveTo(x,y,duration=t) #pyautogui.click() pyautogui.doubleClick() #双击鼠标左键 pyautogui.rightClick() #单击鼠标右键 pyautogui.middleClick() #单击鼠标中键拖动:按住一个键不放,同时移动鼠标pyautogui.dragTo(x,y[,duration=t) #将鼠标拖动到指定位置 #x,y:x坐标,y坐标 pyautogui.dragRel(x,y[,duration=t]) #将鼠标拖动到相对当前位置的位置 #x,y:水平移动,垂直移动滚动pyautogui.scroll() #控制窗口上下滚动(滚动发生在鼠标的当前位置) #正数表示向上滚动,负数表示向下滚动, #滚动单位的大小需要具体尝试3.控制键盘输入字符串pyautogui.typewrite(s[,duration=t]) #向文本框发送字符串 #可选的duration参数在输入单个字符之间添加短暂的时间暂停 #Attention:只能用于输入英文输入键字符串不是所有的键都很容易用单个文本字符来表示。例如,如何把Shift键或左箭头键表示为单个字符串?在PyAutoGUI中,这些键表示为短的字符串值,如'esc'表示Esc键,'enter'表示Enter,我们把这些字符串称之为键字符串。pyautogui.typewrite([键盘键字符串]) #除了单个字符串,还可以向typewrite()函数传递键字符串的列表 #如 pyautogui.typewrite(['a','b','left','left','X','Y']) #按'a'键,'b'键,然后按左箭头两次,然后按'X'和'Y' #输出结果为XYab pyautogui.keyDown() #根据传入的键字符串,向计算机发送虚拟的按键(按下) pyautogui.keyUp() #根据传入的键字符串,向计算机发送虚拟的释放(释放) pyautogui.press() #前面两个函数的封装,模拟完整的击键(按下并释放)举例:pyautogui.keyDown('shift');pyautogui.press('4');pyautogui.keyUp('shift') #按下Shift,按下并释放4,然后释放Shift完整的键字符串如下:键盘键字符串 含义 'a','b','c','A','C','1','2','3', 单个字符的键 '!','@','#'等 'enter' 回车 ‘esc' ESC键 'shiftleft','shiftright' 左右Shift键 'altleft','altright' 左右Alt键 'ctrlleft','ctrlright' 左右Ctrl键 ‘tab'(or '\t') Tab键 'backspace','delete' Backspace键和Delete键 'pageup','pagedown' Page Up 和Page Down键 'home','end' Home键和End键 'up','down','left','right' 上下左右箭头键 'f1','f2','f3'等 F1至F12键 'volumemute','volumeup',volumedown' 静音,放大音量和减小音量键 'pause' 暂停键 'capslock','numlock','scrolllock' Caps Lock,Num Lock和 Scroll Lock键 'insert' Insert键 'printscreen' Prtsc或Print Screen键 'winleft','winright' 左右Win键(在windows上) 'command' Command键(在OS X上) 'option' Option键(在OS X上)快捷键组合pyautogui.hotkey() #接收多个字符串参数,顺序按下,再按相反的顺序释放举例:pyautogui.hotkey('ctrl','c') #按住Ctrl键,然后按C键,然后释放C键和Ctrl键 相当于 pyautogui.keyDown('ctrl') pyautogui.keyDown('c') pyautogui.keyUp('c') pyautogui.keyUp('ctrl')参考资料Python键鼠操作自动化库PyAutoGUI简介PyAutoGUI——图形用户界面自动化
-
Linux&Jetson Nano下编译安装ncnn 1.下载ncnn源码项目地址:https://github.com/Tencent/ncnngit clone https://github.com/Tencent/ncnn.git cd ncnn git submodule update --init2.安装依赖2.1 通用依赖gitg++cmakeprotocol buffer (protobuf) headers files and protobuf compilerglslangopencv(用于编译案列)sudo apt install build-essential git cmake libprotobuf-dev protobuf-compiler libvulkan-dev vulkan-utils libopencv-dev2.2 vulkan header files and loader library (用于调用GPU,只用CPU的可以不用安装)2.2.1 X86版本安装# 为GPU安装Vulkan驱动 sudo apt install mesa-vulkan-drivers # 安装vulkansdk wget https://sdk.lunarg.com/sdk/download/1.2.189.0/linux/vulkansdk-linux-x86_64-1.2.189.0.tar.gz?Human=true -O vulkansdk-linux-x86_64-1.2.189.0.tar.gz tar -xvf vulkansdk-linux-x86_64-1.2.189.0.tar.gz export VULKAN_SDK=$(pwd)/1.2.189.0/x86_642.2.2 Jetson Nano安装确认vulkan驱动是否安装正常nvidia@xavier:/$ vulkaninfo Xlib: extension "NV-GLX" missing on display "localhost:10.0". Xlib: extension "NV-GLX" missing on display "localhost:10.0". Xlib: extension "NV-GLX" missing on display "localhost:10.0". /build/vulkan-tools-WR7ZBj/vulkan-tools-1.1.126.0+dfsg1/vulkaninfo/vulkaninfo.h:399: failed with ERROR_INITIALIZATION_FAILED异常原因查找通过vnc远程连接到图形界面后运行vulkaninfonano@nano:~$ vulkaninfo =========== VULKAN INFO =========== Vulkan Instance Version: 1.2.70 Instance Extensions: ==================== Instance Extensions count = 16 VK_KHR_device_group_creation : extension revision 1 ······ ========================= minImageCount = 2 maxImageCount = 8 currentExtent: width = 256 height = 256 minImageExtent: width = 256 height = 256 maxImageExtent: width = 256 height = 256 maxImageArrayLayers = 1 ······安装vulkansdk# 编译安装vulkansdk sudo apt-get update && sudo apt-get install git build-essential libx11-xcb-dev libxkbcommon-dev libwayland-dev libxrandr-dev cmake git clone https://github.com/KhronosGroup/Vulkan-Loader.git cd Vulkan-Loader && mkdir build && cd build ../scripts/update_deps.py cmake -DCMAKE_BUILD_TYPE=Release -DVULKAN_HEADERS_INSTALL_DIR=$(pwd)/Vulkan-Headers/build/install .. make -j$(nproc) export LD_LIBRARY_PATH=$(pwd)/loader cd Vulkan-Headers ln -s ../loader lib export VULKAN_SDK=$(pwd)3. 