搜索到
362
篇与
的结果
-
 Selenium:Python爬虫进阶 1.简介1.1 什么是Selenium?官网: Selenium是一个用于Web应用程序测试的工具。真实:大量用于网络爬虫,相比requests爬虫,完全模拟真人使用浏览器的流程,对于动态JS加载的网页更容易爬取1.2 Selenium的功能框架底层使用JavaScript模拟真实用户对浏览器进行操作。测试脚本执行时,浏览器自动按照脚本代码做出点击,输入,打开,验证等操作,就像真实用户所做的一样,从终端用户的角度测试应用程序。可用于较难的爬虫:动态JS加载、登录验证、表单提交等使用简单,可使用Python、Java等多种语言编写用例脚本。1.3 为什么要学习Selenium?requests爬虫局限性较大,分析困难、被封禁概率高可用于较难的爬虫伪装成真实的浏览器,被封禁的概率更低动态JS加载登录验证表单提交等1.4 Selenium的缺点相比requests,性能比较差,爬取的慢1.5 Selenium运行框架2.Selenium环境搭建1.电脑安装谷歌Chrome浏览器(其他浏览器不推荐)需要看一下当前的Chrome版本号,下载对应ChromeDriver2.下载安装 ChromeDriverhttps://www.selenium.dev/documentation/getting_started/installing_browser_drivers/windowns 放到C:\WebDriver\bin目录,这个目录加入系统PATH3.Python安装selenium库pip install selenium3.Selenium实战案例3.1 爬取电影天堂的视频真实下载地址用到selenium加载页面渲染出m3u8文件的地址from selenium import webdriver from selenium.webdriver.chrome.options import Options from selenium.webdriver.chrome.service import Service from selenium.webdriver.common.by import By from selenium.webdriver.support.wait import WebDriverWait from bs4 import BeautifulSoup import re # 实例化一个浏览器对象(传入浏览器的驱动程序) 通过Options实现无可视化界面的操作 chrome_options = Options() chrome_options.add_argument('--headless') # 不显示浏览器在后台运行 chrome_service = Service("chromedriver.exe"); browser = webdriver.Chrome(service=chrome_service,options=chrome_options) # 封装通过selenium获取html的方法 def get_html_by_selenium(url): # 对url发起请求 browser.get(url) # 等待页面加载完成 wait = WebDriverWait(browser, 3); # 获取页面源代码 page_html = browser.page_source return page_html # 电视剧页面地址_base base_url = "https://www.dy10000.com/wplay/68599-2-{}.html" # 生成下载脚本 for i in range(42,48): url = base_url.format(i) html = get_html_by_selenium(url) soup = BeautifulSoup(html, features='lxml') script_all = soup.body.find_all("script") for script in script_all: m3u8_search = re.search(r"http.*?m3u8", str(script)) if m3u8_search: url_m3u8 = m3u8_search.group(0).replace("\\", "") print("ffmpeg -i ", url_m3u8, " -c copy -bsf:a aac_adtstoasc " + str(i) + ".mp4") break # 退出浏览器 browser.quit()ffmpeg -i https://new.iskcd.com/20220518/FhKxDhXk/index.m3u8 -c copy -bsf:a aac_adtstoasc 42.mp4 ffmpeg -i https://new.iskcd.com/20220518/2MSrEhUz/index.m3u8 -c copy -bsf:a aac_adtstoasc 43.mp4 ffmpeg -i https://new.iskcd.com/20220519/7o5nJxJ3/index.m3u8 -c copy -bsf:a aac_adtstoasc 44.mp4 ffmpeg -i https://new.iskcd.com/20220519/BB2x9BaG/index.m3u8 -c copy -bsf:a aac_adtstoasc 45.mp4 ffmpeg -i https://new.iskcd.com/20220520/AxB2XF4T/index.m3u8 -c copy -bsf:a aac_adtstoasc 46.mp43.2 爬取电影先生的视频真实下载地址用到selenium加载页面渲染出m3u8文件的地址from selenium import webdriver from selenium.webdriver.chrome.options import Options from selenium.webdriver.chrome.service import Service from selenium.webdriver.common.by import By from selenium.webdriver.support.wait import WebDriverWait from bs4 import BeautifulSoup import re # 实例化一个浏览器对象(传入浏览器的驱动程序) 通过Options实现无可视化界面的操作 chrome_options = Options() chrome_options.add_argument('--headless') # 不显示浏览器在后台运行 chrome_service = Service("chromedriver.exe"); browser = webdriver.Chrome(service=chrome_service,options=chrome_options) # 封装通过selenium获取html的方法 def get_html_by_selenium(url): # 对url发起请求 browser.get(url) # 等待页面加载完成 wait = WebDriverWait(browser, 5); # 获取页面源代码 page_html = browser.page_source return page_html # 电视剧页面地址_base base_url = "https://dyxs15.com/paly-222156-5-{}/" # 生成下载脚本 for i in range(15,41): url = base_url.format(i) html = get_html_by_selenium(url) soup = BeautifulSoup(html, features='lxml') td_all = soup.body.find_all("td") for td in td_all: m3u8_search = re.search(r"http.*?m3u8", str(td)) if m3u8_search: url_m3u8 = m3u8_search.group(0).replace("\\", "") print("ffmpeg -i ", url_m3u8, " -c copy -bsf:a aac_adtstoasc " + str(i) + ".mp4") break break # 退出浏览器 browser.quit()ffmpeg -i https://new.qqaku.com/20220526/t5C1cVna/index.m3u8 -c copy -bsf:a aac_adtstoasc 15.mp4 ······ ffmpeg -i https://new.qqaku.com/20220617/Wpf7uowm/index.m3u8 -c copy -bsf:a aac_adtstoasc 40.mp4参考资料https://www.bilibili.com/video/BV1WF411z7qB自动化爬虫selenium基础教程selenium如何不显示浏览器在后台运行Python selenium的这三种等待方式一定要会!
