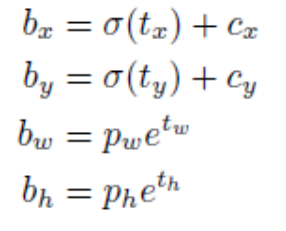搜索到
32
篇与
的结果
-
 帧差法+三帧差法原理与实现 帧差法原理移动侦测即是根据视频每帧或者几帧之间像素的差异,对差异值设置阈值,筛选大于阈值的像素点,做掩模图即可选出视频中存在变化的桢。帧差法较为简单的视频中物体移动侦测,帧差法分为:单帧差和三桢差。随着帧数的增加是防止检测结果的重影。单帧差法算法原理以视频为例进行单帧差法移动侦测算法实现import cv2 import pandas as pd import numpy as np video_path = "./test.mp4" cam = cv2.VideoCapture(video_path) # 打开一个视频 input_fps = cam.get(cv2.CAP_PROP_FPS) # 获取视频帧率 ret_val, input_image = cam.read() # 读取视频第一帧 gray_lwpCV = cv2.cvtColor(input_image, cv2.COLOR_BGR2GRAY) # 将第一帧转为灰度 gray_lwpCV = cv2.GaussianBlur(gray_lwpCV, (21, 21), 0) # 对转换后的灰度图进行高斯模糊 background=gray_lwpCV # 将高斯模糊后的第一帧作为初始化背景 area_threh = 100 # 物体bbox面积阈值 while(cam.isOpened()) and ret_val == True: ret_val, input_image = cam.read() # 继续读取视频帧 gray_lwpCV = cv2.cvtColor(input_image, cv2.COLOR_BGR2GRAY) gray_lwpCV = cv2.GaussianBlur(gray_lwpCV, (21, 21), 0) # 对读取到的视频帧进行灰度处理+高斯模糊 diff = cv2.absdiff(background, gray_lwpCV) # 将最新读取的视频帧和背景做差 #跟着图像变换背景,如果背景变化区域小于20%或者75%,则将当前帧作为新得背景区域 tem_diff=diff.flatten() tem_ds=pd.Series(tem_diff) tem_per=1-len(tem_ds[tem_ds==0])/len(tem_ds) if (tem_per <0.2 )| (tem_per>0.75): background=gray_lwpCV else: ret,diff_binary = cv2.threshold(diff, 10, 255, cv2.THRESH_BINARY)# 对差值diff进行二值化 contours, hierarchy = cv2.findContours(diff_binary,cv2.RETR_EXTERNAL,cv2.CHAIN_APPROX_SIMPLE) # 对二值化之后得结果进行轮廓提取 for c in contours: if (cv2.contourArea(c) < area_threh): # 对于矩形区域,只显示大于给定阈值的轮廓(去除微小的变化等噪点) continue (x, y, w, h) = cv2.boundingRect(c) # 该函数计算矩形的边界框 cv2.rectangle(input_image, (x, y), (x+w, y+h), (0, 255, 0), 2) cv2.imshow('frame diff', np.hstack((input_image,cv2.cvtColor(diff,cv2.COLOR_GRAY2BGR)))) if cv2.waitKey(50)&0xFF==ord("q"): break cam.release() cv2.destroyAllWindows()实现效果算法分析优点实现简单,运行速度快缺点存在"鬼影"问题(指在物体原来得位置和现在得位置都出现了该物体),三帧差法算法原理连续三帧,12相减,23相减,结果做与运算。相减公式:其中阈值T需要手动调整。结果得到一个二值图,对二值图进行形态学处理,再进行轮廓提取。算法实现 import cv2 import numpy as np video_path = "./test.mp4" cap = cv2.VideoCapture(video_path) width =int(cap.get(cv2.CAP_PROP_FRAME_WIDTH)) height =int(cap.get(cv2.CAP_PROP_FRAME_HEIGHT)) # 初始化第1.2.3帧 one_frame = np.zeros((height,width),dtype=np.uint8) two_frame = np.zeros((height,width),dtype=np.uint8) three_frame = np.zeros((height,width),dtype=np.uint8) area_threh = 100 # 物体bbox面积阈值 while cap.isOpened(): ret,frame = cap.read() frame_gray =cv2.cvtColor(frame,cv2.COLOR_BGR2GRAY) if not ret: break one_frame,two_frame,three_frame = two_frame,three_frame,frame_gray # 1.2帧做差 abs1 = cv2.absdiff(one_frame,two_frame)#相减 _,thresh1 = cv2.threshold(abs1,15,255,cv2.THRESH_BINARY)#二值,大于40的为255,小于0 # 2.3帧做差 abs2 =cv2.absdiff(two_frame,three_frame) _,thresh2 =cv2.threshold(abs2,15,255,cv2.THRESH_BINARY) binary =cv2.bitwise_and(thresh1,thresh2)#与运算 kernel = cv2.getStructuringElement(cv2.MORPH_ELLIPSE,(5,5)) # erode = cv2.erode(binary,kernel)#腐蚀 # dilate =cv2.dilate(binary,kernel)#膨胀 # dilate =cv2.dilate(dilate,kernel)#膨胀 # 轮廓提取 contours, hierarchy = cv2.findContours(binary.copy(),mode=cv2.RETR_EXTERNAL,method=cv2.CHAIN_APPROX_SIMPLE)#寻找轮廓 for contour in contours: if cv2.contourArea(contour)>area_threh: x,y,w,h =cv2.boundingRect(contour)#找方框 cv2.rectangle(frame,(x,y),(x+w,y+h),(0,255,0), 2) img_show = np.hstack((frame,cv2.cvtColor(binary,cv2.COLOR_GRAY2BGR))) cv2.imshow('three frame diff',img_show) if cv2.waitKey(50)&0xFF==ord("q"): break cap.release() cv2.destroyAllWindows()实现效果不进行形态学处理膨胀一次膨胀两次先腐蚀一次,再膨胀两次算法分析优点实现简单,运行速度快解决了帧差法存在的“鬼影”问题能大致检测出物体的运动区域缺点不进行膨胀会存在“空洞”问题进行膨胀之后会存在着多个物体的”牵连“问题对物体的运动区域的检测不够全面eg:对于部分人运动区域的检测会存在着只检测出半个人的情况参考资料python+opencv实现移动侦测(帧差法):https://www.jb51.net/article/183203.htmopencv python 三帧差法实现运动目标区域检测与完整代码:https://blog.csdn.net/pengpengloveqiaoqiao/article/details/89487049
帧差法+三帧差法原理与实现 帧差法原理移动侦测即是根据视频每帧或者几帧之间像素的差异,对差异值设置阈值,筛选大于阈值的像素点,做掩模图即可选出视频中存在变化的桢。帧差法较为简单的视频中物体移动侦测,帧差法分为:单帧差和三桢差。随着帧数的增加是防止检测结果的重影。单帧差法算法原理以视频为例进行单帧差法移动侦测算法实现import cv2 import pandas as pd import numpy as np video_path = "./test.mp4" cam = cv2.VideoCapture(video_path) # 打开一个视频 input_fps = cam.get(cv2.CAP_PROP_FPS) # 获取视频帧率 ret_val, input_image = cam.read() # 读取视频第一帧 gray_lwpCV = cv2.cvtColor(input_image, cv2.COLOR_BGR2GRAY) # 将第一帧转为灰度 gray_lwpCV = cv2.GaussianBlur(gray_lwpCV, (21, 21), 0) # 对转换后的灰度图进行高斯模糊 background=gray_lwpCV # 将高斯模糊后的第一帧作为初始化背景 area_threh = 100 # 物体bbox面积阈值 while(cam.isOpened()) and ret_val == True: ret_val, input_image = cam.read() # 继续读取视频帧 gray_lwpCV = cv2.cvtColor(input_image, cv2.COLOR_BGR2GRAY) gray_lwpCV = cv2.GaussianBlur(gray_lwpCV, (21, 21), 0) # 对读取到的视频帧进行灰度处理+高斯模糊 diff = cv2.absdiff(background, gray_lwpCV) # 将最新读取的视频帧和背景做差 #跟着图像变换背景,如果背景变化区域小于20%或者75%,则将当前帧作为新得背景区域 tem_diff=diff.flatten() tem_ds=pd.Series(tem_diff) tem_per=1-len(tem_ds[tem_ds==0])/len(tem_ds) if (tem_per <0.2 )| (tem_per>0.75): background=gray_lwpCV else: ret,diff_binary = cv2.threshold(diff, 10, 255, cv2.THRESH_BINARY)# 对差值diff进行二值化 contours, hierarchy = cv2.findContours(diff_binary,cv2.RETR_EXTERNAL,cv2.CHAIN_APPROX_SIMPLE) # 对二值化之后得结果进行轮廓提取 for c in contours: if (cv2.contourArea(c) < area_threh): # 对于矩形区域,只显示大于给定阈值的轮廓(去除微小的变化等噪点) continue (x, y, w, h) = cv2.boundingRect(c) # 该函数计算矩形的边界框 cv2.rectangle(input_image, (x, y), (x+w, y+h), (0, 255, 0), 2) cv2.imshow('frame diff', np.hstack((input_image,cv2.cvtColor(diff,cv2.COLOR_GRAY2BGR)))) if cv2.waitKey(50)&0xFF==ord("q"): break cam.release() cv2.destroyAllWindows()实现效果算法分析优点实现简单,运行速度快缺点存在"鬼影"问题(指在物体原来得位置和现在得位置都出现了该物体),三帧差法算法原理连续三帧,12相减,23相减,结果做与运算。相减公式:其中阈值T需要手动调整。结果得到一个二值图,对二值图进行形态学处理,再进行轮廓提取。算法实现 import cv2 import numpy as np video_path = "./test.mp4" cap = cv2.VideoCapture(video_path) width =int(cap.get(cv2.CAP_PROP_FRAME_WIDTH)) height =int(cap.get(cv2.CAP_PROP_FRAME_HEIGHT)) # 初始化第1.2.3帧 one_frame = np.zeros((height,width),dtype=np.uint8) two_frame = np.zeros((height,width),dtype=np.uint8) three_frame = np.zeros((height,width),dtype=np.uint8) area_threh = 100 # 物体bbox面积阈值 while cap.isOpened(): ret,frame = cap.read() frame_gray =cv2.cvtColor(frame,cv2.COLOR_BGR2GRAY) if not ret: break one_frame,two_frame,three_frame = two_frame,three_frame,frame_gray # 1.2帧做差 abs1 = cv2.absdiff(one_frame,two_frame)#相减 _,thresh1 = cv2.threshold(abs1,15,255,cv2.THRESH_BINARY)#二值,大于40的为255,小于0 # 2.3帧做差 abs2 =cv2.absdiff(two_frame,three_frame) _,thresh2 =cv2.threshold(abs2,15,255,cv2.THRESH_BINARY) binary =cv2.bitwise_and(thresh1,thresh2)#与运算 kernel = cv2.getStructuringElement(cv2.MORPH_ELLIPSE,(5,5)) # erode = cv2.erode(binary,kernel)#腐蚀 # dilate =cv2.dilate(binary,kernel)#膨胀 # dilate =cv2.dilate(dilate,kernel)#膨胀 # 轮廓提取 contours, hierarchy = cv2.findContours(binary.copy(),mode=cv2.RETR_EXTERNAL,method=cv2.CHAIN_APPROX_SIMPLE)#寻找轮廓 for contour in contours: if cv2.contourArea(contour)>area_threh: x,y,w,h =cv2.boundingRect(contour)#找方框 cv2.rectangle(frame,(x,y),(x+w,y+h),(0,255,0), 2) img_show = np.hstack((frame,cv2.cvtColor(binary,cv2.COLOR_GRAY2BGR))) cv2.imshow('three frame diff',img_show) if cv2.waitKey(50)&0xFF==ord("q"): break cap.release() cv2.destroyAllWindows()实现效果不进行形态学处理膨胀一次膨胀两次先腐蚀一次,再膨胀两次算法分析优点实现简单,运行速度快解决了帧差法存在的“鬼影”问题能大致检测出物体的运动区域缺点不进行膨胀会存在“空洞”问题进行膨胀之后会存在着多个物体的”牵连“问题对物体的运动区域的检测不够全面eg:对于部分人运动区域的检测会存在着只检测出半个人的情况参考资料python+opencv实现移动侦测(帧差法):https://www.jb51.net/article/183203.htmopencv python 三帧差法实现运动目标区域检测与完整代码:https://blog.csdn.net/pengpengloveqiaoqiao/article/details/89487049 -
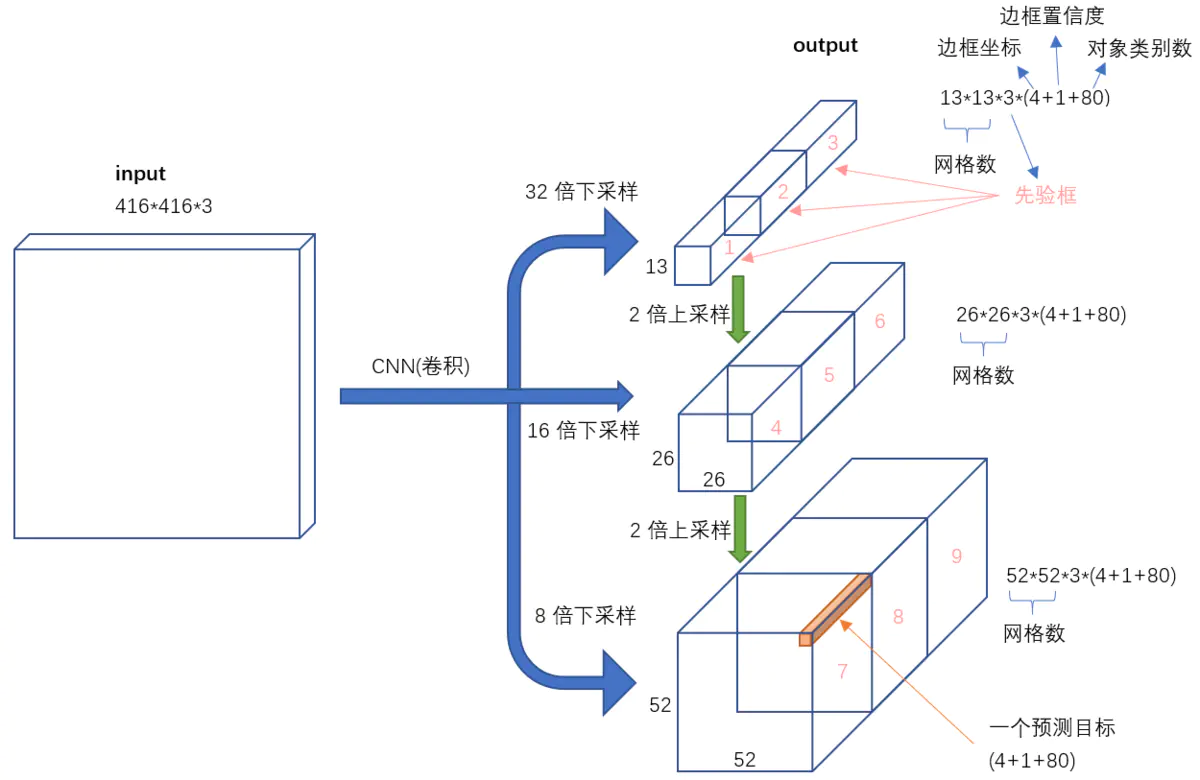
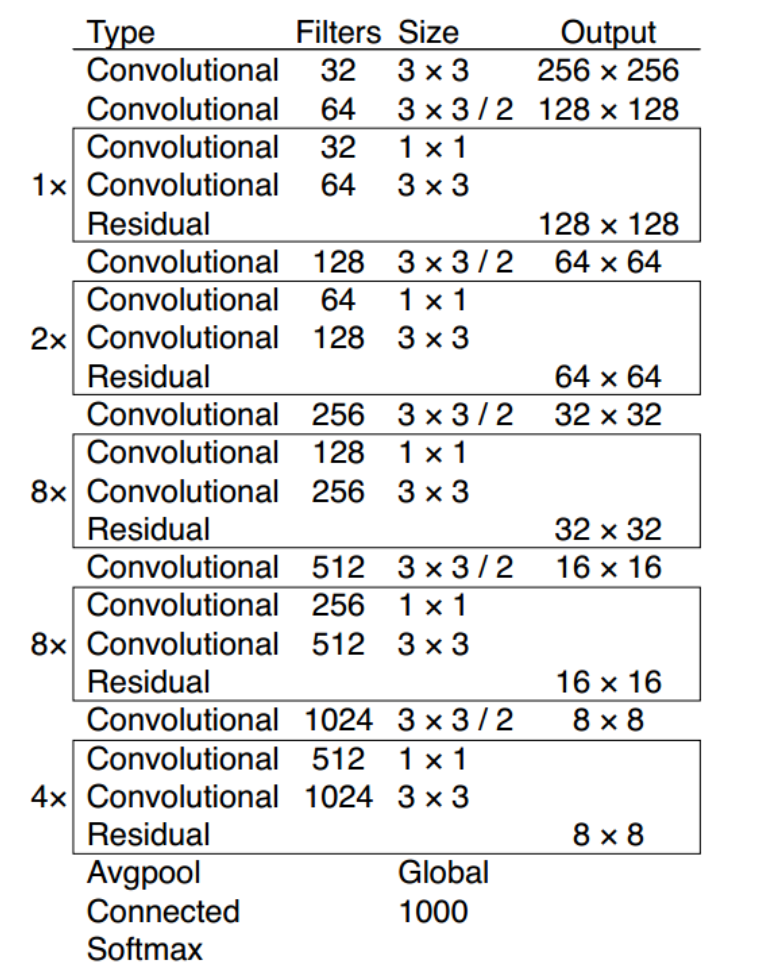
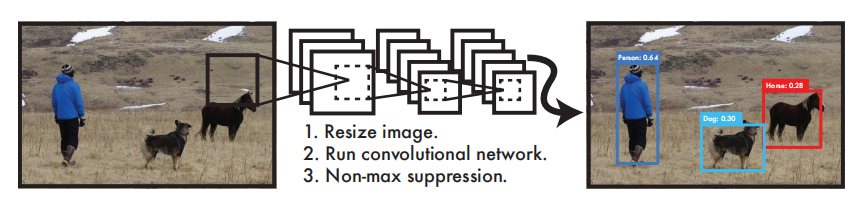
快速调用Yolov5模型检检测图片 前提:未修改模型结构1.快速调用官方的Yolov5预模型import torch # 使用torch.hub加载yolov5的预训练模型训练 model = torch.hub.load('ultralytics/yolov5', 'yolov5s') # or yolov5m, yolov5x, custom # 进行模型调用测试 img_path = './6800.jpg' # or file, PIL, OpenCV, numpy, multiple results = model(img_path) # 得到预测结果 print(results.xyxy) # 输出预测出的bbox_list results.show() # 预测结果展示2.快速调用自己训练好的的Yolov5预模型(有pt文件即可)import torch # 使用torch.hub加载yolov5的预训练模型训练 model = torch.hub.load('ultralytics/yolov5', 'yolov5s') # or yolov5m, yolov5x, custom # 加载自己训练好的模型及相关参数 cpkt = torch.load("./best.pt",map_location=torch.device("cuda:0")) # 将预训练的模型的骨干替换成自己训练好的 yolov5_load = model yolov5_load.model = cpkt["model"] # 进行模型调用测试 img_path = './6800.jpg' # or file, PIL, OpenCV, numpy, multiple results = yolov5_load(img_path) # 得到预测结果 print(results.xyxy) # 输出预测出的bbox_list results.show() # 预测结果展示参考资料https://github.com/ultralytics/yolov5
-
YOLOv5项目目录结构 YOLOv5项目目录结构| detect.py #检测脚本 | hubconf.py #PyTorch Hub相关代码 | LICENSE #版权文件 | README.md #README markdown文件 | requirements.txt #项目所需的安装包列表 | sotabench.py #COCO数据集测试脚本 | test.py #模型测试脚本 | train.py #模型训练脚本 | tutorial.ipynb #Jupyter Notebook演示代码 |---data | | coco.yaml #COCO数据集配置文件 | | coco128.yaml #COCO128数据集配置文件 | | hyp.finetune.yaml #超参数微调配置文件 | | hyp.scratch.yaml #超参数起始配置文件 | | voc.yaml #VOC数据集配置文件 | |---scripts | | | get_coco.sh #下载COCO数据集shell命令 | | | get_voc.sh #下载VOC数据集shell命令 |---inference | |---images #示例图片文件夹 | | | bus.jpg | | | zidane.jpg |---models | | common.py #模型组件定义代码 | | experimental.py #实验性质的代码 | | export.py #模型导出脚本 | | yolo.py #Detect及Model构建代码 | | yolov5l.yaml #yolov51网络模型配置文件 | | yolov5m.yaml #yolov5m网络模型配置文件 | | yolov5s.yaml #yolov5s网络模型配置文件 | | yolov5x.yaml #yolov5x网络模型配置文件 | | __init__.py | |---hub | | | yolov3-spp.yaml | | | yolov5-fpn.yaml | | | yolov5-panet.yaml |---runs #训练结果 | |---exp0 | | | events.out.tfevents.1604835533.PC-201807230204.26148.0 | | | hyp.yaml | | | labels.png | | | opt.yaml | | | orecision-recall_curve.png | | | results.png | | | results.txt | | | test_batch0_gt.jpg | | | test_batch0_pred.jpg | | | train_batch0.jpg | | | train_batch1.jpg | | | train_batch2.jpg | | |---weights | | | | best.pt #最好权重 | | | | last.pt #最近权重 |---utils | | activations.py #激活函数定义代码 | | datasets.py #Dataset及Dataloader定义代码 | | evolve.sh #超参数进化命令 | | general.py #项目通用函数代码 | | google_utils.py #谷歌云使用相关代码 | | torch_utils.py #辅助程序代码 | | __init_.py | |---google_app_engine | | | additional_requirements.txt | | | app.yaml | | | Dockerfile |---VOC #数据集目录 | |---images #数据集图片目录 | | |---train #训练集图片文件夹 | | | | 1000005.jpg | | | | 000007.jpg | | | | 000009.jpg | | | | 000012.jpg | | | | 000016.jpg | | | | ...... | | |---val #验证集图片文件夹 | | | | 000001.jpg | | | | 000002.jpg | | | | 000003.jpg | | | | 000004.jpg | | | | 000006.jpg | | | | ...... | |---labels #数据集标签目录 | | | train.cache | | | val.cache | | |---train #训练集标签文件夹 | | | | 000005.txt | | | | 000007.txt | | | | 000009.txt | | | | 000012.txt | | | | 000016.txt | | | | ...... | | |---val #测试集标签文件夹 | | | | 000001.txt | | | | 000002.txt | | | | 000003.txt | | | | 000004.txt | | | | 000006.txt | | | | ...... |---weights | | download weights.sh #下载权重文件命令 | | yolov5l.pt #yolov5l权重文件 | | yolov5m.pt #yolov5m权重文件 | | yolov5s.mlmodel #yolov5s权重文件(Core ML格式) | | yolov5s.onnx #yolov5s权重文件(onnx格式) | | yolov5s.pt #yolov5s权重文件 | | yolov5s.torchscript.pt #yolov5s权重文件(torchscript格式) | | yolov5x.pt #yolov5x权重文件参考资料1.https://www.bilibili.com/video/BV19K4y197u8?p=14