开始编译CPU 版# 没安VULKAN运行这个 cd ncnn mkdir -p build cd build cmake -DCMAKE_BUILD_TYPE=Release -DNCNN_VULKAN=OFF -DNCNN_SYSTEM_GLSLANG=ON -DNCNN_BUILD_EXAMPLES=ON .. make -j$(nproc)GPU-X86# 有GPU安了VULKAN运行这个 cd ncnn mkdir -p build cd build cmake -DCMAKE_BUILD_TYPE=Release -DNCNN_VULKAN=ON -DNCNN_SYSTEM_GLSLANG=ON -DNCNN_BUILD_EXAMPLES=ON .. make -j$(nproc)GPU- Jetson Nano# Jetson Nano用这个 cd ncnn mkdir -p build cd build cmake -DCMAKE_TOOLCHAIN_FILE=../toolchains/jetson.toolchain.cmake -DNCNN_VULKAN=ON -DCMAKE_BUILD_TYPE=Release -DNCNN_BUILD_EXAMPLES=ON .. make -j$(nproc)4.验证安装4.1 验证squeezenetcd ../examples ../build/examples/squeezenet ../images/256-ncnn.pngnano@nano:/software/ncnn/examples$ ../build/examples/squeezenet ../images/256-ncnn.png [0 NVIDIA Tegra X1 (nvgpu)] queueC=0[16] queueG=0[16] queueT=0[16] [0 NVIDIA Tegra X1 (nvgpu)] bugsbn1=0 bugbilz=0 bugcopc=0 bugihfa=0 [0 NVIDIA Tegra X1 (nvgpu)] fp16-p/s/a=1/1/1 int8-p/s/a=1/1/1 [0 NVIDIA Tegra X1 (nvgpu)] subgroup=32 basic=1 vote=1 ballot=1 shuffle=1 532 = 0.168945 920 = 0.093323 716 = 0.063110 nvdc: start nvdcEventThread nvdc: exit nvdcEventThread4.1 验证benchncnncd ../benchmark ../build/benchmark/benchncnn 10 $(nproc) 0 0nano@nano:/software/ncnn/benchmark$ ../build/benchmark/benchncnn 10 $(nproc) 0 0[0 NVIDIA Tegra X1 (nvgpu)] queueC=0[16] queueG=0[16] queueT=0[16] [0 NVIDIA Tegra X1 (nvgpu)] bugsbn1=0 bugbilz=0 bugcopc=0 bugihfa=0 [0 NVIDIA Tegra X1 (nvgpu)] fp16-p/s/a=1/1/1 int8-p/s/a=1/1/1 [0 NVIDIA Tegra X1 (nvgpu)] subgroup=32 basic=1 vote=1 ballot=1 shuffle=1 loop_count = 10 num_threads = 4 powersave = 0 gpu_device = 0 cooling_down = 1 squeezenet min = 19.90 max = 22.82 avg = 20.82 squeezenet_int8 min = 36.58 max = 236.35 avg = 66.89 mobilenet min = 24.75 max = 41.05 avg = 28.83 mobilenet_int8 min = 42.95 max = 70.39 avg = 52.08 mobilenet_v2 min = 31.84 max = 38.09 avg = 35.59 mobilenet_v3 min = 29.77 max = 38.48 avg = 33.56 shufflenet min = 25.98 max = 36.90 avg = 30.86 shufflenet_v2 min = 18.46 max = 27.65 avg = 20.49 mnasnet min = 22.63 max = 35.37 avg = 24.88 proxylessnasnet min = 27.85 max = 33.44 avg = 30.52 efficientnet_b0 min = 34.85 max = 48.31 avg = 38.46 efficientnetv2_b0 min = 56.62 max = 76.70 avg = 61.99 regnety_400m min = 28.31 max = 35.59 avg = 31.92 blazeface min = 14.40 max = 34.70 avg = 23.63 googlenet min = 55.01 max = 75.36 avg = 60.89 googlenet_int8 min = 111.53 max = 315.94 avg = 167.58 resnet18 min = 51.45 max = 77.21 avg = 59.26 resnet18_int8 min = 81.99 max = 207.09 avg = 117.43 alexnet min = 69.98 max = 102.26 avg = 83.27 vgg16 min = 302.14 max = 337.56 avg = 320.55 vgg16_int8 min = 464.06 max = 601.92 avg = 540.28 resnet50 min = 140.36 max = 176.66 avg = 159.53 resnet50_int8 min = 299.16 max = 554.05 avg = 453.26 squeezenet_ssd min = 53.43 max = 78.75 avg = 63.67 squeezenet_ssd_int8 min = 91.45 max = 215.14 avg = 123.13 mobilenet_ssd min = 66.30 max = 90.77 avg = 76.86 mobilenet_ssd_int8 min = 89.05 max = 261.33 avg = 119.18 mobilenet_yolo min = 142.24 max = 182.72 avg = 154.48 mobilenetv2_yolov3 min = 81.96 max = 107.17 avg = 91.93 yolov4-tiny min = 103.76 max = 138.15 avg = 115.43 nanodet_m min = 27.15 max = 36.88 avg = 32.00 yolo-fastest-1.1 min = 33.21 max = 40.95 avg = 35.84 yolo-fastestv2 min = 17.51 max = 29.54 avg = 21.32 vision_transformer min = 4981.82 max = 5576.98 avg = 5198.79 nvdc: start nvdcEventThread nvdc: exit nvdcEventThread参考资料how to buildVulkan Support on L4TNVIDIA vulkan driver的安装和Jetson平台上vulkan sdk的制作vulkaninfo failed with VK_ERROR_INITIALIZATION_FAILED