Selenium:Python爬虫进阶 1.简介1.1 什么是Selenium?官网: Selenium是一个用于Web应用程序测试的工具。真实:大量用于网络爬虫,相比requests爬虫,完全模拟真人使用浏览器的流程,对于动态JS加载的网页更容易爬取1.2 Selenium的功能框架底层使用JavaScript模拟真实用户对浏览器进行操作。测试脚本执行时,浏览器自动按照脚本代码做出点击,输入,打开,验证等操作,就像真实用户所做的一样,从终端用户的角度测试应用程序。可用于较难的爬虫:动态JS加载、登录验证、表单提交等使用简单,可使用Python、Java等多种语言编写用例脚本。1.3 为什么要学习Selenium?requests爬虫局限性较大,分析困难、被封禁概率高可用于较难的爬虫伪装成真实的浏览器,被封禁的概率更低动态JS加载登录验证表单提交等1.4 Selenium的缺点相比requests,性能比较差,爬取的慢1.5 Selenium运行框架2.Selenium环境搭建1.电脑安装谷歌Chrome浏览器(其他浏览器不推荐)需要看一下当前的Chrome版本号,下载对应ChromeDriver2.下载安装 ChromeDriverhttps://www.selenium.dev/documentation/getting_started/installing_browser_drivers/windowns 放到C:\WebDriver\bin目录,这个目录加入系统PATH3.Python安装selenium库pip install selenium3.Selenium实战案例3.1 爬取电影天堂的视频真实下载地址用到selenium加载页面渲染出m3u8文件的地址from selenium import webdriver from selenium.webdriver.chrome.options import Options from selenium.webdriver.chrome.service import Service from selenium.webdriver.common.by import By from selenium.webdriver.support.wait import WebDriverWait from bs4 import BeautifulSoup import re # 实例化一个浏览器对象(传入浏览器的驱动程序) 通过Options实现无可视化界面的操作 chrome_options = Options() chrome_options.add_argument('--headless') # 不显示浏览器在后台运行 chrome_service = Service("chromedriver.exe"); browser = webdriver.Chrome(service=chrome_service,options=chrome_options) # 封装通过selenium获取html的方法 def get_html_by_selenium(url): # 对url发起请求 browser.get(url) # 等待页面加载完成 wait = WebDriverWait(browser, 3); # 获取页面源代码 page_html = browser.page_source return page_html # 电视剧页面地址_base base_url = "https://www.dy10000.com/wplay/68599-2-{}.html" # 生成下载脚本 for i in range(42,48): url = base_url.format(i) html = get_html_by_selenium(url) soup = BeautifulSoup(html, features='lxml') script_all = soup.body.find_all("script") for script in script_all: m3u8_search = re.search(r"http.*?m3u8", str(script)) if m3u8_search: url_m3u8 = m3u8_search.group(0).replace("\\", "") print("ffmpeg -i ", url_m3u8, " -c copy -bsf:a aac_adtstoasc " + str(i) + ".mp4") break # 退出浏览器 browser.quit()ffmpeg -i https://new.iskcd.com/20220518/FhKxDhXk/index.m3u8 -c copy -bsf:a aac_adtstoasc 42.mp4 ffmpeg -i https://new.iskcd.com/20220518/2MSrEhUz/index.m3u8 -c copy -bsf:a aac_adtstoasc 43.mp4 ffmpeg -i https://new.iskcd.com/20220519/7o5nJxJ3/index.m3u8 -c copy -bsf:a aac_adtstoasc 44.mp4 ffmpeg -i https://new.iskcd.com/20220519/BB2x9BaG/index.m3u8 -c copy -bsf:a aac_adtstoasc 45.mp4 ffmpeg -i https://new.iskcd.com/20220520/AxB2XF4T/index.m3u8 -c copy -bsf:a aac_adtstoasc 46.mp43.2 爬取电影先生的视频真实下载地址用到selenium加载页面渲染出m3u8文件的地址from selenium import webdriver from selenium.webdriver.chrome.options import Options from selenium.webdriver.chrome.service import Service from selenium.webdriver.common.by import By from selenium.webdriver.support.wait import WebDriverWait from bs4 import BeautifulSoup import re # 实例化一个浏览器对象(传入浏览器的驱动程序) 通过Options实现无可视化界面的操作 chrome_options = Options() chrome_options.add_argument('--headless') # 不显示浏览器在后台运行 chrome_service = Service("chromedriver.exe"); browser = webdriver.Chrome(service=chrome_service,options=chrome_options) # 封装通过selenium获取html的方法 def get_html_by_selenium(url): # 对url发起请求 browser.get(url) # 等待页面加载完成 wait = WebDriverWait(browser, 5); # 获取页面源代码 page_html = browser.page_source return page_html # 电视剧页面地址_base base_url = "https://dyxs15.com/paly-222156-5-{}/" # 生成下载脚本 for i in range(15,41): url = base_url.format(i) html = get_html_by_selenium(url) soup = BeautifulSoup(html, features='lxml') td_all = soup.body.find_all("td") for td in td_all: m3u8_search = re.search(r"http.