-
Scene Text Detection Resources(场景文字识别资源汇总) [转载] [翻译] 1. 数据集1.1 水平文字数据集ICDAR 2003(IC03):Introduction: 它总共包含509张图像,258张用于训练和251张用于测试。 具体来说,它在训练集中包含1110个文本实例,而在测试集中包含1156个文本实例。 它具有单词级注释。 IC03仅考虑英文文本实例。Link: IC03-downloadICDAR 2011(IC11):Introduction: IC11是用于文本检测的英语数据集。 它包含484张图像,229张用于训练和255张用于测试。 该数据集中有1564个文本实例。 它提供单词级和字符级注释。Link:11-downloadICDAR 2013(IC13):Introduction: IC13与IC11几乎相同。 它总共包含462张图像,用于训练的229张图像和用于测试的233张图像。 具体来说,它在训练集中包含849个文本实例,而在测试集中包含1095个文本实例。Link: IC13-download1.2 任意四边形文本数据集USTB-SV1K:Introduction:USTB-SV1K是英语数据集。 它包含来自Google街景视图的1000张街道图像,总共2955个文本实例。 它仅提供单词级注释。Link: USTB-SV1K-downloadSVT:Introduction:它包含350张图像,总共725个英文文本实例。 SVT具有字符级别和单词级别的注释。 DVT的图像是从Google街景视图中获取的,分辨率较低。Link: SVT-downloadSVT-P:Introduction: 它包含639个裁剪的单词图像以进行测试。 从Google街景视图的侧面快照中选择了图像。 因此,大多数图像会因非正面视角而严重失真。 它是SVT的改进数据集。Link: SVT-P-download (Password : vnis)ICDAR 2015(IC15):Introduction: 它总共包含1500张图像,1000张用于训练和500张用于测试。 具体来说,它包含17548个文本实例。 它提供单词级别的注释。 IC15是第一个附带场景文本数据集,并且仅考虑英语单词。Link: IC15-downloadCOCO-Text:Introduction: 它总共包含63686张图像,用于训练的43686张图像,用于验证的10000张图像和用于测试的10000张图像。 具体来说,它包含145859个裁剪的单词图像以进行测试,包括手写和打印,清晰和模糊,英语和非英语。Link: COCO-Text-downloadMSRA-TD500:Introduction: 它总共包含500张图像。 它提供文本行级别的注释而不是单词,并提供多边形框而不是轴对齐的矩形来进行文本区域注释。 它包含英文和中文文本实例。Link: MSRA-TD500-downloadMLT 2017:Introduction:它总共包含10000个自然图像。 它提供单词级别的注释。 MLT有9种语言。 它是用于场景文本检测和识别的更真实和复杂的数据集。Link: MLT-downloadMLT 2019:Introduction: 它总共包含18000张图像。 它提供单词级别的注释。 与MLT相比,此数据集有10种语言。 它是用于场景文本检测和识别的更真实和复杂的数据集。Link: MLT-2019-downloadCTW:Introduction:它包含32285个中文文本的高分辨率街景图像,总共包含1018402个字符实例。 所有图像都在字符级别进行注释,包括其基础字符类型,绑定框和其他6个属性。 这些属性指示其背景是否复杂,是否凸起,是否为手写或印刷,是否被遮挡,是否扭曲,是否使用艺术字。Link: CTW-downloadRCTW-17:Introduction:它总共包含12514张图像,用于训练的11514张图像和用于测试的1000张图像。 RCTW-17中的图像大部分是通过照相机或手机收集的,其他则是生成的图像。 文本实例用平行四边形注释。 它是第一个大规模的中文数据集,也是当时发布的最大的数据集。Link: RCTW-17-downloadReCTS:Introduction:该数据集是大规模的中国街景商标数据集。 它基于中文单词和中文文本行级标签。 标记方法是任意四边形标记。 它总共包含20000张图像。Link: ReCTS-download1.3 不规则文本数据集CUTE80:Introduction: 它包含在自然场景中拍摄的80张高分辨率图像。 具体来说,它包含288个裁剪的单词图像以进行测试。 数据集集中在弯曲的文本上。 没有提供词典。Link: CUTE80-downloadTotal-Text:Introduction: 它总共包含1,555张图像。 具体来说,它包含11459个经裁剪的单词图像,这些图像具有三种以上不同的文本方向:水平,多方向和弯曲。Link: Total-Text-downloadSCUT-CTW1500:Introduction: 它总共包含1500张图像,1000张用于训练和500张用于测试。 具体来说,它包含10751个裁剪的单词图像以进行测试。 CTW-1500中的注释是具有14个顶点的多边形。 数据集主要由中文和英文组成。Link: CTW-1500-downloadLSVT:Introduction: LSVT由20,000个测试数据,30,000个完整注释的训练数据和400,000个弱注释的训练数据组成,这些数据称为部分标签。 带标签的文本区域展示了文本的多样性:水平,多向和弯曲。Link: LSVT-downloadArTs:Introduction: ArT包含10,166张图像,5,603张用于训练和4,563张用于测试。 收集它们时会考虑到文本形状的多样性,并且所有文本形状在ArT中都有大量存在。Link: ArT-download1.4 合成数据集Synth80k :Introduction:它包含80万幅图像,其中包含约800万个合成词实例。 每个文本实例都用其文本字符串,单词级和字符级的边界框进行注释。Link: Synth80k-downloadSynthText :Introduction:它包含600万个裁剪的单词图像。 生成过程与Synth90k相似。 它也以水平样式进行注释。Link: SynthText-download1.5 数据集对比 Comparison of Datasets Datasets Language Image Text instance Text Shape Annotation level Total Train Test Total Train Test Horizontal Arbitrary-Quadrilateral Multi-oriented Char Word Text-Line IC03 English 509 258 251 2266 1110 1156 ✓ ✕ ✕ ✕ ✓ ✕ IC11 English 484 229 255 1564 ~ ~ ✓ ✕ ✕ ✓ ✓ ✕ IC13 English 462 229 233 1944 849 1095 ✓ ✕ ✕ ✓ ✓ ✕ USTB-SV1K English 1000 500 500 2955 ~ ~ ✓ ✓ ✕ ✕ ✓ ✕ SVT English 350 100 250 725 211 514 ✓ ✓ ✕ ✓ ✓ ✕ SVT-P English 238 ~ ~ 639 ~ ~ ✓ ✓ ✕ ✕ ✓ ✕ IC15 English 1500 1000 500 17548 122318 5230 ✓ ✓ ✕ ✕ ✓ ✕ COCO-Text English 63686 43686 20000 145859 118309 27550 ✓ ✓ ✕ ✕ ✓ ✕ MSRA-TD500 English/Chinese 500 300 200 ~ ~ ~ ✓ ✓ ✕ ✕ ✕ ✓ MLT 2017 Multi-lingual 18000 7200 10800 ~ ~ ~ ✓ ✓ ✕ ✕ ✓ ✕ MLT 2019 Multi-lingual 20000 10000 10000 ~ ~ ~ ✓ ✓ ✕ ✕ ✓ ✕ CTW Chinese 32285 25887 6398 1018402 812872 205530 ✓ ✓ ✕ ✓ ✓ ✕ RCTW-17 English/Chinese 12514 15114 1000 ~ ~ ~ ✓ ✓ ✕ ✕ ✕ ✓ ReCTS Chinese 20000 ~ ~ ~ ~ ~ ✓ ✓ ✕ ✓ ✓ ✕ CUTE80 English 80 ~ ~ ~ ~ ~ ✕ ✕ ✓ ✕ ✓ ✓ Total-Text English 1525 1225 300 9330 ~ ~ ✓ ✓ ✓ ✕ ✓ ✓ CTW-1500 English/Chinese 1500 1000 500 10751 ~ ~ ✓ ✓ ✓ ✕ ✓ ✓ LSVT English/Chinese 450000 430000 20000 ~ ~ ~ ✓ ✓ ✓ ✕ ✓ ✓ ArT English/Chinese 10166 5603 4563 ~ ~ ~ ✓ ✓ ✓ ✕ ✓ ✕ Synth80k English 80k ~ ~ 8m ~ ~ ✓ ✕ ✕ ✓ ✓ ✕ SynthText English 800k ~ ~ 6m ~ ~ ✓ ✓ ✕ ✕ ✓ ✕ 2. 场景文本检测资源总结2.1 方法对比场景文本检测方法可以分为四个部分:(a) 传统方法; (b) 基于分割的方法;(c) 基于回归的方法;(d) 混合方法.注意:(1)“ Hori”代表水平场景文本数据集。 (2)“ Quad”代表任意四边形文本数据集。(3)“ Irreg”代表不规则场景文本数据集。 (4)“传统方法”代表不依赖深度学习的方法。2.1.1 传统方法 Method Model Code Hori Quad Irreg Source Time Highlight Yao et al. [1] TD-Mixture ✕ ✓ ✓ ✕ CVPR 2012 1) A new dataset MSRA-TD500 and protocol for evaluation. 2) Equipped a two-level classification scheme and two sets of features extractor. Yin et al. [2] ✕ ✓ ✕ ✕ TPAMI 2013 Extract Maximally Stable Extremal Regions (MSERs) as character candidates and group them together. Le et al. [5] HOCC ✕ ✓ ✓ ✕ CVPR 2014 HOCC + MSERs Yin et al. [7] ✕ ✓ ✓ ✕ TPAMI 2015 Presenting a unified distance metric learning framework for adaptive hierarchical clustering. Wu et al. [9] ✕ ✓ ✓ ✕ TMM 2015 Exploring gradient directional symmetry at component level for smoothing edge components before text detection. Tian et al. [17] ✕ ✓ ✕ ✕ IJCAI 2016 Scene text is first detected locally in individual frames and finally linked by an optimal tracking trajectory. Yang et al. [33] ✕ ✓ ✓ ✕ TIP 2017 A text detector will locate character candidates and extract text regions. Then they will linked by an optimal tracking trajectory. Liang et al. [8] ✕ ✓ ✓ ✓ TIP 2015 Exploring maxima stable extreme regions along with stroke width transform for detecting candidate text regions. Michal et al.[12] FASText ✕ ✓ ✓ ✕ ICCV 2015 Stroke keypoints are efficiently detected and then exploited to obtain stroke segmentations. 2.1.2基于分割的方法 Method Model Code Hori Quad Irreg Source Time Highlight Li et al. [3] ✕ ✓ ✓ ✕ TIP 2014 (1)develop three novel cues that are tailored for character detection and a Bayesian method for their integration; (2)design a Markov random field model to exploit the inherent dependencies between characters. Zhang et al. [14] ✕ ✓ ✓ ✕ CVPR 2016 Utilizing FCN for salient map detection and centroid of each character prediction. Zhu et al. [16] ✕ ✓ ✓ ✕ CVPR 2016 Performs a graph-based segmentation of connected components into words (Word-Graph). He et al. [18] Text-CNN ✕ ✓ ✓ ✕ TIP 2016 Developing a new learning mechanism to train the Text-CNN with multi-level and rich supervised information. Yao et al. [21] ✕ ✓ ✓ ✕ arXiv 2016 Proposing to localize text in a holistic manner, by casting scene text detection as a semantic segmentation problem. Hu et al. [27] WordSup ✕ ✓ ✓ ✕ ICCV 2017 Proposing a weakly supervised framework that can utilize word annotations. Then the detected characters are fed to a text structure analysis module. Wu et al. [28] ✕ ✓ ✓ ✕ ICCV 2017 Introducing the border class to the text detection problem for the first time, and validate that the decoding process is largely simplified with the help of text border. Tang et al.[32] ✕ ✓ ✕ ✕ TIP 2017 A text-aware candidate text region(CTR) extraction model + CTR refinement model. Dai et al. [35] FTSN ✕ ✓ ✓ ✕ arXiv 2017 Detecting and segmenting the text instance jointly and simultaneously, leveraging merits from both semantic segmentation task and region proposal based object detection task. Wang et al. [38] ✕ ✓ ✕ ✕ ICDAR 2017 This paper proposes a novel character candidate extraction method based on super-pixel segmentation and hierarchical clustering. Deng et al. [40] PixelLink ✓ ✓ ✓ ✕ AAAI 2018 Text instances are first segmented out by linking pixels wthin the same instance together. Liu et al. [42] MCN ✕ ✓ ✓ ✕ CVPR 2018 Stochastic Flow Graph (SFG) + Markov Clustering. Lyu et al. [43] ✕ ✓ ✓ ✕ CVPR 2018 Detect scene text by localizing corner points of text bounding boxes and segmenting text regions in relative positions. Chu et al. [45] Border ✕ ✓ ✓ ✕ ECCV 2018 The paper presents a novel scene text detection technique that makes use of semantics-aware text borders and bootstrapping based text segment augmentation. Long et al. [46] TextSnake ✕ ✓ ✓ ✓ ECCV 2018 The paper proposes TextSnake, which is able to effectively represent text instances in horizontal, oriented and curved forms based on symmetry axis. Yang et al. [47] IncepText ✕ ✓ ✓ ✕ IJCAI 2018 Designing a novel Inception-Text module and introduce deformable PSROI pooling to deal with multi-oriented text detection. Yue et al. [48] ✕ ✓ ✓ ✕ BMVC 2018 Proposing a general framework for text detection called Guided CNN to achieve the two goals simultaneously. Zhong et al. [53] AF-RPN ✕ ✓ ✓ ✕ arXiv 2018 Presenting AF-RPN(anchor-free) as an anchor-free and scale-friendly region proposal network for the Faster R-CNN framework. Wang et al. [54] PSENet ✓ ✓ ✓ ✓ CVPR 2019 Proposing a novel Progressive Scale Expansion Network (PSENet), designed as a segmentation-based detector with multiple predictions for each text instance. Xu et al.