-
Linux使用V2Ray 原生客户端 Linux使用V2Ray 原生客户端1、下载二进制文件官方下载链接:https://github.com/v2fly/v2ray-core/releases2、配置客户端cd ~ wget https://github.com/v2fly/v2ray-core/releases/download/v4.31.0/v2ray-linux-64.zip unzip -d v2ray-cli v2ray-linux-64.zip cd v2ray-cli/ chmod +x v2ray v2ctl vim config.jsonconfig.json 客户端配置{ "log": { "loglevel": "info" }, "inbounds": [ { "port": 1080, "protocol": "socks", "sniffing": { "enabled": true, "destOverride": [ "http", "tls" ] }, "settings": { "udp": true // 开启 UDP 协议支持 } }, { "port": 10809, "protocol": "http", "sniffing": { "enabled": true, "destOverride": [ "http", "tls" ] } } ], "outbounds": [ { "tag": "proxy-vmess", "protocol": "vmess", "settings": { "vnext": [ { "address": "nas.inat.top", // 服务器的 IP "port": 53689, // 服务器的端口 "users": [ { // id 就是 UUID,相当于用户密码 "id": "77ba2a7d-3e1d-486c-a2f5-c8718d3d1560", "alterId": 10 } ] } ] } }, { "tag": "direct", "settings": {}, "protocol": "freedom" } ], "dns": { "server": [ "8.8.8.8", "1.1.1.1" ], // 你的 IP 地址,用于 DNS 解析离你最快的 CDN "clientIp": "202.113.37.69" }, // 配置路由功能 "routing": { "domainStrategy": "IPOnDemand", "rules": [ { "type": "field", "domain": [ "cnblogs.com" ], "outboundTag": "proxy-vmess" }, { "type": "field", "domain": [ "domain:inat.top" ], "outboundTag": "direct" } ] } }测试配置文件./v2ray -test config.json3. 启动客户端screen -S v2ray ./v2ray -v2ray config.json4. 测试代理curl -x http://127.0.0.1:10809 www.baidu.com参考资料记录:Linux下 V2Ray 原生客户端配置在 v2ray 中同时开启 socks 和 http 代理
-
免密码使用sudo 免密码使用sudosudo是linux系统管理指令,是允许系统管理员让普通用户执行一些或者全部的root命令的一个工具,如halt、reboot、su等等。配置步骤登录到root用户su root将用户加入sudoersvi /etc/sudoers移动光标,到一行root ALL=(ALL) ALL的下一行,按a,进入append模式,输入your_user_name ALL=(ALL) ALL然后按Esc,再输入:w保存文件,再:q退出这样就把自己加入了sudo组,可以使用sudo命令了。免密使用sudo默认5分钟后刚才输入的sodo密码过期,下次sudo需要重新输入密码,如果觉得在sudo的时候输入密码麻烦,把刚才的输入换成如下内容即可:your_user_name ALL=(ALL) NOPASSWD: ALL参考资料免密码使用sudo和su
-
通过SoftEther搭建dns隧道绕过校园网认证进行免费上网 原理介绍工作原理正常情况下,当我们连上酒店或者其他需要验证才可以使用的网络后,虽然上不了网,但是我们的计算机却分配到了IP地址(不分配IP地址web认证就实现不了),此时若我们进行一些上网的操作,那么计算机的数据包将从TCP443端口上发出,校园网、酒店等网关就会拦截从这个端口上发出的数据包。同理从其它端口上发出的数据包也会遭到拦截。但是有一个神奇的端口,从这个端口发出的数据包不会遭到网关拦截,它就是UDP53端口(UDP53端口上运行的协议是DNS协议(域名解析协议))。常见的内网环境中 , 防火墙可能会限制只允许 udp 53 端口出站,这样我们可以利用 DNS 查询流量来封装 TCP 流量 , 达到绕过防火墙的目的。DNS隧道。从名字上来看就是利用DNS查询过程建立起隧道,传输数据。相关软件下载地址SoftEther下载中心https://www.softether-download.com/cn.aspx搭建步骤准备工作一台带宽还可以的云服务器确保服务器ssh连接正常关闭服务器防火墙(云服务器有的需要在安全组里进行二次放行)问题注意:关闭服务器的udp53端口默认运行的程序查看是否关闭$ sudo netstat -ltnup | grep 53 tcp 0 0 127.0.0.53:53 0.0.0.0:* LISTEN 291/systemd-resolve udp 0 0 127.0.0.53:53 0.0.0.0:* 291/systemd-resolve关闭sudo systemctl stop systemd-resolved sudo systemctl disable systemd-resolved配置1:服务器端完成(ubuntu16.04)下载并运行服务# 下载软件 wget https://github.com/SoftEtherVPN/SoftEtherVPN_Stable/releases/download/v4.38-9760-rtm/softether-vpnserver-v4.38-9760-rtm-2021.08.17-linux-x64-64bit.tar.gz # 解压 tar xzvf softether-vpnserver-v4.38-9760-rtm-2021.08.17-linux-x64-64bit.tar.gz # 编译 cd vpnserver make # 运行 ./vpnserver start初始化工作(除了输入1次1之外,其余均按回车) ./vpncmd vpncmd command - SoftEther VPN Command Line Management Utility SoftEther VPN Command Line Management Utility (vpncmd command) Version 4.38 Build 9760 (English) Compiled 2021/08/17 22:32:49 by buildsan at crosswin Copyright (c) SoftEther VPN Project. All Rights Reserved. By using vpncmd program, the following can be achieved. 