*?m3u8", str(td)) if m3u8_search: url_m3u8 = m3u8_search.group(0).replace("\\", "") print("ffmpeg -i ", url_m3u8, " -c copy -bsf:a aac_adtstoasc " + str(i) + ".mp4") break break # 退出浏览器 browser.quit()ffmpeg -i https://new.qqaku.com/20220526/t5C1cVna/index.m3u8 -c copy -bsf:a aac_adtstoasc 15.mp4 ······ ffmpeg -i https://new.qqaku.com/20220617/Wpf7uowm/index.m3u8 -c copy -bsf:a aac_adtstoasc 40.mp4参考资料https://www.bilibili.com/video/BV1WF411z7qB自动化爬虫selenium基础教程selenium如何不显示浏览器在后台运行Python selenium的这三种等待方式一定要会! -
天若OCR对接百度文字识别 0.背景在使用文字识别工具天若OCR的时候遇到搜狗、腾讯、有道等接口崩溃导致无法识别的问题,因此考虑使用百度的付费接口进行识别。1.百度文字识别API Key和Secret Key申请打开百度图文识别网站:https://console.bce.baidu.com/ai/#/ai/ocr/overview/index,输入账号密码登录;领取免费尝鲜略然后点击创建应用填写应用名称、应用归属、应用描述点击立即创建然后点击查看应用详情即可看到申请到的API Key和Secret Key2.对接天若OCR$\color{red}{!!!然后发现天若OCR修改密钥是付费版的特权}$$\color{red}{!!!再然后又发现5.0.0版本的虽然在软件里修改无法生效,但是直接修改Data/config.ini下的相关参数可以生效,感觉我的智商受到了侮辱}$[密钥_百度] secret_id=87gTF7eSNwA9z7L2OGuyaxAA secret_key=G5Yp5sA6POKKrFuGhcub21sGvzDIHaw2使用测试-真香3.自行调用-以JavaScript为例3.1 图片转换成base64格式var path = "/sdcard/pic/test01.jpg"; var imag64 = images.toBase64(images.read(path));3.2 获取access_tokenvar getTokenUrl="https://aip.baidubce.com/oauth/2.0/token"; var token_Res = http.post(getTokenUrl, { grant_type: "client_credentials", client_id: API_Key, //API Key client_secret: Secret_Key, //Secret Key }); var access_token = token_Res.body.json().access_token;3.3 调用百度ocr通用文字识别APIvar ocrUrl = "https://aip.baidubce.com/rest/2.0/ocr/v1/general_basic"; var ocr_Res = http.post(ocrUrl, { headers: { "Content-Type": "application/x-www-form-urlencoded" }, access_token: access_token, //生成的token image: imag64, //生成的base64编码 language_type:"CHN_ENG" }); var json = ocr_Res.body.json();3.4 得到json格式结果:{ "words_result": [ {"words": "小微"}, {"words": "测试"} ], "log_id": 2471272194, "words_result_num": 2 }参考资料百度文字识别API Key和Secret Key申请及接口调用
-
航空器的的飞行阶段 一般航空器的的飞行阶段分为五个阶段,分别是:推出滑行、起飞离场、巡航、下降进近、落地和复飞。一、推出滑行 在上客阶段完成,机组做好了所有的航前检查和准备,飞行员就会跟机场塔台申请放行许可(ATC Clearance),同时也会申请推出和开车。管制部门许可机组推出滑行后,机组会沿着塔台指定的滑行路线从机坪滑到跑道入口外等待进一步指令。二、起飞离场机组得到塔台进跑道和起飞的指令后,就以为这架巨大银鹰马上要展翅高飞了,进跑道,对正跑道中心线,推油门,手扶方向舵,加速拉杆,飞行员一系列操作完成后,这架飞机已经离开了地面,正沿着指定的航迹和高度许可爬升高度。跑道上和起飞3分钟,落地8分钟是飞行中最危险的位置和时间,飞机诞生以来,飞行事故大多就发生在这个阶段,历史上死亡人数最多的特内里费空难就发生在跑道上,起飞阶段两架满载旅客的波音747相撞,死亡人数高达500人左右。三、巡航 当飞机的高度上升到了巡航高度,例如一万零一千米,这时,这架飞机进入了巡航阶段,如果没有天气,颠簸,冲突或其他情况,那接下来的很长一段时间飞机几乎就会保持在这个高度附近,一直沿计划航路飞行,直到快到目的地。三万英尺(一万米)左右的巡航高度接近了大气层的对流层顶部分,在这个高度飞行,飞机会相对平稳一些,美丽的空中乘务员们会利用这段时间进行客舱服务。四、下降进近 当航空器距离目的地机场200-300公里时,飞机一般要开始下降了,为保证旅客的舒适性,运输航班的下降率一般为1000-2000英尺/分钟左右,到达真高2000米左右飞机一般会开始最后进近阶段,这个阶段飞机会打开起落架轮仓,放出并锁定起落架,对正跑道,做好落地前的所有检查单和准备工作。 处。五、落地和复飞 在得到塔台的可以落地指令后,飞机继续沿无线电搭建的下滑道平稳进近,边进近边下降高度。如果突然有特殊情况发生,如跑道侵入,风切变等一系列因素导致不能继续进近,飞行员就需要操作飞机推油门拉杆,复飞爬升,重新进近或者去其他机场返航备降。平稳落地后飞机还是会按指定的路线滑回机位。参考资料分享:航空器飞行的几个飞行阶段
-
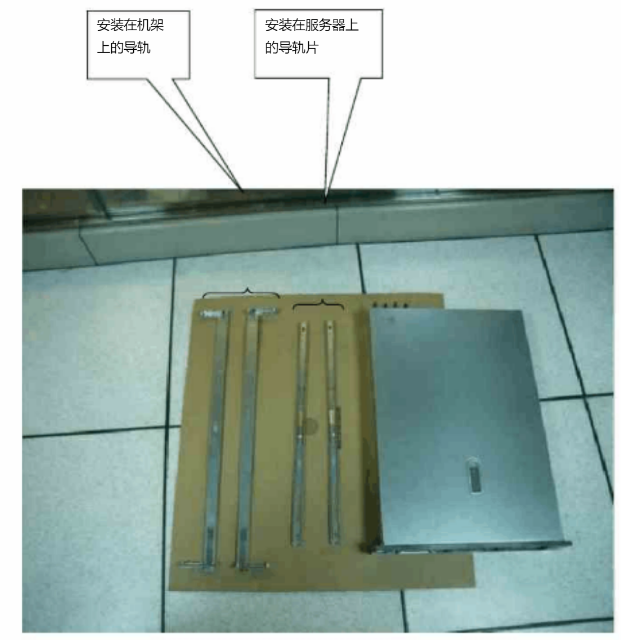
机架式服务器安装-以HP380为例 0.核心配件1.安装服务器上的导轨1.1 将导轨片安装在服务器两侧2.安装机架上的导轨上机架的导轨上分别标有“REAL+RIGHT”和“REAL+LEFT”,表示示这端安装在机架的后面,而标有“FRONT+RIGHT”和“FRONT+LEFT”的两端则安装在机架的前面:2.1 将标有"REAL RIGHT"的一端扣在机架后面的孔上2.2 将标有"FRONT RIGHT"的一端扣在机架前面的孔上2.3 将左右两侧导轨分别安装的机架上后,如下图所示3.组合固定3.1 将导轨里的小导片抽出3.2 将安装在服务器两侧上的导片分别插入机架的导轨片中3.3 将服务器顺着导轨推入参考资料HPDL380服务器机架安装示意图戴尔机架式服务器1U导轨安装教程戴尔服务器r730怎么安装到机架上机架服务器安装说明
-
-
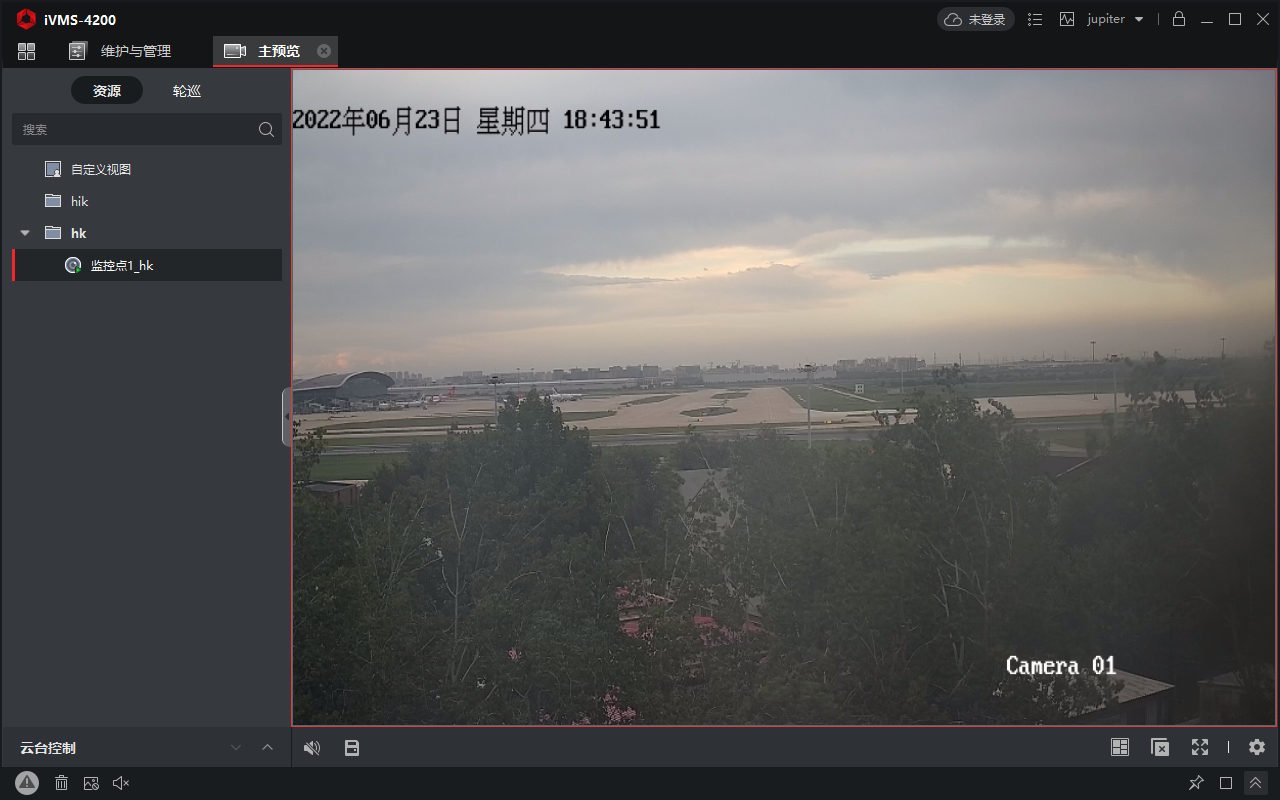
海康威视监控摄像头使用指南 1.设备连接12v电源+网线2.通过设备网络搜索软件找到设备IP下载地址https://www.hikvision.com/cn/support/Downloads/Desktop-Application/HikvisionTools/运行界面3.通过网页访问访问地址:http://10.1.9.31/首次使用需要配置用户名和密码登录用户名:admin 密码:!itrb1234.下载客户端访问下载地址https://www.hikvision.com/cn/support/Downloads/Desktop-Application/Client-Application/客户端使用