[57] TextField ✕ ✓ ✓ ✓ arXiv 2018 Presenting a novel direction field which can represent scene texts of arbitrary shapes. Tian et al. [58] FTDN ✕ ✓ ✓ ✕ ICIP 2018 FTDN is able to segment text region and simultaneously regress text box at pixel-level. Tian et al. [83] ✕ ✓ ✓ ✓ CVPR 2019 Constraining embedding feature of pixels inside the same text region to share similar properties. Huang et al. [4] MSERs-CNN ✕ ✓ ✕ ✕ ECCV 2014 Combining MSERs with CNN Sun et al. [6] ✕ ✓ ✕ ✕ PR 2015 Presenting a robust text detection approach based on color-enhanced CER and neural networks. Baek et al. [62] CRAFT ✕ ✓ ✓ ✓ CVPR 2019 Proposing CRAFT effectively detect text area by exploring each character and affinity between characters. Richardson et al. [87] ✕ ✓ ✓ ✕ WACV 2019 Presenting an additional scale predictor the estimate the better scale of text regions for testing. Wang et al. [88] SAST ✕ ✓ ✓ ✓ ACMM 2019 Presenting a context attended multi-task learning framework for scene text detection. Wang et al. [90] PAN ✕ ✓ ✓ ✓ ICCV 2019 Proposing an efficient and accurate arbitrary-shaped text detector called Pixel Aggregation Network(PAN), 2.1.3 基于回归的方法 Method Model Code Hori Quad Irreg Source Time Highlight Gupta et al. [15] FCRN ✓ ✓ ✕ ✕ CVPR 2016 (a) Proposing a fast and scalable engine to generate synthetic images of text in clutter; (b) FCRN. Zhong et al. [20] DeepText ✕ ✓ ✕ ✕ arXiv 2016 (a) Inception-RPN; (b) Utilize ambiguous text category (ATC) information and multilevel region-of-interest pooling (MLRP). Liao et al. [22] TextBoxes ✓ ✓ ✕ ✕ AAAI 2017 Mainly basing SSD object detection framework. Liu et al. [25] DMPNet ✕ ✓ ✓ ✕ CVPR 2017 Quadrilateral sliding windows + shared Monte-Carlo method for fast and accurate computing of the polygonal areas + a sequential protocol for relative regression. He et al. [26] DDR ✕ ✓ ✓ ✕ ICCV 2017 Proposing an FCN that has bi-task outputs where one is pixel-wise classification between text and non-text, and the other is direct regression to determine the vertex coordinates of quadrilateral text boundaries. Jiang et al. [36] R2CNN ✕ ✓ ✓ ✕ arXiv 2017 Using the Region Proposal Network (RPN) to generate axis-aligned bounding boxes that enclose the texts with different orientations. Xing et al. [37] ArbiText ✕ ✓ ✓ ✕ arXiv 2017 Adopting the circle anchors and incorporating a pyramid pooling module into the Single Shot MultiBox Detector framework. Zhang et al. [39] FEN ✕ ✓ ✕ ✕ AAAI 2018 Proposing a refined scene text detector with a novel Feature Enhancement Network (FEN) for Region Proposal and Text Detection Refinement. Wang et al. [41] ITN ✕ ✓ ✓ ✕ CVPR 2018 ITN is presented to learn the geometry-aware representation encoding the unique geometric configurations of scene text instances with in-network transformation embedding. Liao et al. [44] RRD ✕ ✓ ✓ ✕ CVPR 2018 The regression branch extracts rotation-sensitive features, while the classification branch extracts rotation-invariant features by pooling the rotation sensitive features. Liao et al. [49] TextBoxes++ ✓ ✓ ✓ ✕ TIP 2018 Mainly basing SSD object detection framework and it replaces the rectangular box representation in conventional object detector by a quadrilateral or oriented rectangle representation. He et al. [50] ✕ ✓ ✓ ✕ TIP 2018 Proposing a scene text detection framework based on fully convolutional network with a bi-task prediction module. Ma et al. [51] RRPN ✓ ✓ ✓ ✕ TMM 2018 RRPN + RRoI Pooling. Zhu et al. [55] SLPR ✕ ✓ ✓ ✓ arXiv 2018 SLPR regresses multiple points on the edge of text line and then utilizes these points to sketch the outlines of the text. Deng et al. [56] ✓ ✓ ✓ ✕ arXiv 2018 CRPN employs corners to estimate the possible locations of text instances. And it also designs a embedded data augmentation module inside region-wise subnetwork. Cai et al. [59] FFN ✕ ✓ ✕ ✕ ICIP 2018 Proposing a Feature Fusion Network to deal with text regions differing in enormous sizes. Sabyasachi et al. [60] RGC ✕ ✓ ✓ ✕ ICIP 2018 Proposing a novel recurrent architecture to improve the learnings of a feature map at a given time. Liu et al. [63] CTD ✓ ✓ ✓ ✓ PR 2019 CTD + TLOC + PNMS Xie et al. [79] DeRPN ✓ ✓ ✕ ✕ AAAI 2019 DeRPN utilizes anchor string mechanism instead of anchor box in RPN. Wang et al. [82] ✕ ✓ ✓ ✓ CVPR 2019 Text-RPN + RNN Liu et al. [84] ✕ ✓ ✓ ✓ CVPR 2019 CSE mechanism He et al. [29] SSTD ✓ ✓ ✓ ✕ ICCV 2017 Proposing an attention mechanism. Then developing a hierarchical inception module which efficiently aggregates multi-scale inception features. Tian et al. [11] ✕ ✓ ✕ ✕ ICCV 2015 Cascade boosting detects character candidates, and the min-cost flow network model get the final result. Tian et al. [13] CTPN ✓ ✓ ✕ ✕ ECCV 2016 1) RPN + LSTM. 2) RPN incorporate a new vertical anchor mechanism and LSTM connects the region to get the final result. He et al. [19] ✕ ✓ ✓ ✕ ACCV 2016 ER detetctor detects regions to get coarse prediction of text regions. Then the local context is aggregated to classify the remaining regions to obtain a final prediction. Shi et al. [23] SegLink ✓ ✓ ✓ ✕ CVPR 2017 Decomposing text into segments and links. A link connects two adjacent segments. Tian et al. [30] WeText ✕ ✓ ✕ ✕ ICCV 2017 Proposing a weakly supervised scene text detection method (WeText). Zhu et al. [31] RTN ✕ ✓ ✕ ✕ ICDAR 2017 Mainly basing CTPN vertical vertical proposal mechanism. Ren et al. [34] ✕ ✓ ✕ ✕ TMM 2017 Proposing a CNN-based detector. It contains a text structure component detector layer, a spatial pyramid layer, and a multi-input-layer deep belief network (DBN). Zhang et al. [10] ✕ ✓ ✕ ✕ CVPR 2015 The proposed algorithm exploits the symmetry property of character groups and allows for direct extraction of text lines from natural images. Wang et al. [86] DSRN ✕ ✓ ✓ ✕ IJCAI 2019 Presenting a scale-transfer module and scale relationship module to handle the problem of scale variation. Tang et al.[89] Seglink++ ✕ ✓ ✓ ✓ PR 2019 Presenting instance aware component grouping (ICG) for arbitrary-shape text detection. Wang et al.[92] ContourNet ✓ ✓ ✓ ✓ CVPR 2020 1.A scale-insensitive Adaptive Region Proposal Network (AdaptiveRPN); 2. Local Orthogonal Texture-aware Module (LOTM). 2.1.4 混合方法 Method Model Code Hori Quad Irreg Source Time Highlight Tang et al. [52] SSFT ✕ ✓ ✕ ✕ TMM 2018 Proposing a novel scene text detection method that involves superpixel-based stroke feature transform (SSFT) and deep learning based region classification (DLRC). Xie et al.[61] SPCNet ✕ ✓ ✓ ✓ AAAI 2019 Text Context module + Re-Score mechanism. Liu et al. [64] PMTD ✓ ✓ ✓ ✕ arXiv 2019 Perform “soft” semantic segmentation. It assigns a soft pyramid label (i.e., a real value between 0 and 1) for each pixel within text instance. Liu et al. [80] BDN ✓ ✓ ✓ ✕ IJCAI 2019 Discretizing bouding boxes into key edges to address label confusion for text detection. Zhang et al. [81] LOMO ✕ ✓ ✓ ✓ CVPR 2019 DR + IRM + SEM Zhou et al. [24] EAST ✓ ✓ ✓ ✕ CVPR 2017 The pipeline directly predicts words or text lines of arbitrary orientations and quadrilateral shapes in full images with instance segmentation. Yue et al. [48] ✕ ✓ ✓ ✕ BMVC 2018 Proposing a general framework for text detection called Guided CNN to achieve the two goals simultaneously. Zhong et al. [53] AF-RPN ✕ ✓ ✓ ✕ arXiv 2018 Presenting AF-RPN(anchor-free) as an anchor-free and scale-friendly region proposal network for the Faster R-CNN framework. Xue et al.[85] MSR ✕ ✓ ✓ ✓ IJCAI 2019 Presenting a noval multi-scale regression network. Liao et al. [91] DB ✓ ✓ ✓ ✓ AAAI 2020 Presenting differentiable binarization module to adaptively set the thresholds for binarization, which simplifies the post-processing. Xiao et al. [93] SDM ✕ ✓ ✓ ✓ ECCV 2020 1. A novel sequential deformation method; 2. auxiliary character counting supervision. 2.2 检测结果2.2.1 水平文本数据集的检测结果 Method Model Source Time Method Category IC11[68] IC13 [69] IC05[67] P R F P R F P R F Yao et al. [1] TD-Mixture CVPR 2012 Traditional ~ ~ ~ 0.69 0.66 0.67 ~ ~ ~ Yin et al. [2] TPAMI 2013 0.86 0.68 0.76 ~ ~ ~ ~ ~ ~ Yin et al. [7] TPAMI 2015 0.838 0.66 0.738 ~ ~ ~ ~ ~ ~ Wu et al. [9] TMM 2015 ~ ~ ~ 0.76 0.70 0.73 ~ ~ ~ Liang et al. [8] TIP 2015 0.77 0.68 0.71 0.76 0.68 0.72 ~ ~ ~ Michal et al.[12] FASText ICCV 2015 ~ ~ ~ 0.84 0.69 0.77 ~ ~ ~ Li et al. [3] TIP 2014 Segmentation 0.80 0.62 0.70 ~ ~ ~ ~ ~ ~ Zhang et al. [14] CVPR 2016 ~ ~ ~ 0.88 0.78 0.83 ~ ~ ~ He et al. [18] Text-CNN TIP 2016 0.91 0.74 0.82 0.93 0.73 0.82 0.87 0.73 0.79 Yao et al. [21] arXiv 2016 ~ ~ ~ 0.889 0.802 0.843 ~ ~ ~ Hu et al. [27] WordSup ICCV 2017 ~ ~ ~ 0.933 0.875 0.903 ~ ~ ~ Tang et al.[32] TIP 2017 0.90 0.86 0.88 0.92 0.87 0.89 ~ ~ ~ Wang et al. [38] ICDAR 2017 0.87 0.78 0.82 0.87 0.82 0.84 ~ ~ ~ Deng et al. [40] PixelLink AAAI 2018 ~ ~ ~ 0.886 0.875 0.881 ~ ~ ~ Liu et al. [42] MCN CVPR 2018 ~ ~ ~ 0.88 0.87 0.88 ~ ~ ~ Lyu et al. [43] CVPR 2018 ~ ~ ~ 0.92 0.844 0.880 ~ ~ ~ Chu et al. [45] Border ECCV 2018 ~ ~ ~ 0.915 0.871 0.892 ~ ~ ~ Wang et al. [54] PSENet CVPR 2019 ~ ~ ~ 0.94 0.90 0.92 ~ ~ ~ Huang et al. [4] MSERs-CNN ECCV 2014 0.88 0.71 0.78 ~ ~ ~ 0.84 0.67 0.75 Sun et al. [6] PR 2015 0.92 0.91 0.91 0.94 0.92 0.93 ~ ~ ~ Gupta et al. [15] FCRN CVPR 2016 Regression 0.94 0.77 0.85 0.938 0.764 0.842 ~ ~ ~ Zhong et al. [20] DeepText arXiv 2016 0.87 0.83 0.85 0.85 0.81 0.83 ~ ~ ~ Liao et al. [22] TextBoxes AAAI 2017 0.89 0.82 0.86 0.89 0.83 0.86 ~ ~ ~ Liu et al. [25] DMPNet CVPR 2017 ~ ~ ~ 0.93 0.83 0.870 ~ ~ ~ Jiang et al. [36] R2CNN arXiv 2017 ~ ~ ~ 0.92 0.81 0.86 ~ ~ ~ Xing et al. [37] ArbiText arXiv 2017 ~ ~ ~ 0.826 0.936 0.877 ~ ~ ~ Wang et al. [41] ITN CVPR 2018 0.896 0.889 0.892 0.941 0.893 0.916 ~ ~ ~ Liao et al. [49] TextBoxes++ TIP 2018 ~ ~ ~ 0.92 0.86 0.89 ~ ~ ~ He et al. [50] TIP 2018 ~ ~ ~ 0.91 0.84 0.88 ~ ~ ~ Ma et al. [51] RRPN TMM 2018 ~ ~ ~ 0.95 0.89 0.91 ~ ~ ~ Zhu et al. [55] SLPR arXiv 2018 ~ ~ ~ 0.90 0.72 0.80 ~ ~ ~ Cai et al. [59] FFN ICIP 2018 ~ ~ ~ 0.92 0.84 0.876 ~ ~ ~ Sabyasachi et al. [60] RGC ICIP 2018 ~ ~ ~ 0.89 0.77 0.83 ~ ~ ~ Wang et al. [82] CVPR 2019 ~ ~ ~ 0.937 0.878 0.907 ~ ~ ~ Liu et al. [84] CVPR 2019 ~ ~ ~ 0.937 0.897 0.917 ~ ~ ~ He et al. [29] SSTD ICCV 2017 ~ ~ ~ 0.89 0.86 0.88 ~ ~ ~ Tian et al. [11] ICCV 2015 0.86 0.76 0.81 0.852 0.759 0.802 ~ ~ ~ Tian et al. [13] CTPN ECCV 2016 ~ ~ ~ 0.93 0.83 0.88 ~ ~ ~ He et al. [19] ACCV 2016 ~ ~ ~ 0.90 0.75 0.81 ~ ~ ~ Shi et al. [23] SegLink CVPR 2017 ~ ~ ~ 0.877 0.83 0.853 ~ ~ ~ Tian et al. [30] WeText ICCV 2017 ~ ~ ~ 0.911 0.831 0.869 ~ ~ ~ Zhu et al. [31] RTN ICDAR 2017 ~ ~ ~ 0.94 0.89 0.91 ~ ~ ~ Ren et al. [34] TMM 2017 0.78 0.67 0.72 0.81 0.67 0.73 ~ ~ ~ Zhang et al. [10] CVPR 2015 0.84 0.76 0.80 0.88 0.74 0.80 ~ ~ ~ Tang et al. [52] SSFT TMM 2018 Hybrid 0.906 0.847 0.876 0.911 0.861 0.885 ~ ~ ~ Xie et al.[61] SPCNet AAAI 2019 ~ ~ ~ 0.94 0.91 0.92 ~ ~ ~ Liu et al. [80] BDN IJCAI 2019 ~ ~ ~ 0.887 0.894 0.89 ~ ~ ~ Zhou et al. [24] EAST CVPR 2017 ~ ~ ~ 0.93 0.83 0.870 ~ ~ ~ Yue et al. [48] BMVC 2018 ~ ~ ~ 0.885 0.846 0.870 ~ ~ ~ Zhong et al. [53] AF-RPN arXiv 2018 ~ ~ ~ 0.94 0.90 0.92 ~ ~ ~ Xue et al.[85] MSR IJCAI 2019 ~ ~ ~ 0.918 0.885 0.901 ~ ~ ~ 2.2.2 任意四边形文本数据集的检测结果 Method Model Source Time Method Category IC15 [70] MSRA-TD500 [71] USTB-SV1K [65] SVT [66] P R F P R F P R F P R F Le et al. [5] HOCC CVPR 2014 Traditional ~ ~ ~ 0.71 0.62 0.66 ~ ~ ~ ~ ~ ~ Yin et al. [7] TPAMI 2015 ~ ~ ~ 0.81 0.63 0.71 0.499 0.454 0.475 ~ ~ ~ Wu et al. [9] TMM 2015 ~ ~ ~ 0.63 0.70 0.66 ~ ~ ~ ~ ~ ~ Tian et al. [17] IJCAI 2016 ~ ~ ~ 0.95 0.58 0.721 0.537 0.488 0.51 ~ ~ ~ Yang et al. [33] TIP 2017 ~ ~ ~ 0.95 0.58 0.72 0.54 0.49 0.51 ~ ~ ~ Liang et al. [8] TIP 2015 ~ ~ ~ 0.74 0.66 0.70 ~ ~ ~ ~ ~ ~ Zhang et al. [14] CVPR 2016 Segmentation 0.71 0.43 0.54 0.83 0.67 0.74 ~ ~ ~ ~ ~ ~ Zhu et al. [16] CVPR 2016 0.81 0.91 0.85 ~ ~ ~ ~ ~ ~ ~ ~ ~ He et al. [18] Text-CNN TIP 2016 ~ ~ ~ 0.76 0.61 0.69 ~ ~ ~ ~ ~ ~ Yao et al. [21] arXiv 2016 0.723 0.587 0.648 0.765 0.753 0.759 ~ ~ ~ ~ ~ ~ Hu et al. [27] WordSup ICCV 2017 0.793 0.77 0.782 ~ ~ ~ ~ ~ ~ ~ ~ ~ Wu et al. [28] ICCV 2017 0.91 0.78 0.84 0.77 0.78 0.77 ~ ~ ~ ~ ~ ~ Dai et al. [35] FTSN arXiv 2017 0.886 0.80 0.841 0.876 0.771 0.82 ~ ~ ~ ~ ~ ~ Deng et al. [40] PixelLink AAAI 2018 0.855 0.820 0.837 0.830 0.732 0.778 ~ ~ ~ ~ ~ ~ Liu et al. [42] MCN CVPR 2018 0.72 0.80 0.76 0.88 0.79 0.83 ~ ~ ~ ~ ~ ~ Lyu et al. [43] CVPR 2018 0.895 0.797 0.843 0.876 0.762 0.815 ~ ~ ~ ~ ~ ~ Chu et al. [45] Border ECCV 2018 ~ ~ ~ 0.830 0.774 0.801 ~ ~ ~ ~ ~ ~ Long et al. [46] TextSnake ECCV 2018 0.849 0.804 0.826 0.832 0.739 0.783 ~ ~ ~ ~ ~ ~ Yang et al. [47] IncepText IJCAI 2018 0.938 0.873 0.905 0.875 0.790 0.830 ~ ~ ~ ~ ~ ~ Wang et al. [54] PSENet CVPR 2019 0.8692 0.845 0.8569 ~ ~ ~ ~ ~ ~ ~ ~ ~ Xu et al.