1. Management of VPN Server or VPN Bridge 2. Management of VPN Client 3. Use of VPN Tools (certificate creation and Network Traffic Speed Test Tool) Select 1, 2 or 3: 1 Specify the host name or IP address of the computer that the destination VPN Server or VPN Bridge is operating on. By specifying according to the format 'host name:port number', you can also specify the port number. (When the port number is unspecified, 443 is used.) If nothing is input and the Enter key is pressed, the connection will be made to the port number 8888 of localhost (this computer). Hostname of IP Address of Destination: If connecting to the server by Virtual Hub Admin Mode, please input the Virtual Hub name. If connecting by server admin mode, please press Enter without inputting anything. Specify Virtual Hub Name: Connection has been established with VPN Server "localhost" (port 443). You have administrator privileges for the entire VPN Server. VPN Server>配置2:客户端完成(win10)下载SoftEther VPN Server Manager并安装添加新的连接设置(主机名写服务器的IP或者域名)-第一次连接会让你设置新密码继续完成配置添加用户开启虚拟NAT和虚拟DHCP开启DNS 53端口监听连接测试下载客户端并安装添加新连接连接设置名随便填主机名填服务IP端口号填53连接测试,获取到IP则代表搭建无误参考资料1.SoftEther下载中心
-
通过dns2tcp搭建tcp隧道绕过校园网认证进行免费上网 原理介绍dns2tcp工作原理正常情况下,当我们连上酒店或者其他需要验证才可以使用的网络后,虽然上不了网,但是我们的计算机却分配到了IP地址(不分配IP地址web认证就实现不了),此时若我们进行一些上网的操作,那么计算机的数据包将从TCP443端口上发出,校园网、酒店等网关就会拦截从这个端口上发出的数据包。同理从其它端口上发出的数据包也会遭到拦截。但是有一个神奇的端口,从这个端口发出的数据包不会遭到网关拦截,它就是UDP53端口(UDP53端口上运行的协议是DNS协议(域名解析协议))。常见的内网环境中 , 防火墙可能会限制只允许 udp 53 端口出站,这样我们可以利用 DNS 查询流量来封装 TCP 流量 , 达到绕过防火墙的目的。DNS隧道。从名字上来看就是利用DNS查询过程建立起隧道,传输数据。dns2tcp工具介绍dns2tcp 是一个使用C语言开发的利用DNS隧道转发TCP连接的工具。客户端会在本地监听一个端口,并指定:要使用服务端上面的哪个资源(如ssh、socket、http)我们只需把数据扔进本地的该端口,dns2tcpc将使用DNS隧道传送到服务端。随后,服务端根据客户端指定要使用的资源,将数据转发到其本机的相应端口中去。这里的相应端口,可通过配置文件(/etc/dns2tcpd.conf)配置。准备工作判断DNS解析的53端口是否开放连接校园网,测速在未认证状态下是否可以正常dns解析$ nslookup www.baidu.com Server: 127.0.0.53 Address: 127.0.0.53#53 Non-authoritative answer: www.baidu.com canonical name = www.a.shifen.com. Name: www.a.shifen.com Address: 110.242.68.3 Name: www.a.shifen.com Address: 110.242.68.4可以看到,nslookup解析域名正常,代表DNS解析的53端口正常开放,从这个端口发出的数据包不会遭到网关拦截 ,也就是UDP53端口。云服务器与域名具有公网ip的云服务1台域名一个搭建步骤(ubuntu16.04为例)设置域名解析登录你的域名服务器商如:DNSpod在域名下面添加一个A记录,A记录的名字可以任意,如ns1.vvvtimes.com,A记录的值为你VPS服务器的IP地址。最后,再添加一个NS记录,这个NS的名字可以任意,比如tcp.vvvtimes.com,NS记录的值为你上面添加的A记录的名字,即ns1.vvvtimes.com。服务器端安装DNS2TCPsudo apt update sudo apt install dns2tcp编辑DNS2TCP配置文件在 /etc 建立一个名为 dns2tcpd.conf 的文件, 然后输入以下配置:listen = 0.0.0.0 port = 53 user = nobody chroot = /tmp domain = tcp.vvvtimes.com(上面配置NS记录的域名) key = fuckoff (密码,可选) resources = ssh:127.0.0.1:22,socks:127.0.0.1:1082,http:127.0.0.1:3128 启动 DNS2TCP(建议使用screen启动)dns2tcpd -f /etc/dns2tcpd.conf -F -d 2 注意:腾讯云服务器不给实际网卡分配公网IP,所以要监听0.0.0.0客户端安装DNS2TCPsudo apt update sudo apt install dns2tcp启动 DNS2TCP(建议使用screen启动)dns2tcpc -c -k fuckoff -r ssh -z tcp.vvvtimes.com 1.2.3.4 -l 2222 -d 2 -k 后接密码,与服务器端的配置保持一致即可 -r 后接服务名称, 这里我们用ssh -z 后接NS记录的网址, ip, 注意IP地址最好写上, 可以不写 -l 后接本地端口 -d 开启 Debug测试ssh连接测试ssh root@127.0.0.1 -p 2222可以直接登陆你的server ssh。设置ssh隧道(偶尔会提示reset peer或许要多试几次):ssh -CfNg root@127.0.0.1 -p 2222 -D 7002查看端口是否开放$ lsof -i:2222 COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME dns2tcpc 28938 bonelee 4u IPv4 11154775 0t0 TCP localhost:2222 (LISTEN) dns2tcpc 28938 bonelee 5u IPv4 11157735 0t0 TCP localhost:2222->localhost:46296 (ESTABLISHED) ssh 28953 bonelee 3u IPv4 11157734 0t0 TCP localhost:46296->localhost:2222 (ESTABLISHED) $ lsof -i:7002 COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME ssh 28953 bonelee 4u IPv4 11160083 0t0 TCP *:afs3-prserver (LISTEN) ssh 28953 bonelee 5u IPv6 11160084 0t0 TCP *:afs3-prserver (LISTEN)浏览器里直接socks5代理127.0.0.1 7002端口即可上网了!上谷歌也是可以的。。。不过速度就不咋地。。。参考资料通过dns2tcp绕过校园网认证进行免费上网[DNS隧道之DNS2TCP实现——dns2tcpc必须带server IP才可以,此外ssh可以穿过墙的,设置代理上网]使用DNS2TCP搭建DNS隧道,绕过网络认证,实现免验证上网