-
linux搭建ntp时间同步服务器 1.NTP简介NTP是Network Time Protocol的缩写,又称为网络时间协议。是用来使计算机时间同步化的一种协议,它可以使计算机对其服务器或时钟源(如石英钟,GPS等等)做同步化,它可以提供高精准度的时间校正(LAN上与标准间差小于1毫秒,WAN上几十毫秒),且可介由加密确认的方式来防止恶毒的协议。为用户提供授时服务,并且这些网站间应该能够相互比对,提高准确度。2.服务器配置2.1 安装sudo apt-get install ntp2.2 修改配置(利用server设定上层NTP服务器)sudo vim /etc/ntp.conf上层NTP服务器的设定方式为:server [IP OR HOSTNAME] [PREFER]常见的时间服务器server 2.cn.pool.ntp.org server 3.asia.pool.ntp.org server 0.cn.pool.ntp.org写入到配置文件启动ntp服务/etc/init.d/ntp start3.客户端使用服务同步时间sudo apt install ntpdate ntpdate ${服务器IP}root@wky:~# ntpdate amd.inat.top 19 Jun 01:02:33 ntpdate[3236]: step time server 10.1.131.250 offset 13812059.680274 sec root@wky:~# date 2022年 06月 19日 星期日 01:02:39 +09参考资料Ubuntu搭建NTP服务器ubuntu安装ntp服务器(linux配置ntp服务器)
-
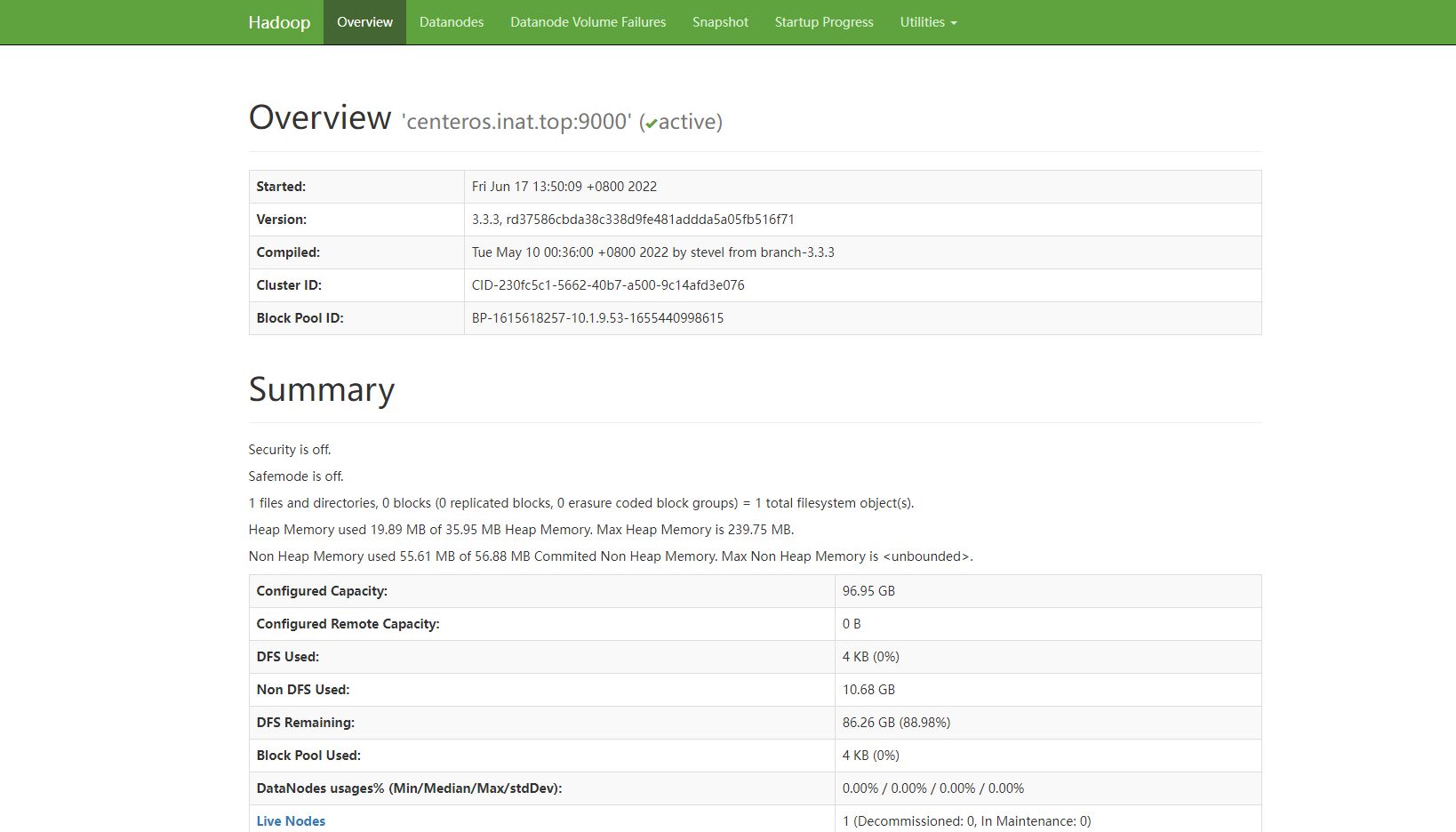
Linux搭建搭建Hadoop环境 1.准备工作1.1 准备机器准备若干台Linux的机器(1-n),物理机虚拟机均可1.2 关闭selinux(每台机器)sudo vim /etc/sysconfig/selinuxreboot1.3 安装JDK(每台机器)下载解压jdkcd /software tar -zxvf jdk-8u201-linux-x64.tar.gz mv jdk1.8.0_201/ java修改环境变量,在末尾添加如下内容sudo vim /etc/profileexport JAVA_HOME=/software/java export PATH="$JAVA_HOME/bin:$PATH"source /etc/profile验证(注意如果是openjdk版本的把openjdk版本的删除掉)(base) [jupiter@centeros bin]$ java -version java version "1.8.0_201" Java(TM) SE Runtime Environment (build 1.8.0_201-b09) Java HotSpot(TM) 64-Bit Server VM (build 25.201-b09, mixed mode)2.搭建hadoop伪分布式(单节点)2.1 下载并解压hadoop官网:https://hadoop.apache.org/cd /software wget https://www.apache.org/dyn/closer.cgi/hadoop/common/hadoop-3.3.1/hadoop-3.3.3.tar.gz tar -xzvf hadoop-3.3.3.tar.gz mv hadoop-3.3.3 hadoop cd hadoop配置相关环境变量sudo vim /etc/profile # 加入如下内容 #HADOOP_HOME export HADOOP_HOME=/software/hadoop export PATH=$PATH:$HADOOP_HOME/bin export PATH=$PATH:$HADOOP_HOME/sbinsource /etc/profile2.2 修改hadoop相关配置主要需要配置四个文件,对应hadoop四大模块,均位于etc/hadoop下面hadoop四大模块common:core-site.xmlcommon 及核心公共模块,默认配置(core-site.xml),主要包括Hadoop常用的工具类,由原来的Hadoopcore部分更名而来。主要包括系统配置工具Configuration、远程过程调用RPC、序列化机制和Hadoop抽象文件系统FileSystem等。它们为在通用硬件上搭建云计算环境提供基本的服务,并为运行在该平台上的软件开发提供了所需的APIhdfs (hadoop distribute file system):hdfs-site.xml分布式文件系统,提供对应用程序数据的高吞吐量,高伸缩性,高容错性的访问。是Hadoop体系中数据存储管理的基础。它是一个高度容错的系统,能检测和应对硬件故障,用于在低成本的通用硬件上运行。通过流式数据访问,提供高吞吐量应用程序数据访问功能,适合带有大型数据集的应用程序。(namenode+datanode+secondarynode)mapreduce:mapred-site.xmlmapreduce 是一种分而治之思想,是一种计算模型,用以进行大数据量的计算。Hadoop的MapReduce实现,和Common、HDFS一起,构成了Hadoop发展初期的三个组件。MapReduce将应用划分为Map和Reduce两个步骤,其中Map对数据集上的独立元素进行指定的操作,生成键-值对形式中间结果。mapreduce的运行流程 input->map->shuffle->reduce->output 。input 数据输入文件分片,map负责就进数据处理,多个mapper之间并行处理,shuffle负责数据混淆分区、排序、拷贝、分组、压缩等操作,完成后将数据传给reduce进行处理,reduce负责对map阶段的数据进行汇总。yarn:yarn-site.xmlYarn是Hadoop集群的资源管理系统,由两部分功能组成资源管理和任务调度监控主要的组件,ResourceManager:Global(全局)的进程 ;NodeManager:运行在每个节点上的进程,ApplicationMaster:Application-specific(应用级别)的进程,向rm申请资源,对运行在datanode的应用进行监控;Scheduler:是ResourceManager的一个组件,Container:节点上一组CPU和内存资源容器。core-site.xml<configuration> <!-- 指定HDFS老大(namenode)的通信地址 --> <property> <name>fs.defaultFS</name> <value>hdfs://localhost:9000</value> </property> <property> <!-- 指定hadoop运行时产生文件的存储路径 --> <name>hadoop.tmp.dir</name> <value>/software/hadoop/tmp</value> </property> </configuration>hdfs-site.xml<configuration> <!--配置hdfs副本数量--> <property> <name>dfs.replication</name> <value>1</value> </property> </configuration>mapred-site.xml<configuration> <!-- 通知框架MR使用YARN --> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> </configuration>yarn-site.xml<configuration> <!