[57] TextField arXiv 2018 0.843 0.805 0.824 0.874 0.759 0.813 ~ ~ ~ ~ ~ ~ Tian et al. [58] FTDN ICIP 2018 0.847 0.773 0.809 ~ ~ ~ ~ ~ ~ ~ ~ ~ Tian et al. [83] CVPR 2019 0.883 0.850 0.866 0.842 0.817 0.829 ~ ~ ~ ~ ~ ~ Baek et al. [62] CRAFT CVPR 2019 0.898 0.843 0.869 0.882 0.782 0.829 ~ ~ ~ ~ ~ ~ Richardson et al. [87] IJCAI 2019 0.853 0.83 0.827 ~ ~ ~ ~ ~ ~ ~ ~ ~ Wang et al. [88] SAST ACMM 2019 0.8755 0.8734 0.8744 ~ ~ ~ ~ ~ ~ ~ ~ ~ Wang et al. [90] PAN ICCV 2019 0.84 0.819 0.829 0.844 0.838 0.821 ~ ~ ~ ~ ~ ~ Gupta et al. [15] FCRN CVPR 2016 Regression ~ ~ ~ ~ ~ ~ ~ ~ ~ 0.651 0.599 0.624 Liu et al. [25] DMPNet CVPR 2017 0.732 0.682 0.706 ~ ~ ~ ~ ~ ~ ~ ~ ~ He et al. [26] DDR ICCV 2017 0.82 0.80 0.81 0.77 0.70 0.74 ~ ~ ~ ~ ~ ~ Jiang et al. [36] R2CNN arXiv 2017 0.856 0.797 0.825 ~ ~ ~ ~ ~ ~ ~ ~ ~ Xing et al. [37] ArbiText arXiv 2017 0.792 0.735 0.759 0.78 0.72 0.75 ~ ~ ~ ~ ~ ~ Wang et al. [41] ITN CVPR 2018 0.857 0.741 0.795 0.903 0.723 0.803 ~ ~ ~ ~ ~ ~ Liao et al. [44] RRD CVPR 2018 0.88 0.8 0.838 0.876 0.73 0.79 ~ ~ ~ ~ ~ ~ Liao et al. [49] TextBoxes++ TIP 2018 0.878 0.785 0.829 ~ ~ ~ ~ ~ ~ ~ ~ ~ He et al. [50] TIP 2018 0.85 0.80 0.82 0.91 0.81 0.86 ~ ~ ~ ~ ~ ~ Ma et al. [51] RRPN TMM 2018 0.822 0.732 0.774 0.821 0.677 0.742 ~ ~ ~ ~ ~ ~ Zhu et al. [55] SLPR arXiv 2018 0.855 0.836 0.845 ~ ~ ~ ~ ~ ~ ~ ~ ~ Deng et al. [56] arXiv 2018 0.89 0.81 0.845 ~ ~ ~ ~ ~ ~ ~ ~ ~ Sabyasachi et al. [60] RGC ICIP 2018 0.83 0.81 0.82 0.85 0.76 0.80 ~ ~ ~ ~ ~ ~ Wang et al. [82] CVPR 2019 0.892 0.86 0.876 0.852 0.821 0.836 ~ ~ ~ ~ ~ ~ He et al. [29] SSTD ICCV 2017 0.80 0.73 0.77 ~ ~ ~ ~ ~ ~ ~ ~ ~ Tian et al. [13] CTPN ECCV 2016 0.74 0.52 0.61 ~ ~ ~ ~ ~ ~ ~ ~ ~ He et al. [19] ACCV 2016 ~ ~ ~ ~ ~ ~ ~ ~ ~ 0.87 0.73 0.79 Shi et al. [23] SegLink CVPR 2017 0.731 0.768 0.75 0.86 0.70 0.77 ~ ~ ~ ~ ~ ~ Wang et al. [86] DSRN IJCAI 2019 0.832 0.796 0.814 0.876 0.712 0.785 ~ ~ ~ ~ ~ ~ Tang et al.[89] Seglink++ PR 2019 0.837 0.803 0.820 ~ ~ ~ ~ ~ ~ ~ ~ ~ Wang et al. [92] ContourNet CVPR 2020 0.876 0.861 0.869 ~ ~ ~ ~ ~ ~ ~ ~ ~ Tang et al. [52] SSFT TMM 2018 Hybrid ~ ~ ~ ~ ~ ~ ~ ~ ~ 0.541 0.758 0.631 Xie et al.[61] SPCNet AAAI 2019 0.89 0.86 0.87 ~ ~ ~ ~ ~ ~ ~ ~ ~ Liu et al. [64] PMTD arXiv 2019 0.913 0.874 0.893 ~ ~ ~ ~ ~ ~ ~ ~ ~ Liu et al. [80] BDN IJCAI 2019 0.881 0.846 0.863 0.87 0.815 0.842 ~ ~ ~ ~ ~ ~ Zhang et al. [81] LOMO CVPR 2019 0.878 0.876 0.877 ~ ~ ~ ~ ~ ~ ~ ~ ~ Zhou et al. [24] EAST CVPR 2017 0.833 0.783 0.807 0.873 0.674 0.761 ~ ~ ~ ~ ~ ~ Yue et al. [48] BMVC 2018 0.866 0.789 0.823 ~ ~ ~ ~ ~ ~ 0.691 0.660 0.675 Zhong et al. [53] AF-RPN arXiv 2018 0.89 0.83 0.86 ~ ~ ~ ~ ~ ~ ~ ~ ~ Xue et al.[85] MSR IJCAI 2019 ~ ~ ~ 0.874 0.767 0.817 ~ ~ ~ ~ ~ ~ Liao et al. [91] DB AAAI 2020 0.918 0.832 0.873 0.915 0.792 0.849 ~ ~ ~ ~ ~ ~ Xiao et al. [93] SDM ECCV 2020 0.9196 0.8922 0.9057 ~ ~ ~ ~ ~ ~ ~ ~ ~ Method Model Source Time Method Category IC15 [70] MSRA-TD500 [71] USTB-SV1K [65] SVT [66] P R F P R F P R F P R F Le et al. [5] HOCC CVPR 2014 Traditional ~ ~ ~ ~ ~ ~ ~ ~ ~ 0.80 0.73 0.76 Yao et al. [21] arXiv 2016 Segmentation 0.432 0.27 0.333 ~ ~ ~ ~ ~ ~ ~ ~ ~ Hu et al. [27] WordSup ICCV 2017 0.452 0.309 0.368 ~ ~ ~ ~ ~ ~ ~ ~ ~ Lyu et al. [43] CVPR 2018 0.351 0.348 0.349 ~ ~ ~ 0.743 0.706 0.724 ~ ~ ~ Chu et al. [45] Border ECCV 2018 ~ ~ ~ 0.782 0.588 0.671 0.777 0.621 0.690 ~ ~ ~ Yang et al. [47] IncepText IJCAI 2018 ~ ~ ~ 0.785 0.569 0.660 ~ ~ ~ ~ ~ ~ Wang et al. [54] PSENet CVPR 2019 ~ ~ ~ ~ ~ ~ 0.7535 0.6918 0.7213 ~ ~ ~ Baek et al. [62] CRAFT CVPR 2019 ~ ~ ~ ~ ~ ~ 0.806 0.682 0.739 ~ ~ ~ He et al. [29] SSTD ICCV 2017 Regression 0.46 0.31 0.37 ~ ~ ~ ~ ~ ~ ~ ~ ~ Gupta et al. [15] FCRN CVPR 2016 ~ ~ ~ ~ ~ ~ 0.844 0.763 0.801 ~ ~ ~ Liao et al. [49] TextBoxes++ TIP 2018 0.61 0.57 0.59 ~ ~ ~ ~ ~ ~ ~ ~ ~ Ma et al. [51] RRPN TMM 2018 ~ ~ ~ ~ ~ ~ 0.7669 0.5794 0.6601 ~ ~ ~ Deng et al. [56] arXiv 2018 0.555 0.633 0.591 ~ ~ ~ ~ ~ ~ ~ ~ ~ Cai et al. [59] FFN ICIP 2018 0.43 0.35 0.39 ~ ~ ~ ~ ~ ~ ~ ~ ~ Xie et al. [79] DeRPN AAAI 2019 0.586 0.557 0.571 ~ ~ ~ ~ ~ ~ ~ ~ ~ He et al. [29] SSTD ICCV 2017 0.46 0.31 0.37 ~ ~ ~ ~ ~ ~ ~ ~ ~ Liao et al. [44] RRD CVPR 2018 ~ ~ ~ 0.591 0.775 0.670 ~ ~ ~ ~ ~ ~ Richardson et al. [87] IJCAI 2019 ~ ~ ~ ~ ~ ~ 0.729 0.618 0.669 ~ ~ ~ Wang et al. [88] SAST ACMM 2019 ~ ~ ~ ~ ~ ~ 0.7935 0.6653 0.7237 ~ ~ ~ Xie et al.[61] SPCNet AAAI 2019 Hybrid ~ ~ ~ ~ ~ ~ 0.806 0.686 0.741 ~ ~ ~ Liu et al. [64] PMTD arXiv 2019 ~ ~ ~ ~ ~ ~ 0.844 0.763 0.801 ~ ~ ~ Liu et al. [80] BDN IJCAI 2019 ~ ~ ~ ~ ~ ~ 0.791 0.698 0.742 ~ ~ ~ Zhang et al. [81] LOMO CVPR 2019 ~ ~ ~ 0.791 0.602 0.684 0.802 0.672 0.731 ~ ~ ~ Zhou et al. [24] EAST CVPR 2017 0.504 0.324 0.395 ~ ~ ~ ~ ~ ~ ~ ~ ~ Zhong et al. [53] AF-RPN arXiv 2018 ~ ~ ~ ~ ~ ~ 0.75 0.66 0.70 ~ ~ ~ Liao et al. [91] DB AAAI 2020 ~ ~ ~ ~ ~ ~ 0.831 0.679 0.747 ~ ~ ~ Xiao et al. [93] SDM ECCV 2020 ~ ~ ~ ~ ~ ~ 0.8679 0.7526 0.8061 ~ ~ ~ 2.2.3 不规则文本数据集的检测结果在本节中,我们仅选择适用于不规则文本检测的那些方法。 Method Model Source Time Method Category Total-text [74] SCUT-CTW1500 [75] P R F P R F Baek et al. [62] CRAFT CVPR 2019 Segmentation 0.876 0.799 0.836 0.860 0.811 0.835 Long et al. [46] TextSnake ECCV 2018 0.827 0.745 0.784 0.679 0.853 0.756 Tian et al. [83] CVPR 2019 ~ ~ ~ 81.7 84.2 80.1 Wang et al. [54] PSENet CVPR 2019 0.840 0.779 0.809 0.848 0.797 0.822 Wang et al. [88] SAST ACMM 2019 0.8557 0.7549 0.802 0.8119 0.8171 0.8145 Wang et al. [90] PAN ICCV 2019 0.893 0.81 0.85 0.864 0.812 0.837 Zhu et al. [55] SLPR arXiv 2018 Regression ~ ~ ~ 0.801 0.701 0.748 Liu et al. [63] CTD+TLOC PR 2019 ~ ~ ~ 0.774 0.698 0.734 Wang et al. [82] CVPR 2019 ~ ~ ~ 80.1 80.2 80.1 Liu et al. [84] CVPR 2019 0.814 0.791 0.802 0.787 0.761 0.774 Tang et al.[89] Seglink++ PR 2019 0.829 0.809 0.815 0.828 0.798 0.813 Wang et al. [92] ContourNet CVPR 2020 0.869 0.839 0.854 0.837 0.841 0.839 Zhang et al. [81] LOMO CVPR 2019 Hybrid 0.876 0.793 0.833 0.857 0.765 0.808 Xie et al.[61] SPCNet AAAI 2019 0.83 0.83 0.83 ~ ~ ~ Xue et al.[85] MSR IJCAI 2019 0.852 0.73 0.768 0.838 0.778 0.807 Liao et al. [91] DB AAAI 2020 0.871 0.825 0.847 0.869 0.802 0.834 Xiao et al.[93] SDM ECCV 2020 0.9085 0.8603 0.8837 0.884 0.8442 0.8636 3. 综述[A] [TPAMI-2015] Ye Q, Doermann D. Text detection and recognition in imagery: A survey[J]. IEEE transactions on pattern analysis and machine intelligence, 2015, 37(7): 1480-1500. paper[B] [Frontiers-Comput. Sci-2016] Zhu Y, Yao C, Bai X. Scene text detection and recognition: Recent advances and future trends[J]. Frontiers of Computer Science, 2016, 10(1): 19-36. paper[C] [arXiv-2018] Long S, He X, Ya C. Scene Text Detection and Recognition: The Deep Learning Era[J]. arXiv preprint arXiv:1811.04256, 2018. paper4. Evaluation如果您有兴趣开发更好的场景文本检测指标,那么这里推荐的一些参考可能会有用:[A] Wolf, Christian, and Jean-Michel Jolion. "Object count/area graphs for the evaluation of object detection and segmentation algorithms." International Journal of Document Analysis and Recognition (IJDAR) 8.4 (2006): 280-296. paper[B] D. Karatzas, L. Gomez-Bigorda, A. Nicolaou, S. K. Ghosh, A. D.Bagdanov, M. Iwamura, J. Matas, L. Neumann, V. R. Chandrasekhar, S. Lu, F. Shafait, S. Uchida, and E. Valveny. ICDAR 2015 competition on robust reading. In ICDAR, pages 1156–1160, 2015. paper[C] Calarasanu, Stefania, Jonathan Fabrizio, and Severine Dubuisson. "What is a good evaluation protocol for text localization systems? Concerns, arguments, comparisons and solutions." Image and Vision Computing 46 (2016): 1-17. paper[D] Shi, Baoguang, et al. "ICDAR2017 competition on reading chinese text in the wild (RCTW-17)." 2017 14th IAPR International Conference on Document Analysis and Recognition (ICDAR). Vol. 1. IEEE, 2017. paper[E] Nayef, N; Yin, F; Bizid, I; et al. ICDAR2017 robust reading challenge on multi-lingual scene text detection and script identification-rrc-mlt. In Document Analysis and Recognition (ICDAR), 2017 14th IAPR International Conference on, volume 1, 1454–1459. IEEE.paper[F] Dangla, Aliona, et al. "A first step toward a fair comparison of evaluation protocols for text detection algorithms." 2018 13th IAPR International Workshop on Document Analysis Systems (DAS). IEEE, 2018. paper[G] He,Mengchao and Liu, Yuliang, et al. ICPR2018 Contest on Robust Reading for Multi-Type Web images. ICPR 2018. paper[H] Liu, Yuliang and Jin, Lianwen, et al. "Tightness-aware Evaluation Protocol for Scene Text Detection" Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR). 2019. paper code5. OCR ServiceOCRAPIFreeTesseract OCR Engine×√Azure√√ABBYY√√OCR Space√√SODA PDF OCR√√Free Online OCR√√Online OCR√√Super Tools√√Online Chinese Recognition√√Calamari OCR×√Tencent OCR√×6. References and Code [1] Yao C, Bai X, Liu W, et al. Detecting texts of arbitrary orientations in natural images. 2012 IEEE Conference on Computer Vision and Pattern Recognition(CVPR), 2012: 1083-1090. Paper[2] Yin X C, Yin X, Huang K, et al. Robust text detection in natural scene images. IEEE Transactions on Pattern Analysis & Machine Intelligence, 2013, 36(5): 970-83. Paper[3] Li Y, Jia W, Shen C, et al. Characterness: An indicator of text in the wild. IEEE transactions on image processing, 2014, 23(4): 1666-1677. Paper[4] Huang W, Qiao Y, Tang X. Robust scene text detection with convolution neural network induced mser trees. European Conference on Computer Vision(ECCV), 2014: 497-511. Paper[5] Kang L, Li Y, Doermann D. Orientation robust text line detection in natural images. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2014: 4034-4041. Paper[6] Sun L, Huo Q, Jia W, et al. A robust approach for text detection from natural scene images. Pattern Recognition, 2015, 48(9): 2906-2920. Paper[7] Yin X C, Pei W Y, Zhang J, et al. Multi-orientation scene text detection with adaptive clustering. IEEE Transactions on Pattern Analysis & Machine Intelligence, 2015 (9): 1930-1937. Paper[8] Liang G, Shivakumara P, Lu T, et al. Multi-spectral fusion based approach for arbitrarily oriented scene text detection in video images. IEEE Transactions on Image Processing, 2015, 24(11): 4488-4501. Paper[9] Wu L, Shivakumara P, Lu T, et al. A New Technique for Multi-Oriented Scene Text Line Detection and Tracking in Video. IEEE Trans. Multimedia, 2015, 17(8): 1137-1152. Paper[10] Zheng Z, Wei S, et al. Symmetry-based text line detection in natural scenes. IEEE Conference on Computer Vision & Pattern Recognition(CVPR), 2015. Paper[11] Tian S, Pan Y, Huang C, et al. Text flow: A unified text detection system in natural scene images. Proceedings of the IEEE international conference on computer vision(ICCV). 2015: 4651-4659. Paper[12] Buta M, et al. FASText: Efficient unconstrained scene text detector. 2015 IEEE International Conference on Computer Vision (ICCV). 2015: 1206-1214. Paper[13] Tian Z, Huang W, He T, et al. Detecting text in natural image with connectionist text proposal network. European conference on computer vision(ECCV), 2016: 56-72. Paper Code[14] Zhang Z, Zhang C, Shen W, et al. Multi-oriented text detection with fully convolutional networks. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition(CVPR). 2016: 4159-4167. Paper[15] Gupta A, Vedaldi A, Zisserman A. Synthetic data for text localisation in natural images. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition(CVPR). 2016: 2315-2324. Paper Code[16] S. Zhu and R. Zanibbi, A Text Detection System for Natural Scenes with Convolutional Feature Learning and Cascaded Classification, 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2016: 625-632. Paper[17] Tian S, Pei W Y, Zuo Z Y, et al. Scene Text Detection in Video by Learning Locally and Globally. IJCAI. 2016: 2647-2653. Paper[18] He T, Huang W, Qiao Y, et al. Text-attentional convolutional neural network for scene text detection. IEEE transactions on image processing, 2016, 25(6): 2529-2541. Paper[19] He, Dafang and Yang, Xiao and Huang, Wenyi and Zhou, Zihan and Kifer, Daniel and Giles, C Lee. Aggregating local context for accurate scene text detection. ACCV, 2016. Paper[20] Zhong Z, Jin L, Zhang S, et al. Deeptext: A unified framework for text proposal generation and text detection in natural images. arXiv preprint arXiv:1605.07314, 2016. Paper[21] Yao C, Bai X, Sang N, et al. Scene text detection via holistic, multi-channel prediction. arXiv preprint arXiv:1606.09002, 2016. Paper[22] Liao M, Shi B, Bai X, et al. TextBoxes: A Fast Text Detector with a Single Deep Neural Network. AAAI. 2017: 4161-4167. Paper Code[23] Shi B, Bai X, Belongie S. Detecting Oriented Text in Natural Images by Linking Segments. 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). IEEE, 2017: 3482-3490. Paper Code[24] Zhou X, Yao C, Wen H, et al. EAST: an efficient and accurate scene text detector. CVPR, 2017: 2642-2651. Paper Code[25] Liu Y, Jin L. Deep matching prior network: Toward tighter multi-oriented text detection. CVPR, 2017: 3454-3461. Paper[26] He W, Zhang X Y, Yin F, et al. Deep Direct Regression for Multi-Oriented Scene Text Detection. Proceedings of the IEEE International Conference on Computer Vision (ICCV). 2017: 745-753. Paper[27] Hu H, Zhang C, Luo Y, et al. Wordsup: Exploiting word annotations for character based text detection. ICCV, 2017. Paper[28] Wu Y, Natarajan P. Self-organized text detection with minimal post-processing via border learning. ICCV, 2017. Paper[29] He P, Huang W, He T, et al. Single shot text detector with regional attention. The IEEE International Conference on Computer Vision (ICCV). 2017, 6(7). Paper Code[30] Tian S, Lu S, Li C. Wetext: Scene text detection under weak supervision. ICCV, 2017. Paper[31] Zhu, Xiangyu and Jiang, Yingying et al. Deep Residual Text Detection Network for Scene Text. ICDAR, 2017. Paper[32] Tang Y , Wu X. Scene Text Detection and Segmentation Based on Cascaded Convolution Neural Networks. IEEE Transactions on Image Processing, 2017, 26(3):1509-1520. Paper[33] Yang C, Yin X C, Pei W Y, et al. Tracking Based Multi-Orientation Scene Text Detection: A Unified Framework with Dynamic Programming. IEEE Transactions on Image Processing, 2017. Paper[34] X. Ren, Y. Zhou, J. He, K. Chen, X. Yang and J. Sun, A Convolutional Neural Network-Based Chinese Text Detection Algorithm via Text Structure Modeling. in IEEE Transactions on Multimedia, vol. 19, no. 3, pp. 506-518, March 2017. Paper[35] Dai Y, Huang Z, Gao Y, et al. Fused text segmentation networks for multi-oriented scene text detection. arXiv preprint arXiv:1709.03272, 2017. Paper[36] Jiang Y, Zhu X, Wang X, et al. R2CNN: rotational region CNN for orientation robust scene text detection. arXiv preprint arXiv:1706.09579, 2017. Paper[37] Xing D, Li Z, Chen X, et al. ArbiText: Arbitrary-Oriented Text Detection in Unconstrained Scene. arXiv preprint arXiv:1711.11249, 2017. Paper[38] C. Wang, F. Yin and C. Liu, Scene Text Detection with Novel Superpixel Based Character Candidate Extraction. in 2017 14th IAPR International Conference on Document Analysis and Recognition (ICDAR), 2017, pp. 929-934. Paper[39] Sheng Zhang, Yuliang Liu, Lianwen Jin et al. Feature Enhancement Network: A Refined Scene Text Detector. In AAAI 2018. Paper[40] Dan Deng et al. PixelLink: Detecting Scene Text via Instance Segmentation. In AAAI 2018. Paper Code[41] Fangfang Wang, Liming Zhao, Xi L et al. Geometry-Aware Scene Text Detection with Instance Transformation Network. In CVPR 2018. Paper[42] Zichuan Liu, Guosheng Lin, Sheng Yang et al. Learning Markov Clustering Networks for Scene Text Detection. In CVPR 2018. Paper[43] Pengyuan Lyu, Cong Yao, Wenhao Wu et al. Multi-Oriented Scene Text Detection via Corner Localization and Region Segmentation. In CVPR 2018. Paper[44] Minghui L, Zhen Z, Baoguang S. Rotation-Sensitive Regression for Oriented Scene Text Detection. In CVPR 2018. Paper[45] Chuhui Xue et al. Accurate Scene Text Detection through Border Semantics Awareness and Bootstrapping. In ECCV 2018. Paper[46] Long, Shangbang and Ruan, Jiaqiang, et al. TextSnake: A Flexible Representation for Detecting Text of Arbitrary Shapes. In ECCV, 2018. Paper[47] Qiangpeng Yang, Mengli Cheng et al. IncepText: A New Inception-Text Module with Deformable PSROI Pooling for Multi-Oriented Scene Text Detection. In IJCAI 2018. Paper[48] Xiaoyu Yue et al. Boosting up Scene Text Detectors with Guided CNN. In BMVC 2018. Paper[49] Liao M, Shi B , Bai X. TextBoxes++: A Single-Shot Oriented Scene Text Detector. IEEE Transactions on Image Processing, 2018, 27(8):3676-3690. Paper Code[50] W. He, X. Zhang, F. Yin and C. Liu, Multi-Oriented and Multi-Lingual Scene Text Detection With Direct Regression, in IEEE Transactions on Image Processing, vol. 27, no. 11, pp.5406-5419, 2018. Paper[51] Ma J, Shao W, Ye H, et al. Arbitrary-oriented scene text detection via rotation proposals.in IEEE Transactions on Multimedia, 2018. Paper Code[52] Youbao Tang and Xiangqian Wu. Scene Text Detection Using Superpixel-Based Stroke Feature Transform and Deep Learning Based Region Classification. In TMM, 2018. Paper[53] Zhuoyao Zhong, Lei Sun and Qiang Huo. An Anchor-Free Region Proposal Network for Faster R-CNN based Text Detection Approaches. arXiv preprint arXiv:1804.09003. 2018. Paper[54] Wenhai W, Enze X, et al. Shape Robust Text Detection with Progressive Scale Expansion Network. In CVPR 2019. Paper Code[55] Zhu Y, Du J. Sliding Line Point Regression for Shape Robust Scene Text Detection. arXiv preprint arXiv:1801.09969, 2018. Paper[56] Linjie D, Yanxiang Gong, et al. Detecting Multi-Oriented Text with Corner-based Region Proposals. arXiv preprint arXiv: 1804.02690, 2018. Paper Code[57] Yongchao Xu, Yukang Wang, Wei Zhou, et al. TextField: Learning A Deep Direction Field for Irregular Scene Text Detection. arXiv preprint arXiv: 1812.01393, 2018. Paper[58] Xiaowei Tian, Dao Wu, Rui Wang, Xiaochun Cao. Focal Text: an Accurate Text Detection with Focal Loss. In ICIP 2018. Paper[59] Chenqin C, Pin L, Bing S. Feature Fusion Network for Scene Text Detection. In ICIP, 2018. Paper[60] Sabyasachi Mohanty et al. Recurrent Global Convolutional Network for Scene Text Detection. In ICIP 2018. Paper[61] Enze Xie, et al. Scene Text Detection with Supervised Pyramid Context Network. In AAAI 2019. Paper[62] Youngmin Baek, Bado Lee, et al. Character Region Awareness for Text Detection. In CVPR 2019. Paper[63] Yuliang L, Lianwen J, Shuaitao Z, et al. Curved Scene Text Detection via Transverse and Longitudinal Sequence Connection. Pattern Recognition, 2019. Paper Code[64] Jingchao Liu, Xuebo Liu, et al, Pyramid Mask Text Detector. arXiv preprint arXiv:1903.11800, 2019. Paper Code[79] Lele Xie, Yuliang Liu, Lianwen Jin, Zecheng Xie, DeRPN: Taking a further step toward more general object detection. In AAAI, 2019. Paper Code[80] Yuliang Liu, Lianwen Jin, et al, Omnidirectional Scene Text Detction with Sequential-free Box Discretization. In IJCAI, 2019.Paper Code[81] Chengquan Zhang, Borong Liang, et al, Look More Than Once: An Accurate Detector for Text of Arbitrary Shapes. In CVPR, 2019.Paper[82] Xiaobing Wang, Yingying Jiang, et al, Arbitrary Shape Scene Text Detection with Adaptive Text Region Representation. In CVPR, 2019. Paper[83] Zhuotao Tian, Michelle Shu, et al, Learning Shape-Aware Embedding for Scene Text Detection. In CVPR, 2019. Paper[84] Zichuan Liu, Guosheng Lin, et al, Towards Robust Curve Text Detection with Conditional Spatial Expansion. In CVPR, 2019. Paper[85] Xue C, Lu S, Zhang W. MSR: multi-scale shape regression for scene text detection. In IJCAI, 2019. Paper[86] Wang Y, Xie H, Fu Z, et al. DSRN: a deep scale relationship network for scene text detection. In IJCAI, 2019: 947-953. Paper[87] Elad Richardson, et al, It's All About The Scale -- Efficient Text Detection Using Adaptive Scaling. In WACV, 2020. Paper[88] Pengfei Wang, et al, A Single-Shot Arbitrarily-Shaped Text Detector based on Context Attended Multi-Task Learning. In ACMM, 2019. Paper[89] Jun Tang, et al, SegLink ++: Detecting Dense and Arbitrary-shaped Scene Text by Instance-aware Component Grouping. In PR, 2019. Paper[90] Wenhai Wang, et al, Efficient and Accurate Arbitrary-Shaped Text Detection with Pixel Aggregation Network. In ICCV, 2019. Paper[91] Minghui Liao, et al, Real-time Scene Text Detection with Differentiable Binarization. In AAAI, 2020. PaperCode[92] Wang, Yuxin, et al. ContourNet: Taking a Further Step toward Accurate Arbitrary-shaped Scene Text Detection. CVPR. 2020. PaperCode[93] Xiao, et al, Sequential Deformation for Accurate Scene Text Detection. In ECCV, 2020. Paper DatasetsUSTB-SV1K[65]:Xu-Cheng