-
中国民航大学专利申请流程 STEP1:把专利写好参考资料:参考专利STEP2:找代理要专利委托表把专利发给代理,代理会通过邮件发过来两个专利委托表STEP3:填表填写这两个专利委托表+中国民航大学专利申请报告书STEP4:去学院签字盖章把中国民航大学专利申请报告书拿到院长那签字+去张大伟老师那盖章STEP5:去科技处交表北教1-5楼出电梯就是了交中国民航大学专利申请报告书STEP6:把相关的文件拿给老师去学校盖章让老师去学校给专利委托文件盖章STEP7:快递委托文件把签字盖章后的专利委托文件快递寄到代理给的地址STEP8:付款和报销直接微信把钱转给代理,然后把快递地址给代理,代理会把发票记过来拿发票去找谢老师报销
-
快速使用Faster RCNN进行训练VOC格式的数据集 训练步骤STEP1:下载代码并配置环境git clone https://github.com/bubbliiiing/faster-rcnn-pytorch.git cd faster-rcnn-pytorch pip install -r requirements.txtSTEP2:根据文件结构填充VOC格式的数据集数据放置格式(只需完成#TODO部分即可)├──VOCdevkit/VOC2007/ ├── Annotations ├──放置xml文件 #TODO ├── JPEGImages ├──放置img文件 #TODO ├──ImageSets/Main ├──放置训练索引文件 (无需手动完成,自动生成) ├── voc2frcnn.py #数据分割脚本,用于生成训练索引文件编辑voc2frcnn.py。设置tarin\val\test数据分割比例#----------------------------------------------------------------------# # 想要增加测试集修改trainval_percent # train_percent不需要修改 #----------------------------------------------------------------------# trainval_percent=1 train_percent=1生成训练索引文件python voc2frcnn.pySTEP3:生成最终训练所需的txt文件编辑根目录下的voc_annotation.py,将classes改成你自己的classes(注意不要使用中文标签,文件夹中不要有空格!)classes = ["aeroplane", "bicycle", "bird", "boat", "bottle", "bus", "car", "cat", "chair", "cow", "diningtable", "dog", "horse", "motorbike", "person", "pottedplant", "sheep", "sofa", "train", "tvmonitor"]然后运行voc_annotation.pypython voc_annotation.py此时会生成对应的2007_train.txt,每一行对应其图片位置及其真实框的位置。STEP4:编辑model_data/voc_classes.txt将其中的类别数改为自己的,文件内容为cat dog ...STEP5:修改train.py的NUM_CLASSSES将train.py的NUM_CLASSSES修改成所需要分的类的个数(不需要+1)STEP6:开始训练python train.pySTEP7:模型效果评估评估过程可参考视频https://www.bilibili.com/video/BV1zE411u7Vw参考资料https://github.com/bubbliiiing/faster-rcnn-pytorch
-
快速使用YOLOv5进行训练VOC格式的数据集 训练步骤STEP1:下载官方YOLOv5的代码并配置环境git clone https://github.com/ultralytics/yolov5 cd yolov5 pip install -r requirements.txtSTEP2:准备VOC格式的数据集数据放置格式├──train_data_VOC ├── Annotations ├──放置xml文件 ├── JPEGImages ├──防止img文件STEP3:将数据集转为YOLOv5所需要的COCO格式mkdir train_data_COCO vim VOC2COCO.pyimport os import shutil import random import xmltodict from progressbar import * #================================================================================================================ # 函数定义区 # 函数-将voc xml中的object转化为对应的一条yolo数据 def get_yolo_data(obj,img_width,img_height): # 获取voc格式的数据信息 name = obj['name'] xmin = float(obj['bndbox']['xmin']) xmax = float(obj['bndbox']['xmax']) ymin = float(obj['bndbox']['ymin']) ymax = float(obj['bndbox']['ymax']) # 计算yolo格式的数据信息 class_idx = class_names.index(name) x_center,y_center = (xmin+xmax)/2,(ymin+ymax)/2 box_width = xmax - xmin box_height = ymax - ymin yolo_data = "{} {} {} {} {}\n".format(class_idx,x_center/img_width,y_center/img_height,box_width/img_width,box_height/img_height) return yolo_data # 函数-将xml文件转为txt文件 def convert_annotations(image_name): in_file = xml_file_path + image_name + '.xml' out_file = txt_file_path + image_name + '.txt' yolo_data = "" with open(in_file) as f: xml_str = f.read() # 转为字典 xml_dic = xmltodict.parse(xml_str) # 获取图片的width、height img_width = float(xml_dic["annotation"]["size"]["width"]) img_height = float(xml_dic["annotation"]["size"]["height"]) # 获取xml文件中的object objects = xml_dic["annotation"]["object"] if isinstance(objects,list): # xml文件中包含多个object for obj in objects: yolo_data += get_yolo_data(obj,img_width,img_height) else: # xml文件中包含1个object obj = objects yolo_data += get_yolo_data(obj,img_width,img_height) with open(out_file,'w') as f: f.write(yolo_data) # 函数-创建最终用于训练的COCO格式数据集的文件夹 def create_dir(): if not os.path.exists('train_data_COCO/images/'): os.makedirs('train_data_COCO/images/') if not os.path.exists('train_data_COCO/labels/'): os.makedirs('train_data_COCO/labels/') if not os.path.exists('train_data_COCO/images/train/'): os.makedirs('train_data_COCO/images/train') if not os.path.exists('train_data_COCO/images/val/'): os.makedirs('train_data_COCO/images/val/') if not os.path.exists('train_data_COCO/images/test/'): os.makedirs('train_data_COCO/images/test/') if not os.path.exists('train_data_COCO/labels/train/'): os.makedirs('train_data_COCO/labels/train/') if not os.path.exists('train_data_COCO/labels/val/'): os.makedirs('train_data_COCO/labels/val/') if not os.path.exists('train_data_COCO/labels/test/'): os.makedirs('train_data_COCO/labels/test/') return #================================================================================================================ # 功能实现区 """ STEP1:准备工作:数据准备+创建各种所需的文件夹 """ # 对应的VOC数据集的路径参数+类别参数 xml_file_path = './train_data_VOC/Annotations/' # 检查和自己的xml文件夹名称是否一致 images_file_path = './train_data_VOC/JPEGImages/' # 检查和自己的图像文件夹名称是否一致 class_names = ['Person', 'BridgeVehicle', 'LuggageVehicle', 'Plane', 'RefuelVehicle', 'FoodVehicle', 'RubbishVehicle', 'WaterVehicle', 'PlatformVehicle', 'TractorVehicle'] # 创一个临时文件夹用来存放xml文件转换出来的对应的txt文件 if not os.path.exists('train_data_COCO/temp_labels/'): os.makedirs('train_data_COCO/temp_labels/') txt_file_path = 'train_data_COCO/temp_labels/' # 执行xml到txt的转换,存储到一个临时文件夹 total_xml = os.listdir(xml_file_path) num_xml = len(total_xml) # XML文件总数 for i in range(num_xml): name = total_xml[i][:-4] convert_annotations(name) # 创建COCO格式的数据所需要的各种文件夹 create_dir() # 读取所有的txt文件 total_txt = os.listdir(txt_file_path) print("数据准备工作完成,开始进行数据分配") """ STEP2:数据分配:按比例对数据集进行划分 """ # 设置数据集划分比例,训练集75%,验证集15%,测试集15% train_percent = 0.8 val_percent = 0.15 test_percent = 0.05 # 计算train,val,test每一类的数据数量 num_txt = len(total_txt) num_train = int(num_txt * train_percent) num_val = int(num_txt * val_percent) num_test = num_txt - num_train - num_val # 根据计算出的每类的数据数量计算出进行数据分配的索引 list_all_txt = range(num_txt) # 范围 range(0, num) train = random.sample(list_all_txt, num_train)# train从list_all_txt取出num_train个元素 val_test = [i for i in list_all_txt if not i in train]# 所以list_all_txt列表只剩下了这些元素:val_test val = random.sample(val_test, num_val)# 再从val_test取出num_val个元素,val_test剩下的元素就是test # 根据采样的索引结果进行文件分配工作 print("训练集数目:{}, 验证集数目:{},测试集数目:{}".format(len(train), len(val), len(val_test) - len(val))) #进度条功能 widgets = ['VOC2COCO: ',Percentage(), ' ', Bar('#'),' ', Timer(),' ', ETA()] pbar = ProgressBar(widgets=widgets, maxval=num_txt).start() count = 0 for i in list_all_txt: name = total_txt[i][:-4] srcImage = images_file_path + name + '.jpg' srcLabel = txt_file_path + name + '.txt' if i in train: dst_train_Image = 'train_data_COCO/images/train/' + name + '.jpg' dst_train_Label = 'train_data_COCO/labels/train/' + name + '.txt' shutil.copyfile(srcImage, dst_train_Image) shutil.copyfile(srcLabel, dst_train_Label) elif i in val: dst_val_Image = 'train_data_COCO/images/val/' + name + '.jpg' dst_val_Label = 'train_data_COCO/labels/val/' + name + '.txt' shutil.copyfile(srcImage, dst_val_Image) shutil.copyfile(srcLabel, dst_val_Label) else: dst_test_Image = 'train_data_COCO/images/test/' + name + '.jpg' dst_test_Label = 'train_data_COCO/labels/test/' + name + '.txt' shutil.copyfile(srcImage, dst_test_Image) shutil.copyfile(srcLabel, dst_test_Label) #更新进度条 