-- 通知框架MR使用YARN --> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> </configuration>2.3 运行Hadoop修改etc/hadoop/hadoop-env.shexport JAVA_HOME="/software/java"初始化HDFS系统hdfs namenode -format启动hadoop#先启动HDFS sbin/start-dfs.sh #再启动YARN sbin/start-yarn.sh查看进程信息jps(base) [jupiter@centeros hadoop]$ jps 32613 SecondaryNameNode 374 ResourceManager 903 Jps 521 NodeManager 32222 NameNode4.验证http://centeros.inat.top:9870/:HDFS管理界面http://centeros.inat.top:8088/:MapReduce管理界面3.搭建hadoop分布式(集群)参考:https://github.com/AdamJupiter/BigData/blob/master/hadoop%E9%9B%86%E7%BE%A4%E6%90%AD%E5%BB%BA/hadoop2.0%E9%9B%86%E7%BE%A4%E6%90%AD%E5%BB%BA.md参考资料centeros安装java8hadoop伪分布式环境搭建,完整的详细步骤Hadoop-单节点配置hadoop常用配置文件https://github.com/AdamJupiter/hadoop-guide
-
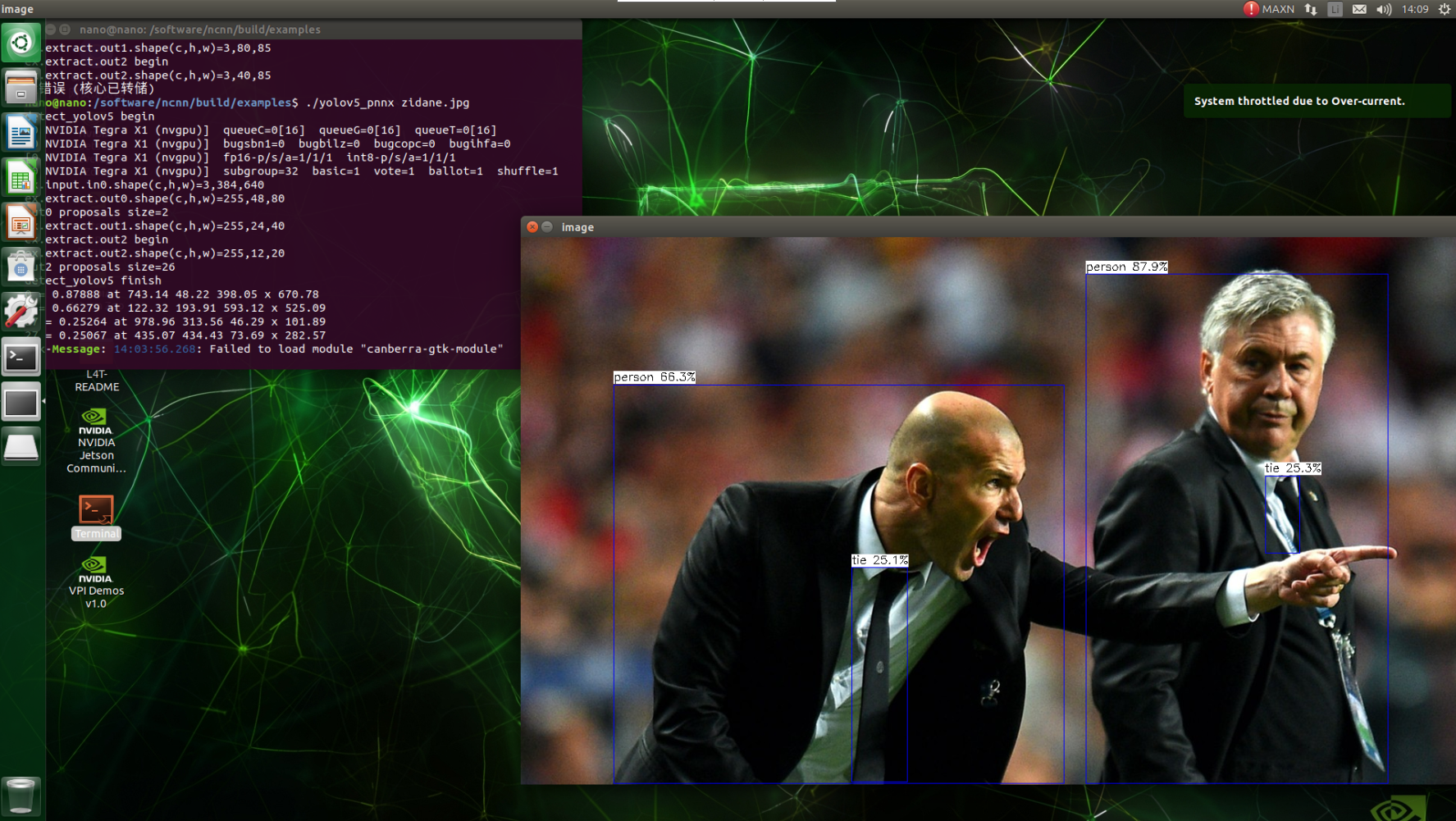
NCNN部署yolov5s 1.NCNN编译安装参考:Linux下如何安装ncnn2.模型转换(pt->onnx->ncnn)$\color{red}{此路不通,转出来的param文件中的Reshape的参数是错的}$2.1 pt模型转换onnx# pt-->onnx python export.py --weights yolov5s.pt --img 640 --batch 1#安装onnx-simplifier pip install onnx-simplifier # onnxsim 精简模型 python -m onnxsim yolov5s.onnx yolov5s-sim.onnx Simplifying... Finish! Here is the difference: ┏━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━┓ ┃ ┃ Original Model ┃ Simplified Model ┃ ┡━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━┩ │ Add │ 10 │ 10 │ │ Concat │ 17 │ 17 │ │ Constant │ 20 │ 0 │ │ Conv │ 60 │ 60 │ │ MaxPool │ 3 │ 3 │ │ Mul │ 69 │ 69 │ │ Pow │ 3 │ 3 │ │ Reshape │ 6 │ 6 │ │ Resize │ 2 │ 2 │ │ Sigmoid │ 60 │ 60 │ │ Split │ 3 │ 3 │ │ Transpose │ 3 │ 3 │ │ Model Size │ 28.0MiB │ 28.0MiB │ └────────────┴────────────────┴──────────────────┘2.2 使用onnx2ncnn.exe 转换模型把你的ncnn/build/tools/onnx加入到环境变量onnx2ncnn yolov5s-sim.onnx yolov5s_6.0.param yolov5s_6.0.bin2.3 调用测试将yolov5s_6.0.param 、yolov5s_6.0.bin模型copy到ncnn/build/examples/位置,运行下面命令./yolov5 image-path就会出现Segmentation fault (core dumped)的报错3.模型转换(pt->torchscript->ncnn)3.1 pt模型转换torchscript# pt-->torchscript python export.py --weights yolov5s.pt --include torchscript --train3.2 下载编译好的 pnnx 工具包执行转换pnnx下载地址:https://github.com/pnnx/pnnx执行转换,获得 yolov5s.ncnn.param 和 yolov5s.ncnn.bin 模型文件,指定 inputshape 并且额外指定 inputshape2 转换成支持动态 shape 输入的模型 ./pnnx yolov5s.torchscript inputshape=[1,3,640,640] inputshape2=[1,3,320,320]3.3 调用测试直接测试的相关文件下载:yolov5_pnnx.zip将 yolov5s.ncnn.param 和 yolov5s.ncnn.bin 模型copy到ncnn/build/examples/位置,运行下面命令./yolov5_pnnx image-path参考资料yolov5 模型部署NCNN(详细过程)Linux&Jetson Nano下编译安装ncnnYOLOv5转NCNN过程Jetson Nano 移植ncnn详细记录u版YOLOv5目标检测ncnn实现(第二版)
-
Jetson nano开启VNC 1.nano设置VNC服务1.执行更新sudo apt-get update2.安装vino服务端这个vino服务端我使用的镜像文件是安装好了的,但是古早版的镜像文件可能没有,所以可以执行下代码看看是否有安装。sudo apt-get install vino3.开启VNC 服务sudo ln -s ../vino-server.service /usr/lib/systemd/user/graphical-session.target.wants4.配置VNC服务gsettings set org.gnome.Vino prompt-enabled false gsettings set org.gnome.Vino require-encryption false5.编辑org.gnome用于恢复丢失的“enabled”参数,用于vnc允许使用RFB 协议进行远程控制输入以下命令进入文件,将下方key内容添加到文件的最后面。保存并退出。sudo vim /usr/share/glib-2.0/schemas/org.gnome.Vino.gschema.xml添加的文件内容如下<key name='enable' type='b'> <summary>Enable remote access to the desktop</summary> <description> If true, allows remote access to the desktop via the RFB protocol. Users on remote machines may then connect to the desktop using a VNC viewer. </description> <default>false</default> </key>6.设置为Gnome编译模式,编译以上的文件sudo glib-compile-schemas /usr/share/glib-2.0/schemas7. 在会话启动时添加程序:Vino-server,使用以下命令行:/usr/lib/vino/vino-server8.连接测试2.设置开机自启动1.允许vino服务gsettings set org.gnome.Vino enabled true2.创建VNC自动启动文件创建文件夹,然后创建一个自动启动文件mkdir -p ~/.config/autostart sudo vim ~/.config/autostart/vino-server.desktop3.添加以下内容到vino-server.desktop文件中[Desktop Entry] Type=Application Name=Vino VNC server Exec=/usr/lib/vino/vino-server NoDisplay=true提示:需要进入界面后才自动启动,建议取消登录密码进入界面。参考资料Jetson nano 通过 vnc 实现远程桌面控制(已在nano实现)