Yin, Xuwang Yin, Kaizhu Huang, and Hong-Wei Hao, Robust text detection in natural scene images, IEEE Trans. Pattern Analysis and Machine Intelligence (TPAMI), priprint, 2013. PaperSVT[66]: Wang,Kai, and S. Belongie. Word Spotting in the Wild. European Conference on Computer Vision(ECCV), 2010: 591-604. PaperICDAR2005[67]: Lucas, S: ICDAR 2005 text locating competition results. In: ICDAR ,2005. PaperICDAR2011[68]: Shahab, A, Shafait, F, Dengel, A: ICDAR 2011 robust reading competition challenge 2: Reading text in scene images. In: ICDAR, 2011. PaperICDAR2013[69]:D. Karatzas, F. Shafait, S. Uchida, et al. ICDAR 2013 robust reading competition. In ICDAR, 2013. PaperICDAR2015[70]:D. Karatzas, L. Gomez-Bigorda, A. Nicolaou, S. K. Ghosh, A. D.Bagdanov, M. Iwamura, J. Matas, L. Neumann, V. R. Chandrasekhar, S. Lu, F. Shafait, S. Uchida, and E. Valveny. ICDAR 2015 competition on robust reading. In ICDAR, pages 1156–1160, 2015. PaperMSRA-TD500[71]:C. Yao, X. Bai, W. Liu, Y. Ma, and Z. Tu, Detecting texts of arbitrary orientations in natural images. in Proc. IEEE Conf. Computer Vision and Pattern Recognition, 2012, pp.1083–1090.PaperCOCO-Text[72]:Veit A, Matera T, Neumann L, et al. Coco-text: Dataset and benchmark for text detection and recognition in natural images. arXiv preprint arXiv:1601.07140, 2016. PaperRCTW-17[73]:Shi B, Yao C, Liao M, et al. ICDAR2017 competition on reading chinese text in the wild (RCTW-17). Document Analysis and Recognition (ICDAR), 2017 14th IAPR International Conference on. IEEE, 2017, 1: 1429-1434. PaperTotal-Text[74]:Chee C K, Chan C S. Total-text: A comprehensive dataset for scene text detection and recognition.Document Analysis and Recognition (ICDAR), 2017 14th IAPR International Conference on. IEEE, 2017, 1: 935-942.PaperSCUT-CTW1500[75]:Yuliang L, Lianwen J, Shuaitao Z, et al. Curved Scene Text Detection via Transverse and Longitudinal Sequence Connection. Pattern Recognition, 2019.PaperMLT 2017[76]: Nayef, N; Yin, F; Bizid, I; et al. ICDAR2017 robust reading challenge on multi-lingual scene text detection and script identification-rrc-mlt. In Document Analysis and Recognition (ICDAR), 2017 14th IAPR International Conference on, volume 1, 1454–1459. IEEE. PaperOSTD[77]: Chucai Yi and YingLi Tian, Text string detection from natural scenes by structure-based partition and grouping, In IEEE Transactions on Image Processing, vol. 20, no. 9, pp. 2594–2605, 2011. PaperCTW[78]: Yuan T L, Zhu Z, Xu K, et al. Chinese Text in the Wild. arXiv preprint arXiv:1803.00085, 2018. Paper如果您发现我们的资源中有任何问题,或者我们错过了任何好的论文/代码,请通过liuchongyu1996@gmail.com通知我们。 感谢您的贡献。CopyrightCopyright © 2019 SCUT-DLVC. All Rights Reserved.
-
Scene Text Detection Resources(场景文字识别资源汇总)[转载] 1. Datasets1.1 Horizontal-Text DatasetsICDAR 2003(IC03):Introduction: It contains 509 images in total, 258 for training and 251 for testing. Specifically, it contains 1110 text instance in training set, while 1156 in testing set. It has word-level annotation. IC03 only consider English text instance.Link: IC03-downloadICDAR 2011(IC11):Introduction: IC11 is an English dataset for text detection. It contains 484 images, 229 for training and 255 for testing. There are 1564 text instance in this dataset. It provides both word-level and character-level annotation.Link: IC11-downloadICDAR 2013(IC13):Introduction: IC13 is almost the same as IC11. It contains 462 images in total, 229 for training and 233 for testing. Specifically, it contains 849 text instance in training set, while 1095 in testing set.Link: IC13-download1.2 Arbitrary-Quadrilateral-Text DatasetsUSTB-SV1K:Introduction: USTB-SV1K is an English dataset. It contains 1000 street images from Google Street View with 2955 text instance in total. It only provides word-level annotations.Link: USTB-SV1K-downloadSVT:Introduction: It contains 350 images with 725 English text intance in total. SVT has both character-level and word-level annotations. The images of SVT are harvested from Google Street View and have low resolution.Link: SVT-downloadSVT-P:Introduction: It contains 639 cropped word images for testing. Images were selected from the side-view angle snapshots in Google Street View. Therefore, most images are heavily distorted by the non-frontal view angle. It is the imporved datasets of SVT.Link: SVT-P-download (Password : vnis)ICDAR 2015(IC15):Introduction: It contains 1500 images in total, 1000 for training and 500 for testing. Specifically, it contains 17548 text instance. It provides word-level annotations. IC15 is the first incidental scene text dataset and it only considers English words.Link: IC15-downloadCOCO-Text:Introduction: It contains 63686 images in total, 43686 for training, 10000 for validating and 10000 for testing. Specifically, it contains 145859 cropped word images for testing, including handwritten and printed, clear and blur, English and non-English.Link: COCO-Text-downloadMSRA-TD500:Introduction: It contains 500 images in total. It provides text-line-level annotation rather than word, and polygon boxes rather than axis-aligned rectangles for text region annootation. It contains both English and Chinese text instance.Link: MSRA-TD500-downloadMLT 2017:Introduction: It contains 10000 natural images in total. It provides word-level annotation. There are 9 languages for MLT. It is a more real and complex datasets for scene text detection and recognition..Link: MLT-downloadMLT 2019:Introduction: It contains 18000 images in total. It provides word-level annotation. Compared to MLT, this dataset has 10 languages. It is a more real and complex datasets for scene text detection and recognition..Link: MLT-2019-downloadCTW:Introduction: It contains 32285 high resolution street view images of Chinese text, with 1018402 character instances in total. All images are annotated at the character level, including its underlying character type, bouding box, and 6 other attributes. These attributes indicate whether its background is complex, whether it’s raised, whether it’s hand-written or printed, whether it’s occluded, whether it’s distorted, whether it uses word-art.Link: CTW-downloadRCTW-17:Introduction: It contains 12514 images in total, 11514 for training and 1000 for testing. Images in RCTW-17 were mostly collected by camera or mobile phone, and others were generated images. Text instances are annotated with parallelograms. It is the first large scale Chinese dataset, and was also the largest published one by then.Link: RCTW-17-downloadReCTS:Introduction: This data set is a large-scale Chinese Street View Trademark Data Set. It is based on Chinese words and Chinese text line-level labeling. The labeling method is arbitrary quadrilateral labeling. It contains 20000 images in total.Link: ReCTS-download1.3 Irregular-Text DatasetsCUTE80:Introduction: It contains 80 high-resolution images taken in natural scenes. Specifically, it contains 288 cropped word images for testing. The dataset focuses on curved text. No lexicon is provided.Link: CUTE80-downloadTotal-Text:Introduction: It contains 1,555 images in total. Specifically, it contains 11,459 cropped word images with more than three different text orientations: horizontal, multi-oriented and curved.Link: Total-Text-downloadSCUT-CTW1500:Introduction: It contains 1500 images in total, 1000 for training and 500 for testing. Specifically, it contains 10751 cropped word images for testing. Annotations in CTW-1500 are polygons with 14 vertexes. The dataset mainly consists of Chinese and English.Link: CTW-1500-downloadLSVT:Introduction: LSVT consists of 20,000 testing data, 30,000 training data in full annotations and 400,000 training data in weak annotations, which are referred to as partial labels. The labeled text regions demonstrate the diversity of text: horizontal, multi-oriented and curved.Link: LSVT-downloadArTs:Introduction: ArT consists of 10,166 images, 5,603 for training and 4,563 for testing. They were collected with text shape diversity in mind and all text shapes have high number of existence in ArT.Link: ArT-download1.4 Synthetic DatasetsSynth80k :Introduction: It contains 800 thousands images with approximately 8 million synthetic word instances. Each text instance is annotated with its text-string, word-level and character-level bounding-boxes.Link: Synth80k-downloadSynthText :Introduction: It contains 6 million cropped word images. The generation process is similar to that of Synth90k. It is also annotated in horizontal-style.Link: SynthText-download1.5 Comparison of Datasets Comparison of Datasets Datasets Language Image Text instance Text Shape Annotation level Total Train Test Total Train Test Horizontal Arbitrary-Quadrilateral Multi-oriented Char Word Text-Line IC03 English 509 258 251 2266 1110 1156 ✓ ✕ ✕ ✕ ✓ ✕ IC11 English 484 229 255 1564 ~ ~ ✓ ✕ ✕ ✓ ✓ ✕ IC13 English 462 229 233 1944 849 1095 ✓ ✕ ✕ ✓ ✓ ✕ USTB-SV1K English 1000 500 500 2955 ~ ~ ✓ ✓ ✕ ✕ ✓ ✕ SVT English 350 100 250 725 211 514 ✓ ✓ ✕ ✓ ✓ ✕ SVT-P English 238 ~ ~ 639 ~ ~ ✓ ✓ ✕ ✕ ✓ ✕ IC15 English 1500 1000 500 17548 122318 5230 ✓ ✓ ✕ ✕ ✓ ✕ COCO-Text English 63686 43686 20000 145859 118309 27550 ✓ ✓ ✕ ✕ ✓ ✕ MSRA-TD500 English/Chinese 500 300 200 ~ ~ ~ ✓ ✓ ✕ ✕ ✕ ✓ MLT 2017 Multi-lingual 18000 7200 10800 ~ ~ ~ ✓ ✓ ✕ ✕ ✓ ✕ MLT 2019 Multi-lingual 20000 10000 10000 ~ ~ ~ ✓ ✓ ✕ ✕ ✓ ✕ CTW Chinese 32285 25887 6398 1018402 812872 205530 ✓ ✓ ✕ ✓ ✓ ✕ RCTW-17 English/Chinese 12514 15114 1000 ~ ~ ~ ✓ ✓ ✕ ✕ ✕ ✓ ReCTS Chinese 20000 ~ ~ ~ ~ ~ ✓ ✓ ✕ ✓ ✓ ✕ CUTE80 English 80 ~ ~ ~ ~ ~ ✕ ✕ ✓ ✕ ✓ ✓ Total-Text English 1525 1225 300 9330 ~ ~ ✓ ✓ ✓ ✕ ✓ ✓ CTW-1500 English/Chinese 1500 1000 500 10751 ~ ~ ✓ ✓ ✓ ✕ ✓ ✓ LSVT English/Chinese 450000 430000 20000 ~ ~ ~ ✓ ✓ ✓ ✕ ✓ ✓ ArT English/Chinese 10166 5603 4563 ~ ~ ~ ✓ ✓ ✓ ✕ ✓ ✕ Synth80k English 80k ~ ~ 8m ~ ~ ✓ ✕ ✕ ✓ ✓ ✕ SynthText English 800k ~ ~ 6m ~ ~ ✓ ✓ ✕ ✕ ✓ ✕ 2. Summary of Scene Text Detection Resources2.1 Comparison of MethodsScene text detection methods can be devided into four parts:(a) Traditional methods;(b) Segmentation-based methods;(c) Regression-based methods;(d) Hybrid methods.It is important to notice that: (1) "Hori" stands for horizontal scene text datasets. (2) "Quad" stands for arbitrary-quadrilateral-text datasets. (3) "Irreg" stands for irregular scence text datasets. (4) "Traditional method" stands for the methods that don't rely on deep learning.2.1.1 Traditional Methods Method Model Code Hori Quad Irreg Source Time Highlight Yao et al. [1] TD-Mixture ✕ ✓ ✓ ✕ CVPR 2012 1) A new dataset MSRA-TD500 and protocol for evaluation. 