count += 1 pbar.update(count) #释放进度条 pbar.finish() print("数据分配工作完成,开始释放临时文") """ STEP3:释放临时文件 """ shutil.rmtree(txt_file_path) print("临时文件释放完成,VOC2COCO执行结束")python VOC2COCO.pySTEP4:在data下创建与数据对应的data.yaml文件文件内容按照数据的数据情况填写path: train_data_COCO # root train: # train images (relative to 'path') - images/train val: # val images (relative to 'path') - images/val test: # test images (optional) - images/test # Classes nc: 10 # number of classes names: ['Person', 'BridgeVehicle', 'LuggageVehicle', 'Plane', 'RefuelVehicle', 'FoodVehicle', 'RubbishVehicle', 'WaterVehicle', 'PlatformVehicle', 'TractorVehicle'] # class namesSTEP5:下载预训练模型mkdir weights cd weights wget https://github.com/ultralytics/yolov5/releases/download/v5.0/yolov5s.ptSTEP6:开始训练python train.py --data data/data.yaml --cfg models/yolov5s.yaml --weights weights/yolov5s.pt --batch-size 64 --epochs 60 参考资料https://github.com/ultralytics/yolov5
-
深度学习中的FLOPs介绍及计算(注意区分FLOPS) FLOPS与FLOPsFLOPS:注意全大写,是floating point operations per second的缩写,意指每秒浮点运算次数,理解为计算速度。是一个衡量硬件性能的指标。FLOPs:注意s小写,是floating point operations的缩写(s表复数),意指浮点运算数,理解为计算量。可以用来衡量算法/模型的复杂度。全连接网络中FLOPs的计算推导以4个输入神经元和3个输出神经元为例计算一个输出神经元的的计算过程为$$ y1 = w_{11}*x_1+w_{21}*x_2+w_{31}*x_3+w_{41}*x_4 $$所需的计算次数为4次乘法3次加法共需4+3=7计算。推广到I个输入神经元O个输出神经元后则计算一个输出神经元所需要的计算次数为$I+(I-1)=2I-1$,则总的计算次数为$$ FLOPs = (2I-1)*O $$考虑bias则为$$ y1 = w_{11}*x_1+w_{21}*x_2+w_{31}*x_3+w_{41}*x_4+b1 $$总的计算次数为$$ FLOPs = 2I*O $$结果FC(full connected)层FLOPs的计算公式如下(不考虑bias时有-1,有bias时没有-1):$$ FLOPs = (2 \times I - 1) \times O $$其中:I = input neuron numbers(输入神经元的数量)O = output neuron numbers(输出神经元的数量)CNN中FLOPs的计算以下答案不考虑activation function的运算推导对于输入通道数为$C_{in}$,卷积核的大小为K,输出通道数为$C_{out}$,输出特征图的尺寸为$H*W$进行一次卷积运算的计算次数为乘法$C_{in}K^2$次加法$C_{in}K^2-1$次共计$C_{in}K^2+C_{in}K^2-1=2C_{in}K^2-1$次,若考虑bias则再加1次得到一个channel的特征图所需的卷积次数为$H*W$次共计需得到$C_{out}$个特征图因此对于CNN中的一个卷积层来说总的计算次数为(不考虑bias时有-1,考虑bias时没有-1):$$ FLOPs = (2C_{in}K^2-1)HWC_{out} $$结果卷积层FLOPs的计算公式如下(不考虑bias时有-1,有bias时没有-1):$$ FLOPs = (2C_{in}K^2-1)HWC_{out} $$其中:$C_{in}$ = input channelK= kernel sizeH,W = output feature map size$C_{out}$ = output channel计算FLOPs的代码或包torchstatfrom torchstat import stat import torchvision.models as models model = models.vgg16() stat(model, (3, 224, 224)) module name input shape output shape params memory(MB) MAdd Flops MemRead(B) MemWrite(B) duration[%] MemR+W(B) 0 features.0 3 224 224 64 224 224 1792.0 12.25 173,408,256.0 89,915,392.0 609280.0 12845056.0 3.67% 13454336.0 1 features.1 64 224 224 64 224 224 0.0 12.25 3,211,264.0 3,211,264.0 12845056.0 12845056.0 1.83% 25690112.0 2 features.2 64 224 224 64 224 224 36928.0 12.25 3,699,376,128.0 1,852,899,328.0 12992768.0 12845056.0 8.43% 25837824.0 3 features.3 64 224 224 64 224 224 0.0 12.25 3,211,264.0 3,211,264.0 12845056.0 12845056.0 1.45% 25690112.0 4 features.4 64 224 224 64 112 112 0.0 3.06 2,408,448.0 3,211,264.0 12845056.0 3211264.0 11.37% 16056320.0 5 features.5 64 112 112 128 112 112 73856.0 6.12 1,849,688,064.0 926,449,664.0 3506688.0 6422528.0 4.03% 9929216.0 6 features.6 128 112 112 128 112 112 0.0 6.12 1,605,632.0 1,605,632.0 6422528.0 6422528.0 0.73% 12845056.0 7 features.7 128 112 112 128 112 112 147584.0 6.12 3,699,376,128.0 1,851,293,696.0 7012864.0 6422528.0 5.86% 13435392.0 8 features.8 128 112 112 128 112 112 0.0 6.12 1,605,632.0 1,605,632.0 6422528.0 6422528.0 0.37% 12845056.0 9 features.9 128 112 112 128 56 56 0.0 1.53 1,204,224.0 1,605,632.0 6422528.0 1605632.0 7.32% 8028160.0 10 features.10 128 56 56 256 56 56 295168.0 3.06 1,849,688,064.0 925,646,848.0 2786304.0 