-
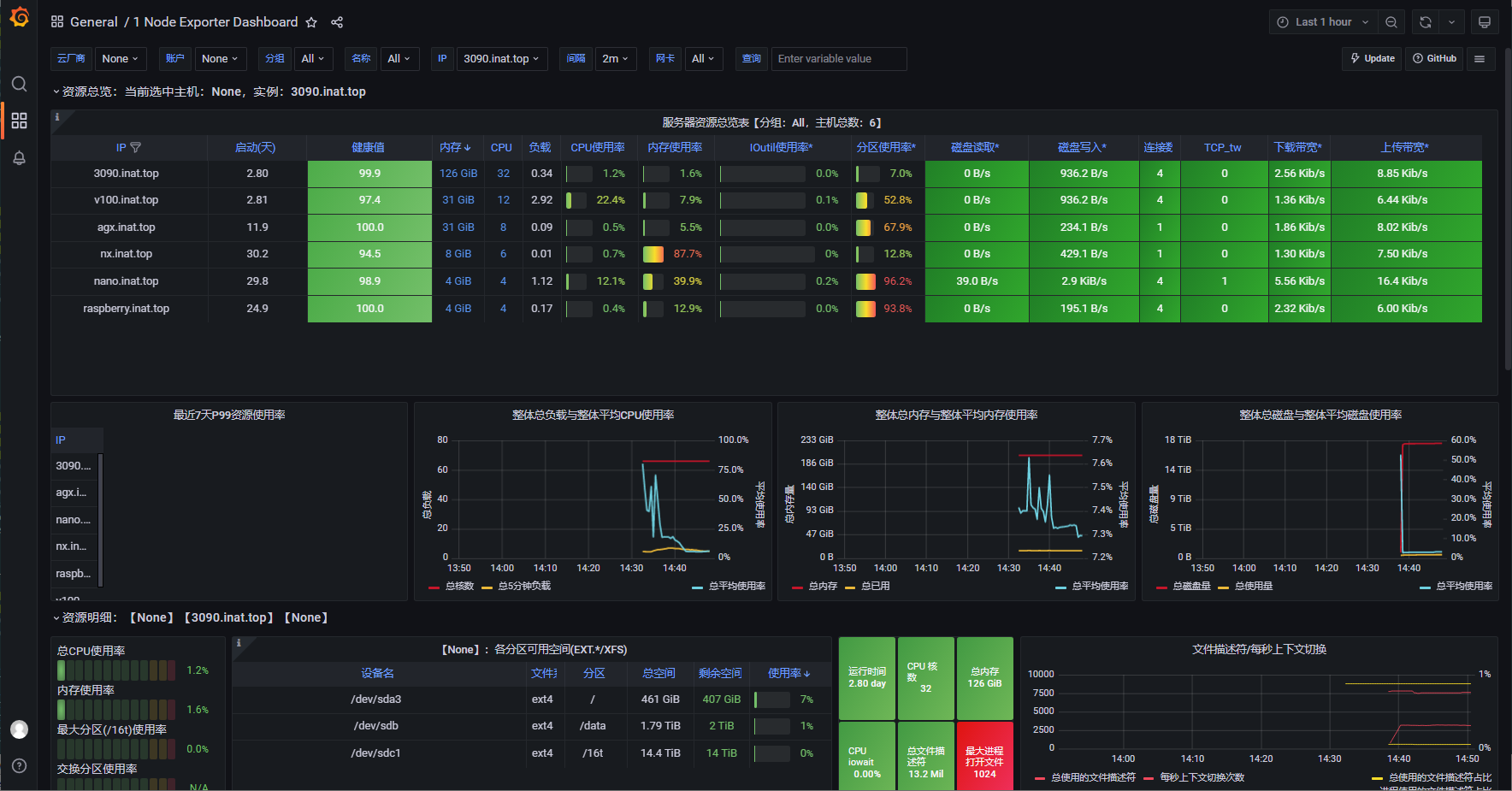
Prometheus+Grafana:Linux设备群监控系统 1.Prometheus1.1. Prometheus简介Prometheus 是一款基于时序数据库的开源监控告警系统,非常适合Kubernetes集群的监控。Prometheus的基本原理是通过HTTP协议周期性抓取被监控组件的状态,任意组件只要提供对应的HTTP接口就可以接入监控。不需要任何SDK或者其他的集成过程。这样做非常适合做虚拟化环境监控系统,比如VM、Docker、Kubernetes等。输出被监控组件信息的HTTP接口被叫做exporter 。目前互联网公司常用的组件大部分都有exporter可以直接使用,比如Varnish、Haproxy、Nginx、MySQL、Linux系统信息(包括磁盘、内存、CPU、网络等等)。Promethus有以下特点:支持多维数据模型:由度量名和键值对组成的时间序列数据内置时间序列数据库TSDB支持PromQL查询语言,可以完成非常复杂的查询和分析,对图表展示和告警非常有意义支持HTTP的Pull方式采集时间序列数据支持PushGateway采集瞬时任务的数据支持服务发现和静态配置两种方式发现目标支持接入Grafana1.2. Prometheus架构1.2.1. Prometheus Server主要负责数据采集和存储,提供PromQL查询语言的支持。包含了三个组件:Retrieval: 获取监控数据TSDB: 时间序列数据库(Time Series Database),我们可以简单的理解为一个优化后用来处理时间序列数据的软件,并且数据中的数组是由时间进行索引的。具备以下特点:大部分时间都是顺序写入操作,很少涉及修改数据删除操作都是删除一段时间的数据,而不涉及到删除无规律数据读操作一般都是升序或者降序HTTP Server: 为告警和出图提供查询接口1.2.2. 指标采集Exporters: Prometheus的一类数据采集组件的总称。它负责从目标处搜集数据,并将其转化为Prometheus支持的格式。与传统的数据采集组件不同的是,它并不向中央服务器发送数据,而是等待中央服务器主动前来抓取Pushgateway: 支持临时性Job主动推送指标的中间网关1.2.3. 服务发现Kubernetes_sd: 支持从Kubernetes中自动发现服务和采集信息。而Zabbix监控项原型就不适合Kubernets,因为随着Pod的重启或者升级,Pod的名称是会随机变化的。file_sd: 通过配置文件来实现服务的自动发现1.2.4. 告警管理通过相关的告警配置,对触发阈值的告警通过页面展示、短信和邮件通知的方式告知运维人员。1.2.5. 图形化展示通过PromQL语句查询指标信息,并在页面展示。虽然Prometheus自带UI界面,但是大部分都是使用Grafana出图。另外第三方也可以通过 API 接口来获取监控指标。2.Prometheus简单部署2.1 部署和配置prometheus(在监控中心布置)下载prometheus(网页下载地址:https://prometheus.io/download/)wget https://github.com/prometheus/prometheus/releases/download/v2.36.1/prometheus-2.36.1.linux-amd64.tar.gz tar -xvf prometheus-2.36.1.linux-amd64.tar.gz mv prometheus-2.36.1.linux-amd64 prometheus cd prometheus修改配置文件vim prometheus.yml# my global config global: scrape_interval: 15s # Set the scrape interval to every 15 seconds. Default is every 1 minute. evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is every 1 minute. # scrape_timeout is set to the global default (10s). # Alertmanager configuration alerting: alertmanagers: - static_configs: - targets: # - alertmanager:9093 # Load rules once and periodically evaluate them according to the global 'evaluation_interval'. rule_files: # - "first_rules.yml" # - "second_rules.yml" # A scrape configuration containing exactly one endpoint to scrape: # Here it's Prometheus itself. scrape_configs: # The job name is added as a label `job=<job_name>` to any timeseries scraped from this config. - job_name: "prometheus" # metrics_path defaults to '/metrics' # scheme defaults to 'http'. static_configs: - targets: ["localhost:9090"] # node_exporter 监控数据采集 - job_name: 'node' static_configs: - targets: - "3090.inat.top:9100" - "v100.inat.top:9100" - "raspberry.inat.top:9100" - "agx.inat.top:9100" - "nx.inat.top:9100" - "nano.inat.top:9100"检查配置文件./promtool check config prometheus.yml启动测试./prometheus配置开机自启动sudo vim /etc/systemd/system/prometheus.service[Unit] Description=prometheus service After=network.target [Service] ExecStart=/software/prometheus/prometheus --config.file=/software/prometheus/prometheus.yml Restart=always RestartSec=20 TimeoutSec=300 User=root Group=root StandardOutput=journal StandardError=journal WorkingDirectory=/software/prometheus/ [Install] WantedBy=default.targetsudo systemctl daemon-reload sudo systemctl start