2) Equipped a two-level classification scheme and two sets of features extractor. Yin et al. [2] ✕ ✓ ✕ ✕ TPAMI 2013 Extract Maximally Stable Extremal Regions (MSERs) as character candidates and group them together. Le et al. [5] HOCC ✕ ✓ ✓ ✕ CVPR 2014 HOCC + MSERs Yin et al. [7] ✕ ✓ ✓ ✕ TPAMI 2015 Presenting a unified distance metric learning framework for adaptive hierarchical clustering. Wu et al. [9] ✕ ✓ ✓ ✕ TMM 2015 Exploring gradient directional symmetry at component level for smoothing edge components before text detection. Tian et al. [17] ✕ ✓ ✕ ✕ IJCAI 2016 Scene text is first detected locally in individual frames and finally linked by an optimal tracking trajectory. Yang et al. [33] ✕ ✓ ✓ ✕ TIP 2017 A text detector will locate character candidates and extract text regions. Then they will linked by an optimal tracking trajectory. Liang et al. [8] ✕ ✓ ✓ ✓ TIP 2015 Exploring maxima stable extreme regions along with stroke width transform for detecting candidate text regions. Michal et al.[12] FASText ✕ ✓ ✓ ✕ ICCV 2015 Stroke keypoints are efficiently detected and then exploited to obtain stroke segmentations. 2.1.2 Segmentation-based Methods Method Model Code Hori Quad Irreg Source Time Highlight Li et al. [3] ✕ ✓ ✓ ✕ TIP 2014 (1)develop three novel cues that are tailored for character detection and a Bayesian method for their integration; (2)design a Markov random field model to exploit the inherent dependencies between characters. Zhang et al. [14] ✕ ✓ ✓ ✕ CVPR 2016 Utilizing FCN for salient map detection and centroid of each character prediction. Zhu et al. [16] ✕ ✓ ✓ ✕ CVPR 2016 Performs a graph-based segmentation of connected components into words (Word-Graph). He et al. [18] Text-CNN ✕ ✓ ✓ ✕ TIP 2016 Developing a new learning mechanism to train the Text-CNN with multi-level and rich supervised information. Yao et al. [21] ✕ ✓ ✓ ✕ arXiv 2016 Proposing to localize text in a holistic manner, by casting scene text detection as a semantic segmentation problem. Hu et al. [27] WordSup ✕ ✓ ✓ ✕ ICCV 2017 Proposing a weakly supervised framework that can utilize word annotations. Then the detected characters are fed to a text structure analysis module. Wu et al. [28] ✕ ✓ ✓ ✕ ICCV 2017 Introducing the border class to the text detection problem for the first time, and validate that the decoding process is largely simplified with the help of text border. Tang et al.[32] ✕ ✓ ✕ ✕ TIP 2017 A text-aware candidate text region(CTR) extraction model + CTR refinement model. Dai et al. [35] FTSN ✕ ✓ ✓ ✕ arXiv 2017 Detecting and segmenting the text instance jointly and simultaneously, leveraging merits from both semantic segmentation task and region proposal based object detection task. Wang et al. [38] ✕ ✓ ✕ ✕ ICDAR 2017 This paper proposes a novel character candidate extraction method based on super-pixel segmentation and hierarchical clustering. Deng et al. [40] PixelLink ✓ ✓ ✓ ✕ AAAI 2018 Text instances are first segmented out by linking pixels wthin the same instance together. Liu et al. [42] MCN ✕ ✓ ✓ ✕ CVPR 2018 Stochastic Flow Graph (SFG) + Markov Clustering. Lyu et al. [43] ✕ ✓ ✓ ✕ CVPR 2018 Detect scene text by localizing corner points of text bounding boxes and segmenting text regions in relative positions. Chu et al. [45] Border ✕ ✓ ✓ ✕ ECCV 2018 The paper presents a novel scene text detection technique that makes use of semantics-aware text borders and bootstrapping based text segment augmentation. Long et al. [46] TextSnake ✕ ✓ ✓ ✓ ECCV 2018 The paper proposes TextSnake, which is able to effectively represent text instances in horizontal, oriented and curved forms based on symmetry axis. Yang et al. [47] IncepText ✕ ✓ ✓ ✕ IJCAI 2018 Designing a novel Inception-Text module and introduce deformable PSROI pooling to deal with multi-oriented text detection. Yue et al. [48] ✕ ✓ ✓ ✕ BMVC 2018 Proposing a general framework for text detection called Guided CNN to achieve the two goals simultaneously. Zhong et al. [53] AF-RPN ✕ ✓ ✓ ✕ arXiv 2018 Presenting AF-RPN(anchor-free) as an anchor-free and scale-friendly region proposal network for the Faster R-CNN framework. Wang et al. [54] PSENet ✓ ✓ ✓ ✓ CVPR 2019 Proposing a novel Progressive Scale Expansion Network (PSENet), designed as a segmentation-based detector with multiple predictions for each text instance. Xu et al.[57] TextField ✕ ✓ ✓ ✓ arXiv 2018 Presenting a novel direction field which can represent scene texts of arbitrary shapes. Tian et al. [58] FTDN ✕ ✓ ✓ ✕ ICIP 2018 FTDN is able to segment text region and simultaneously regress text box at pixel-level. Tian et al. [83] ✕ ✓ ✓ ✓ CVPR 2019 Constraining embedding feature of pixels inside the same text region to share similar properties. Huang et al. [4] MSERs-CNN ✕ ✓ ✕ ✕ ECCV 2014 Combining MSERs with CNN Sun et al. [6] ✕ ✓ ✕ ✕ PR 2015 Presenting a robust text detection approach based on color-enhanced CER and neural networks. Baek et al. [62] CRAFT ✕ ✓ ✓ ✓ CVPR 2019 Proposing CRAFT effectively detect text area by exploring each character and affinity between characters. Richardson et al. [87] ✕ ✓ ✓ ✕ WACV 2019 Presenting an additional scale predictor the estimate the better scale of text regions for testing. Wang et al. [88] SAST ✕ ✓ ✓ ✓ ACMM 2019 Presenting a context attended multi-task learning framework for scene text detection. Wang et al. [90] PAN ✕ ✓ ✓ ✓ ICCV 2019 Proposing an efficient and accurate arbitrary-shaped text detector called Pixel Aggregation Network(PAN), 2.1.3 Regression-based Methods Method Model Code Hori Quad Irreg Source Time Highlight Gupta et al. [15] FCRN ✓ ✓ ✕ ✕ CVPR 2016 (a) Proposing a fast and scalable engine to generate synthetic images of text in clutter; (b) FCRN. Zhong et al. [20] DeepText ✕ ✓ ✕ ✕ arXiv 2016 (a) Inception-RPN; (b) Utilize ambiguous text category (ATC) information and multilevel region-of-interest pooling (MLRP). Liao et al. [22] TextBoxes ✓ ✓ ✕ ✕ AAAI 2017 Mainly basing SSD object detection framework. Liu et al. [25] DMPNet ✕ ✓ ✓ ✕ CVPR 2017 Quadrilateral sliding windows + shared Monte-Carlo method for fast and accurate computing of the polygonal areas + a sequential protocol for relative regression. He et al. [26] DDR ✕ ✓ ✓ ✕ ICCV 2017 Proposing an FCN that has bi-task outputs where one is pixel-wise classification between text and non-text, and the other is direct regression to determine the vertex coordinates of quadrilateral text boundaries. Jiang et al. [36] R2CNN ✕ ✓ ✓ ✕ arXiv 2017 Using the Region Proposal Network (RPN) to generate axis-aligned bounding boxes that enclose the texts with different orientations. Xing et al. [37] ArbiText ✕ ✓ ✓ ✕ arXiv 2017 Adopting the circle anchors and incorporating a pyramid pooling module into the Single Shot MultiBox Detector framework. Zhang et al. [39] FEN ✕ ✓ ✕ ✕ AAAI 2018 Proposing a refined scene text detector with a novel Feature Enhancement Network (FEN) for Region Proposal and Text Detection Refinement. Wang et al. [41] ITN ✕ ✓ ✓ ✕ CVPR 2018 ITN is presented to learn the geometry-aware representation encoding the unique geometric configurations of scene text instances with in-network transformation embedding. Liao et al. [44] RRD ✕ ✓ ✓ ✕ CVPR 2018 The regression branch extracts rotation-sensitive features, while the classification branch extracts rotation-invariant features by pooling the rotation sensitive features. Liao et al. [49] TextBoxes++ ✓ ✓ ✓ ✕ TIP 2018 Mainly basing SSD object detection framework and it replaces the rectangular box representation in conventional object detector by a quadrilateral or oriented rectangle representation. He et al. [50] ✕ ✓ ✓ ✕ TIP 2018 Proposing a scene text detection framework based on fully convolutional network with a bi-task prediction module. Ma et al. [51] RRPN ✓ ✓ ✓ ✕ TMM 2018 RRPN + RRoI Pooling. Zhu et al. [55] SLPR ✕ ✓ ✓ ✓ arXiv 2018 SLPR regresses multiple points on the edge of text line and then utilizes these points to sketch the outlines of the text. Deng et al. [56] ✓ ✓ ✓ ✕ arXiv 2018 CRPN employs corners to estimate the possible locations of text instances. And it also designs a embedded data augmentation module inside region-wise subnetwork. Cai et al. [59] FFN ✕ ✓ ✕ ✕ ICIP 2018 Proposing a Feature Fusion Network to deal with text regions differing in enormous sizes. Sabyasachi et al. [60] RGC ✕ ✓ ✓ ✕ ICIP 2018 Proposing a novel recurrent architecture to improve the learnings of a feature map at a given time. Liu et al. [63] CTD ✓ ✓ ✓ ✓ PR 2019 CTD + TLOC + PNMS Xie et al. [79] DeRPN ✓ ✓ ✕ ✕ AAAI 2019 DeRPN utilizes anchor string mechanism instead of anchor box in RPN. Wang et al. [82] ✕ ✓ ✓ ✓ CVPR 2019 Text-RPN + RNN Liu et al. [84] ✕ ✓ ✓ ✓ CVPR 2019 CSE mechanism He et al. [29] SSTD ✓ ✓ ✓ ✕ ICCV 2017 Proposing an attention mechanism. Then developing a hierarchical inception module which efficiently aggregates multi-scale inception features. Tian et al. [11] ✕ ✓ ✕ ✕ ICCV 2015 Cascade boosting detects character candidates, and the min-cost flow network model get the final result. Tian et al. [13] CTPN ✓ ✓ ✕ ✕ ECCV 2016 1) RPN + LSTM. 2) RPN incorporate a new vertical anchor mechanism and LSTM connects the region to get the final result. He et al. [19] ✕ ✓ ✓ ✕ ACCV 2016 ER detetctor detects regions to get coarse prediction of text regions. Then the local context is aggregated to classify the remaining regions to obtain a final prediction. Shi et al. [23] SegLink ✓ ✓ ✓ ✕ CVPR 2017 Decomposing text into segments and links. A link connects two adjacent segments. Tian et al. [30] WeText ✕ ✓ ✕ ✕ ICCV 2017 Proposing a weakly supervised scene text detection method (WeText). Zhu et al. [31] RTN ✕ ✓ ✕ ✕ ICDAR 2017 Mainly basing CTPN vertical vertical proposal mechanism. Ren et al. [34] ✕ ✓ ✕ ✕ TMM 2017 Proposing a CNN-based detector. It contains a text structure component detector layer, a spatial pyramid layer, and a multi-input-layer deep belief network (DBN). Zhang et al. [10] ✕ ✓ ✕ ✕ CVPR 2015 The proposed algorithm exploits the symmetry property of character groups and allows for direct extraction of text lines from natural images. Wang et al. [86] DSRN ✕ ✓ ✓ ✕ IJCAI 2019 Presenting a scale-transfer module and scale relationship module to handle the problem of scale variation. Tang et al.[89] Seglink++ ✕ ✓ ✓ ✓ PR 2019 Presenting instance aware component grouping (ICG) for arbitrary-shape text detection. Wang et al.[92] ContourNet ✓ ✓ ✓ ✓ CVPR 2020 1.A scale-insensitive Adaptive Region Proposal Network (AdaptiveRPN); 2. Local Orthogonal Texture-aware Module (LOTM). 