3211264.0 3.30% 5997568.0 11 features.11 256 56 56 256 56 56 0.0 3.06 802,816.0 802,816.0 3211264.0 3211264.0 0.00% 6422528.0 12 features.12 256 56 56 256 56 56 590080.0 3.06 3,699,376,128.0 1,850,490,880.0 5571584.0 3211264.0 5.13% 8782848.0 13 features.13 256 56 56 256 56 56 0.0 3.06 802,816.0 802,816.0 3211264.0 3211264.0 0.37% 6422528.0 14 features.14 256 56 56 256 56 56 590080.0 3.06 3,699,376,128.0 1,850,490,880.0 5571584.0 3211264.0 4.76% 8782848.0 15 features.15 256 56 56 256 56 56 0.0 3.06 802,816.0 802,816.0 3211264.0 3211264.0 0.37% 6422528.0 16 features.16 256 56 56 256 28 28 0.0 0.77 602,112.0 802,816.0 3211264.0 802816.0 2.56% 4014080.0 17 features.17 256 28 28 512 28 28 1180160.0 1.53 1,849,688,064.0 925,245,440.0 5523456.0 1605632.0 3.66% 7129088.0 18 features.18 512 28 28 512 28 28 0.0 1.53 401,408.0 401,408.0 1605632.0 1605632.0 0.00% 3211264.0 19 features.19 512 28 28 512 28 28 2359808.0 1.53 3,699,376,128.0 1,850,089,472.0 11044864.0 1605632.0 5.50% 12650496.0 20 features.20 512 28 28 512 28 28 0.0 1.53 401,408.0 401,408.0 1605632.0 1605632.0 0.00% 3211264.0 21 features.21 512 28 28 512 28 28 2359808.0 1.53 3,699,376,128.0 1,850,089,472.0 11044864.0 1605632.0 5.49% 12650496.0 22 features.22 512 28 28 512 28 28 0.0 1.53 401,408.0 401,408.0 1605632.0 1605632.0 0.00% 3211264.0 23 features.23 512 28 28 512 14 14 0.0 0.38 301,056.0 401,408.0 1605632.0 401408.0 1.10% 2007040.0 24 features.24 512 14 14 512 14 14 2359808.0 0.38 924,844,032.0 462,522,368.0 9840640.0 401408.0 2.94% 10242048.0 25 features.25 512 14 14 512 14 14 0.0 0.38 100,352.0 100,352.0 401408.0 401408.0 0.00% 802816.0 26 features.26 512 14 14 512 14 14 2359808.0 0.38 924,844,032.0 462,522,368.0 9840640.0 401408.0 2.57% 10242048.0 27 features.27 512 14 14 512 14 14 0.0 0.38 100,352.0 100,352.0 401408.0 401408.0 0.00% 802816.0 28 features.28 512 14 14 512 14 14 2359808.0 0.38 924,844,032.0 462,522,368.0 9840640.0 401408.0 2.19% 10242048.0 29 features.29 512 14 14 512 14 14 0.0 0.38 100,352.0 100,352.0 401408.0 401408.0 0.37% 802816.0 30 features.30 512 14 14 512 7 7 0.0 0.10 75,264.0 100,352.0 401408.0 100352.0 0.37% 501760.0 31 avgpool 512 7 7 512 7 7 0.0 0.10 0.0 0.0 0.0 0.0 0.00% 0.0 32 classifier.0 25088 4096 102764544.0 0.02 205,516,800.0 102,760,448.0 411158528.0 16384.0 10.62% 411174912.0 33 classifier.1 4096 4096 0.0 0.02 4,096.0 4,096.0 16384.0 16384.0 0.00% 32768.0 34 classifier.2 4096 4096 0.0 0.02 0.0 0.0 0.0 0.0 0.37% 0.0 35 classifier.3 4096 4096 16781312.0 0.02 33,550,336.0 16,777,216.0 67141632.0 16384.0 2.20% 67158016.0 36 classifier.4 4096 4096 0.0 0.02 4,096.0 4,096.0 16384.0 16384.0 0.00% 32768.0 37 classifier.5 4096 4096 0.0 0.02 0.0 0.0 0.0 0.0 0.37% 0.0 38 classifier.6 4096 1000 4097000.0 0.00 8,191,000.0 4,096,000.0 16404384.0 4000.0 0.73% 16408384.0 total 138357544.0 109.39 30,958,666,264.0 15,503,489,024.0 16404384.0 4000.0 100.00% 783170624.0 ============================================================================================================================================================ Total params: 138,357,544 ------------------------------------------------------------------------------------------------------------------------------------------------------------ Total memory: 109.39MB Total MAdd: 30.96GMAdd Total Flops: 15.5GFlops Total MemR+W: 746.89MB 参考资料CNN 模型所需的计算力(flops)和参数(parameters)数量是怎么计算的?分享一个FLOPs计算神器CNN Explainer[Molchanov P , Tyree S , Karras T , et al. Pruning Convolutional Neural Networks for Resource Efficient Transfer Learning[J]. 2016.](https://arxiv.org/pdf/1611.06440.pdf)