prometheus.service sudo systemctl enable prometheus.servicesudo systemctl status prometheus.service2.2 部署Node-Exporter(在被监控的机器上布置)下载Node-Exporter(网页下载地址:https://prometheus.io/download/)wget https://github.com/prometheus/node_exporter/releases/download/v1.0.1/node_exporter-1.0.1.linux-amd64.tar.gz tar -xvf node_exporter-1.0.1.linux-amd64.tar.gz mv node_exporter-1.0.1.linux-amd64 node_exporter cd node_exporter创建monitor用户和组sudo groupadd -g 9100 monitor sudo useradd -g 9100 -u 9100 -s /sbin/nologin -M monitor修改对应文件夹的权限sudo chown -R monitor.monitor /software/node_exporter启动测试./node_exporter配置开机自启动sudo vim /etc/systemd/system/node_exporter.service[Unit] Description=node-exporter service After=network.target [Service] User=monitor Group=monitor KillMode=control-group Restart=on-failure RestartSec=60 ExecStart=/software/node_exporter/node_exporter [Install] WantedBy=multi-user.targetsudo systemctl daemon-reload sudo systemctl start node_exporter.service sudo systemctl enable node_exporter.servicesudo systemctl status node_exporter.service3.部署Grafana(在监控中心部署)下载Grafana(网页下载地址:https://grafana.com/grafana/download)sudo apt-get install -y adduser libfontconfig1 wget https://dl.grafana.com/enterprise/release/grafana-enterprise_8.5.5_amd64.deb sudo dpkg -i grafana-enterprise_8.5.5_amd64.deb设置开机自启动 sudo /bin/systemctl daemon-reload sudo /bin/systemctl start grafana-server sudo /bin/systemctl enable grafana-server sudo /bin/systemctl status grafana-server访问测试(默认用户名和密码均为admin)添加数据源添加dashbord查看dashbord参考资料Prometheus看完这些,入门就够了Prometheus 重启失败的教训Prometheus(普罗米修斯)监控Prometheus(普罗米修斯)监控系统(一)https://grafana.com/grafana/downloadhttps://prometheus.io/download/
-
解决vscode卡顿问题 最近vscode突然变得异常卡顿,不知道什么原因,编辑个文件都费劲,于是查找了一些资料对配置进行修改,并记录如下1.修复VScode 造成 rg.exe内存占用过大的问题1)在VScode环境下,依次“文件”菜单->“首选项”->“设置”2)在搜索框中输入“Search:Follow Symlinks”搜索,将该项之前的复选框√去掉;如下图所示。2. 修复VScode 造成 git.exe内存占用过大的问题1)在VScode环境下,依次“文件”菜单->“首选项”->“设置”2)在搜索框中输入“Git:Autorefresh”搜索,将该项之前的复选框√去掉;如下图所示。3)在搜索框中输入“Git.Enabled”搜索,将该项之前的复选框√去掉;如下图所示。3.关闭chrome硬件加速打开Chorme浏览器 -> 设置 ->系统 ->将【启用硬件加速模式】取消勾选即可4.重启VScode生效做完以上操作你会惊喜的发现,VSCode恢复到以前的流畅了。参考资料解决VSCode无缘无故卡顿的问题使用VSCode环境进行开发,突然出现卡顿、打字显示缓慢,滚动、选择迟缓、软件崩溃等问题解决 vscode 卡顿,卡死,占用内存大的方案
-
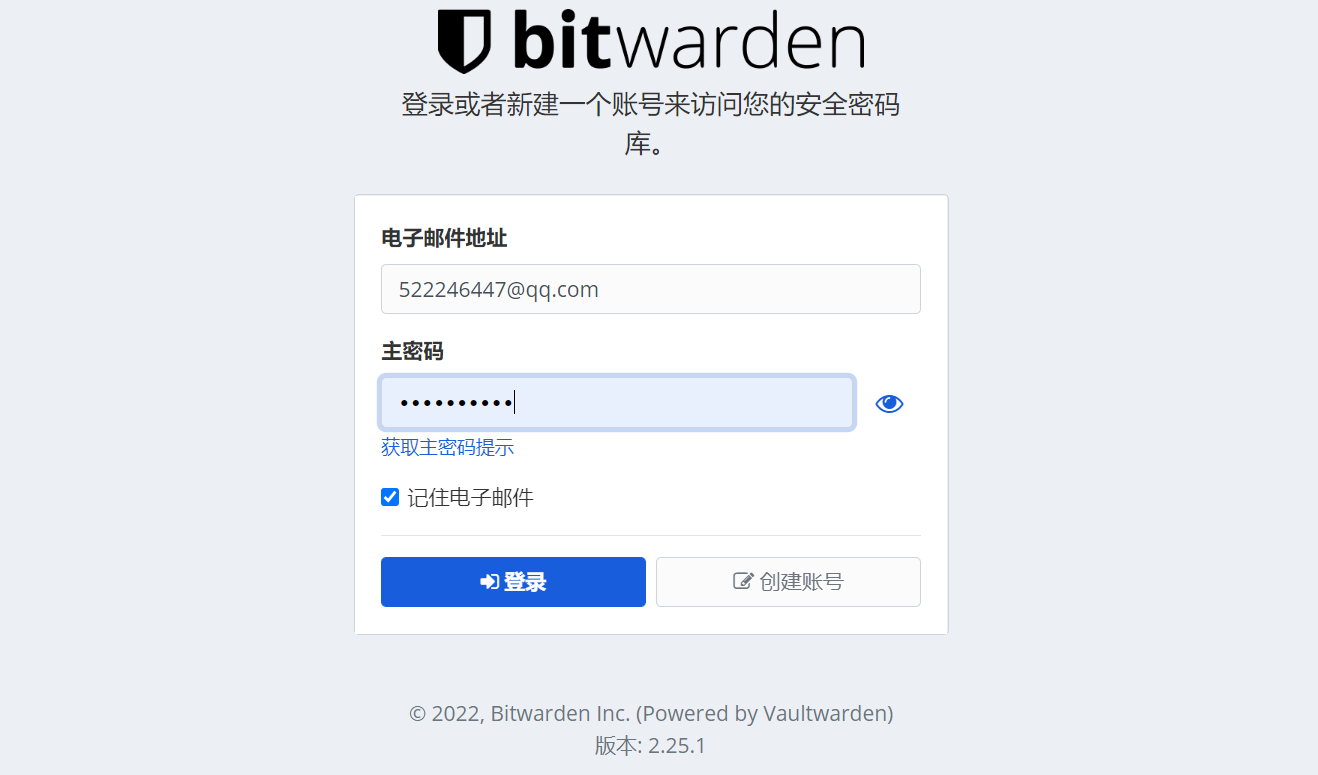
Bitwarden:搭建自己的密码管理服务器 0.应用背景各种杂七杂八的APP实在太多了,使用统一密码容易导致密码泄露,使用不同的密码容易记不住,将密码存在第三方也怕会发生数据泄露和服务商倒闭,因此自行考虑搭建密码管理工具1.搭建步骤1.1 安装docker宝塔在软件商店安装Docker管理器即可,其它使用命令行安装sudo apt update sudo apt install docker.io1.2 拉取 vaultwarden/server镜像[备注:老版bitwardenrs/server和手机APP不兼容]docker pull vaultwarden/server1.3 运行容器docker run -d --name vaultwarden -v /vw-data/:/data/ -p 60080:80 vaultwarden/server:latest备注:-v /vw-data/:/data/为必须,否则会出现如下 No persistent volume 报错:/--------------------------------------------------------------------\ | Starting Vaultwarden | | Version 1.30.5 | |--------------------------------------------------------------------| | This is an *unofficial* Bitwarden implementation, DO NOT use the | | official channels to report bugs/features, regardless of client. | | Send usage/configuration questions or feature requests to: | | https://github.com/dani-garcia/vaultwarden/discussions or | | https://vaultwarden.discourse.group/ | | Report suspected bugs/issues in the software itself at: | | https://github.com/dani-garcia/vaultwarden/issues/new | \--------------------------------------------------------------------/ [2024-03-21 13:46:40.290][vaultwarden][ERROR] No persistent volume! ######################################################################################## # It looks like you did not configure a persistent volume! # # This will result in permanent data loss when the container is removed or updated! # # If you really want to use volatile storage set `I_REALLY_WANT_VOLATILE_STORAGE=true` # 1.4 通过nginx创建网站1.5 开启SSL1.6 添加反向代理1.7 访问测试参考资料密码管理 Bitwarden服务端部署文档搭建自己的密码管理服务器 Bitwarden使用云服务器+docker搭建私有密码库Vaultwarden_docker安装vaultwarden-CSDN博客自建Vaultwarden (Bitwarden) 无法登陆问题的解决办法 - FREEZhao
-
ubuntu挂载新硬盘 1.定位新硬盘(base) 3090@3090:~$ lsblk NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT sdb 8:16 0 1.8T 0 disk /data sr0 11:0 1 1024M 0 rom sdc 8:32 0 14.6T 0 disk └─sdc1 8:33 0 14.6T 0 part sda 8:0 0 477G 0 disk ├─sda2 8:2 0 7.6G 0 part [SWAP] ├─sda3 8:3 0 468.4G 0 part / └─sda1 8:1 0 976M 0 part /boot/efi发现待挂载的硬盘为sdc12.硬盘格式化mkfs -t ext4 /dev/sdc1mke2fs 1.42.13 (17-May-2015) /dev/sdc1 contains a xfs file system Proceed anyway? (y,n) y Creating filesystem with 3906469376 4k blocks and 488308736 inodes Filesystem UUID: ed6952c9-b147-4cfb-b68f-d79e4fcecbb5 Superblock backups stored on blocks: 32768, 98304, 163840, 229376, 294912, 819200, 884736, 1605632, 2654208, 4096000, 7962624, 11239424, 20480000, 23887872, 71663616, 78675968, 102400000, 214990848, 512000000, 550731776, 644972544, 1934917632, 2560000000, 3855122432 Allocating group tables: done Writing inode tables: done Creating journal (32768 blocks): done Writing superblocks and filesystem accounting information: done3.挂载3.1 手动挂载挂载到挂载点/16tsudo mount /dev/sdc1 /16t查看挂载结果(base) 3090@3090:~$ df -h Filesystem Size Used Avail Use% Mounted on udev 63G 0 63G 0% /dev tmpfs 13G 19M 13G 1% /run /dev/sda3 461G 31G 407G 8% / tmpfs 63G 180K 63G 1% /dev/shm tmpfs 5.0M 4.0K 5.0M 1% /run/lock tmpfs 63G 0 63G 0% /sys/fs/cgroup /dev/sdb 1.8T 9.2G 1.7T 1% /data /dev/sda1 975M 4.3M 970M 1% /boot/efi tmpfs 13G 64K 13G 1% /run/user/1000 tmpfs 13G 0 13G 0% /run/user/1001 /dev/sdc1 15T 9.1M 14T 1% /16t3.2 配置开机自动挂载查看UUID(base) 3090@3090:~$ sudo blkid /dev/sdc1 /dev/sdc1: UUID="ed6952c9-b147-4cfb-b68f-d79e4fcecbb5" TYPE="ext4" PARTLABEL="primary" PARTUUID="bbcf63f5-3927-41e8-abc6-ca9062aec08c"修改/etc/fstabsudo vim /etc/fstab# 在末尾添加如下内容 UUID=ed6952c9-b147-4cfb-b68f-d79e4fcecbb5 /16t auto defaults 0 0 参考资料Ubuntu中查看硬盘分区UUID的方法(所有Linux目录的解释)ubuntu 挂载硬盘指令fstab挂载参数
-
ubunt设置静态IP 1.查看网卡名,确定需要配置的目标网卡ip a1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000 link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00 inet 127.0.0.1/8 scope host lo valid_lft forever preferred_lft forever inet6 ::1/128 scope host valid_lft forever preferred_lft forever 2: enp0s25: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000 link/ether d8:9e:f3:35:c3:66 brd ff:ff:ff:ff:ff:ff inet 10.1.9.50/24 brd 10.1.9.255 scope global enp0s25 valid_lft forever preferred_lft forever inet6 2001:da8:a012:2da:f3c5:dc14:1316:2268/64 scope global noprefixroute dynamic valid_lft 2591982sec preferred_lft 604782sec inet6 fe80::e49c:f19c:2e03:e014/64 scope link valid_lft forever preferred_lft forever 3: enp8s0: <NO-CARRIER,BROADCAST,MULTICAST,UP> mtu 1500 qdisc mq state DOWN group default qlen 1000 link/ether d8:9e:f3:35:c3:74 brd ff:ff:ff:ff:ff:ff2.对指定网卡enp0s25设置固定IPsudo vim /etc/network/interfaces增加如下内容auto enp0s25 # 设置自动启动enp0s25接口 iface enp0s25 inet static # 配置静态IP address 10.1.9.67 # IP地址 netmask 255.255.255.0 # 子网掩码 gateway 10.1.9.1 # 网关3.重启网络sudo /etc/init.d/networking restart参考资料ubuntu 查看网卡的网关_Ubuntu系统怎么设置静态ip?同样适用于深度系统的教程Ubuntu系统设置静态IP