2.1.4 Hybrid Methods Method Model Code Hori Quad Irreg Source Time Highlight Tang et al. [52] SSFT ✕ ✓ ✕ ✕ TMM 2018 Proposing a novel scene text detection method that involves superpixel-based stroke feature transform (SSFT) and deep learning based region classification (DLRC). Xie et al.[61] SPCNet ✕ ✓ ✓ ✓ AAAI 2019 Text Context module + Re-Score mechanism. Liu et al. [64] PMTD ✓ ✓ ✓ ✕ arXiv 2019 Perform “soft” semantic segmentation. It assigns a soft pyramid label (i.e., a real value between 0 and 1) for each pixel within text instance. Liu et al. [80] BDN ✓ ✓ ✓ ✕ IJCAI 2019 Discretizing bouding boxes into key edges to address label confusion for text detection. Zhang et al. [81] LOMO ✕ ✓ ✓ ✓ CVPR 2019 DR + IRM + SEM Zhou et al. [24] EAST ✓ ✓ ✓ ✕ CVPR 2017 The pipeline directly predicts words or text lines of arbitrary orientations and quadrilateral shapes in full images with instance segmentation. Yue et al. [48] ✕ ✓ ✓ ✕ BMVC 2018 Proposing a general framework for text detection called Guided CNN to achieve the two goals simultaneously. Zhong et al. [53] AF-RPN ✕ ✓ ✓ ✕ arXiv 2018 Presenting AF-RPN(anchor-free) as an anchor-free and scale-friendly region proposal network for the Faster R-CNN framework. Xue et al.[85] MSR ✕ ✓ ✓ ✓ IJCAI 2019 Presenting a noval multi-scale regression network. Liao et al. [91] DB ✓ ✓ ✓ ✓ AAAI 2020 Presenting differentiable binarization module to adaptively set the thresholds for binarization, which simplifies the post-processing. Xiao et al. [93] SDM ✕ ✓ ✓ ✓ ECCV 2020 1. A novel sequential deformation method; 2. auxiliary character counting supervision. 2.2 Detection Results2.2.1 Detection Results on Horizontal-Text Datasets Method Model Source Time Method Category IC11[68] IC13 [69] IC05[67] P R F P R F P R F Yao et al. [1] TD-Mixture CVPR 2012 Traditional ~ ~ ~ 0.69 0.66 0.67 ~ ~ ~ Yin et al. [2] TPAMI 2013 0.86 0.68 0.76 ~ ~ ~ ~ ~ ~ Yin et al. [7] TPAMI 2015 0.838 0.66 0.738 ~ ~ ~ ~ ~ ~ Wu et al. [9] TMM 2015 ~ ~ ~ 0.76 0.70 0.73 ~ ~ ~ Liang et al. [8] TIP 2015 0.77 0.68 0.71 0.76 0.68 0.72 ~ ~ ~ Michal et al.[12] FASText ICCV 2015 ~ ~ ~ 0.84 0.69 0.77 ~ ~ ~ Li et al. [3] TIP 2014 Segmentation 0.80 0.62 0.70 ~ ~ ~ ~ ~ ~ Zhang et al. [14] CVPR 2016 ~ ~ ~ 0.88 0.78 0.83 ~ ~ ~ He et al. [18] Text-CNN TIP 2016 0.91 0.74 0.82 0.93 0.73 0.82 0.87 0.73 0.79 Yao et al. [21] arXiv 2016 ~ ~ ~ 0.889 0.802 0.843 ~ ~ ~ Hu et al. [27] WordSup ICCV 2017 ~ ~ ~ 0.933 0.875 0.903 ~ ~ ~ Tang et al.[32] TIP 2017 0.90 0.86 0.88 0.92 0.87 0.89 ~ ~ ~ Wang et al. [38] ICDAR 2017 0.87 0.78 0.82 0.87 0.82 0.84 ~ ~ ~ Deng et al. [40] PixelLink AAAI 2018 ~ ~ ~ 0.886 0.875 0.881 ~ ~ ~ Liu et al. [42] MCN CVPR 2018 ~ ~ ~ 0.88 0.87 0.88 ~ ~ ~ Lyu et al. [43] CVPR 2018 ~ ~ ~ 0.92 0.844 0.880 ~ ~ ~ Chu et al. [45] Border ECCV 2018 ~ ~ ~ 0.915 0.871 0.892 ~ ~ ~ Wang et al. [54] PSENet CVPR 2019 ~ ~ ~ 0.94 0.90 0.92 ~ ~ ~ Huang et al. [4] MSERs-CNN ECCV 2014 0.88 0.71 0.78 ~ ~ ~ 0.84 0.67 0.75 Sun et al. [6] PR 2015 0.92 0.91 0.91 0.94 0.92 0.93 ~ ~ ~ Gupta et al. [15] FCRN CVPR 2016 Regression 0.94 0.77 0.85 0.938 0.764 0.842 ~ ~ ~ Zhong et al. [20] DeepText arXiv 2016 0.87 0.83 0.85 0.85 0.81 0.83 ~ ~ ~ Liao et al. [22] TextBoxes AAAI 2017 0.89 0.82 0.86 0.89 0.83 0.86 ~ ~ ~ Liu et al. [25] DMPNet CVPR 2017 ~ ~ ~ 0.93 0.83 0.870 ~ ~ ~ Jiang et al. [36] R2CNN arXiv 2017 ~ ~ ~ 0.92 0.81 0.86 ~ ~ ~ Xing et al. [37] ArbiText arXiv 2017 ~ ~ ~ 0.826 0.936 0.877 ~ ~ ~ Wang et al. [41] ITN CVPR 2018 0.896 0.889 0.892 0.941 0.893 0.916 ~ ~ ~ Liao et al. [49] TextBoxes++ TIP 2018 ~ ~ ~ 0.92 0.86 0.89 ~ ~ ~ He et al. [50] TIP 2018 ~ ~ ~ 0.91 0.84 0.88 ~ ~ ~ Ma et al. [51] RRPN TMM 2018 ~ ~ ~ 0.95 0.89 0.91 ~ ~ ~ Zhu et al. [55] SLPR arXiv 2018 ~ ~ ~ 0.90 0.72 0.80 ~ ~ ~ Cai et al. [59] FFN ICIP 2018 ~ ~ ~ 0.92 0.84 0.876 ~ ~ ~ Sabyasachi et al. [60] RGC ICIP 2018 ~ ~ ~ 0.89 0.77 0.83 ~ ~ ~ Wang et al. [82] CVPR 2019 ~ ~ ~ 0.937 0.878 0.907 ~ ~ ~ Liu et al. [84] CVPR 2019 ~ ~ ~ 0.937 0.897 0.917 ~ ~ ~ He et al. [29] SSTD ICCV 2017 ~ ~ ~ 0.89 0.86 0.88 ~ ~ ~ Tian et al. [11] ICCV 2015 0.86 0.76 0.81 0.852 0.759 0.802 ~ ~ ~ Tian et al. [13] CTPN ECCV 2016 ~ ~ ~ 0.93 0.83 0.88 ~ ~ ~ He et al. [19] ACCV 2016 ~ ~ ~ 0.90 0.75 0.81 ~ ~ ~ Shi et al. [23] SegLink CVPR 2017 ~ ~ ~ 0.877 0.83 0.853 ~ ~ ~ Tian et al. [30] WeText ICCV 2017 ~ ~ ~ 0.911 0.831 0.869 ~ ~ ~ Zhu et al. [31] RTN ICDAR 2017 ~ ~ ~ 0.94 0.89 0.91 ~ ~ ~ Ren et al. [34] TMM 2017 0.78 0.67 0.72 0.81 0.67 0.73 ~ ~ ~ Zhang et al. [10] CVPR 2015 0.84 0.76 0.80 0.88 0.74 0.80 ~ ~ ~ Tang et al. [52] SSFT TMM 2018 Hybrid 0.906 0.847 0.876 0.911 0.861 0.885 ~ ~ ~ Xie et al.[61] SPCNet AAAI 2019 ~ ~ ~ 0.94 0.91 0.92 ~ ~ ~ Liu et al. [80] BDN IJCAI 2019 ~ ~ ~ 0.887 0.894 0.89 ~ ~ ~ Zhou et al. [24] EAST CVPR 2017 ~ ~ ~ 0.93 0.83 0.870 ~ ~ ~ Yue et al. [48] BMVC 2018 ~ ~ ~ 0.885 0.846 0.870 ~ ~ ~ Zhong et al. [53] AF-RPN arXiv 2018 ~ ~ ~ 0.94 0.90 0.92 ~ ~ ~ Xue et al.[85] MSR IJCAI 2019 ~ ~ ~ 0.918 0.885 0.901 ~ ~ ~ 2.2.2 Detection Results on Arbitrary-Quadrilateral-Text Datasets Method Model Source Time Method Category IC15 [70] MSRA-TD500 [71] USTB-SV1K [65] SVT [66] P R F P R F P R F P R F Le et al. [5] HOCC CVPR 2014 Traditional ~ ~ ~ 0.71 0.62 0.66 ~ ~ ~ ~ ~ ~ Yin et al. [7] TPAMI 2015 ~ ~ ~ 0.81 0.63 0.71 0.499 0.454 0.475 ~ ~ ~ Wu et al. [9] TMM 2015 ~ ~ ~ 0.63 0.70 0.66 ~ ~ ~ ~ ~ ~ Tian et al. [17] IJCAI 2016 ~ ~ ~ 0.95 0.58 0.721 0.537 0.488 0.51 ~ ~ ~ Yang et al. [33] TIP 2017 ~ ~ ~ 0.95 0.58 0.72 0.54 0.49 0.51 ~ ~ ~ Liang et al. [8] TIP 2015 ~ ~ ~ 0.74 0.66 0.70 ~ ~ ~ ~ ~ ~ Zhang et al. [14] CVPR 2016 Segmentation 0.71 0.43 0.54 0.83 0.67 0.74 ~ ~ ~ ~ ~ ~ Zhu et al. [16] CVPR 2016 0.81 0.91 0.85 ~ ~ ~ ~ ~ ~ ~ ~ ~ He et al. [18] Text-CNN TIP 2016 ~ ~ ~ 0.76 0.61 0.69 ~ ~ ~ ~ ~ ~ Yao et al. [21] arXiv 2016 0.723 0.587 0.648 0.765 0.753 0.759 ~ ~ ~ ~ ~ ~ Hu et al. [27] WordSup ICCV 2017 0.793 0.77 0.782 ~ ~ ~ ~ ~ ~ ~ ~ ~ Wu et al. [28] ICCV 2017 0.91 0.78 0.84 0.77 0.78 0.77 ~ ~ ~ ~ ~ ~ Dai et al. [35] FTSN arXiv 2017 0.886 0.80 0.841 0.876 0.771 0.82 ~ ~ ~ ~ ~ ~ Deng et al. [40] PixelLink AAAI 2018 0.855 0.820 0.837 0.830 0.732 0.778 ~ ~ ~ ~ ~ ~ Liu et al. [42] MCN CVPR 2018 0.72 0.80 0.76 0.88 0.79 0.83 ~ ~ ~ ~ ~ ~ Lyu et al. [43] CVPR 2018 0.895 0.797 0.843 0.876 0.762 0.815 ~ ~ ~ ~ ~ ~ Chu et al. [45] Border ECCV 2018 ~ ~ ~ 0.830 0.774 0.801 ~ ~ ~ ~ ~ ~ Long et al. [46] TextSnake ECCV 2018 0.849 0.804 0.826 0.832 0.739 0.783 ~ ~ ~ ~ ~ ~ Yang et al. [47] IncepText IJCAI 2018 0.938 0.873 0.905 0.875 0.790 0.830 ~ ~ ~ ~ ~ ~ Wang et al. [54] PSENet CVPR 2019 0.8692 0.845 0.8569 ~ ~ ~ ~ ~ ~ ~ ~ ~ Xu et al.[57] TextField arXiv 2018 0.843 0.805 0.824 0.874 0.759 0.813 ~ ~ ~ ~ ~ ~ Tian et al. [58] FTDN ICIP 2018 0.847 0.773 0.809 ~ ~ ~ ~ ~ ~ ~ ~ ~ Tian et al. [83] CVPR 2019 0.883 0.850 0.866 0.842 0.817 0.829 ~ ~ ~ ~ ~ ~ Baek et al. [62] CRAFT CVPR 2019 0.898 0.843 0.869 0.882 0.782 0.829 ~ ~ ~ ~ ~ ~ Richardson et al. [87] IJCAI 2019 0.853 0.83 0.827 ~ ~ ~ ~ ~ ~ ~ ~ ~ Wang et al. [88] SAST ACMM 2019 0.8755 0.8734 0.8744 ~ ~ ~ ~ ~ ~ ~ ~ ~ Wang et al. [90] PAN ICCV 2019 0.84 0.819 0.829 0.844 0.838 0.821 ~ ~ ~ ~ ~ ~ Gupta et al. [15] FCRN CVPR 2016 Regression ~ ~ ~ ~ ~ ~ ~ ~ ~ 0.651 0.599 0.624 Liu et al. [25] DMPNet CVPR 2017 0.732 0.682 0.706 ~ ~ ~ ~ ~ ~ ~ ~ ~ He et al. [26] DDR ICCV 2017 0.82 0.80 0.81 0.77 0.70 0.74 ~ ~ ~ ~ ~ ~ Jiang et al. [36] R2CNN arXiv 2017 0.856 0.797 0.825 ~ ~ ~ ~ ~ ~ ~ ~ ~ Xing et al. [37] ArbiText arXiv 2017 0.792 0.735 0.759 0.78 0.72 0.75 ~ ~ ~ ~ ~ ~ Wang et al. [41] ITN CVPR 2018 0.857 0.741 0.795 0.903 0.723 0.803 ~ ~ ~ ~ ~ ~ Liao et al. [44] RRD CVPR 2018 0.88 0.8 0.838 0.876 0.73 0.79 ~ ~ ~ ~ ~ ~ Liao et al. [49] TextBoxes++ TIP 2018 0.878 0.785 0.829 ~ ~ ~ ~ ~ ~ ~ ~ ~ He et al. [50] TIP 2018 0.85 0.80 0.82 0.91 0.81 0.86 ~ ~ ~ ~ ~ ~ Ma et al. [51] RRPN TMM 2018 0.822 0.732 0.774 0.821 0.677 0.742 ~ ~ ~ ~ ~ ~ Zhu et al. [55] SLPR arXiv 2018 0.855 0.836 0.845 ~ ~ ~ ~ ~ ~ ~ ~ ~ Deng et al. [56] arXiv 2018 0.89 0.81 0.845 ~ ~ ~ ~ ~ ~ ~ ~ ~ Sabyasachi et al. [60] RGC ICIP 2018 0.83 0.81 0.82 0.85 0.76 0.80 ~ ~ ~ ~ ~ ~ Wang et al. [82] CVPR 2019 0.892 0.86 0.876 0.852 0.821 0.836 ~ ~ ~ ~ ~ ~ He et al. [29] SSTD ICCV 2017 0.80 0.73 0.77 ~ ~ ~ ~ ~ ~ ~ ~ ~ Tian et al. [13] CTPN ECCV 2016 0.74 0.52 0.61 ~ ~ ~ ~ ~ ~ ~ ~ ~ He et al. [19] ACCV 2016 ~ ~ ~ ~ ~ ~ ~ ~ ~ 0.87 0.73 0.79 Shi et al. [23] SegLink CVPR 2017 0.731 0.768 0.75 0.86 0.70 0.77 ~ ~ ~ ~ ~ ~ Wang et al. [86] DSRN IJCAI 2019 0.832 0.796 0.814 0.876 0.712 0.785 ~ ~ ~ ~ ~ ~ Tang et al.[89] Seglink++ PR 2019 0.837 0.803 0.820 ~ ~ ~ ~ ~ ~ ~ ~ ~ Wang et al. [92] ContourNet CVPR 2020 0.876 0.861 0.869 ~ ~ ~ ~ ~ ~ ~ ~ ~ Tang et al. [52] SSFT TMM 2018 Hybrid ~ ~ ~ ~ ~ ~ ~ ~ ~ 0.541 0.758 0.631 Xie et al.[61] SPCNet AAAI 2019 0.89 0.86 0.87 ~ ~ ~ ~ ~ ~ ~ ~ ~ Liu et al. [64] PMTD arXiv 2019 0.913 0.874 0.893 ~ ~ ~ ~ ~ ~ ~ ~ ~ Liu et al. [80] BDN IJCAI 2019 0.881 0.846 0.863 0.87 0.815 0.842 ~ ~ ~ ~ ~ ~ Zhang et al. [81] LOMO CVPR 2019 0.878 0.876 0.877 ~ ~ ~ ~ ~ ~ ~ ~ ~ Zhou et al. [24] EAST CVPR 2017 0.833 0.783 0.807 0.873 0.674 0.761 ~ ~ ~ ~ ~ ~ Yue et al. [48] BMVC 2018 0.866 0.789 0.823 ~ ~ ~ ~ ~ ~ 0.691 0.660 0.675 Zhong et al. [53] AF-RPN arXiv 2018 0.89 0.83 0.86 ~ ~ ~ ~ ~ ~ ~ ~ ~ Xue et al.[85] MSR IJCAI 2019 ~ ~ ~ 0.874 0.767 0.817 ~ ~ ~ ~ ~ ~ Liao et al. [91] DB AAAI 2020 0.918 0.832 0.873 0.915 0.792 0.849 ~ ~ ~ ~ ~ ~ Xiao et al. [93] SDM ECCV 2020 0.9196 0.8922 0.9057 ~ ~ ~ ~ ~ ~ ~ ~ ~ Method Model Source Time Method Category IC15 [70] MSRA-TD500 [71] USTB-SV1K [65] SVT [66] P R F P R F P R F P R F Le et al. [5] HOCC CVPR 2014 Traditional ~ ~ ~ ~ ~ ~ ~ ~ ~ 0.80 0.73 0.76 Yao et al. [21] arXiv 2016 Segmentation 0.432 0.27 0.333 ~ ~ ~ ~ ~ ~ ~ ~ ~ Hu et al. [27] WordSup ICCV 2017 0.452 0.309 0.368 ~ ~ ~ ~ ~ ~ ~ ~ ~ Lyu et al. [43] CVPR 2018 0.351 0.348 0.349 ~ ~ ~ 0.743 0.706 0.724 ~ ~ ~ Chu et al. [45] Border ECCV 2018 ~ ~ ~ 0.782 0.588 0.671 0.777 0.621 0.690 ~ ~ ~ Yang et al. [47] IncepText IJCAI 2018 ~ ~ ~ 0.785 0.569 0.660 ~ ~ ~ ~ ~ ~ Wang et al. [54] PSENet CVPR 2019 ~ ~ ~ ~ ~ ~ 0.7535 0.6918 0.7213 ~ ~ ~ Baek et al. [62] CRAFT CVPR 2019 ~ ~ ~ ~ ~ ~ 0.806 0.682 0.739 ~ ~ ~ He et al. [29] SSTD ICCV 2017 Regression 0.46 0.31 0.37 ~ ~ ~ ~ ~ ~ ~ ~ ~ Gupta et al. [15] FCRN CVPR 2016 ~ ~ ~ ~ ~ ~ 0.844 0.763 0.801 ~ ~ ~ Liao et al. [49] TextBoxes++ TIP 2018 0.61 0.57 0.59 ~ ~ ~ ~ ~ ~ ~ ~ ~ Ma et al. [51] RRPN TMM 2018 ~ ~ ~ ~ ~ ~ 0.7669 0.5794 0.6601 ~ ~ ~ Deng et al. [56] arXiv 2018 0.555 0.633 0.591 ~ ~ ~ ~ ~ ~ ~ ~ ~ Cai et al. [59] FFN ICIP 2018 0.43 0.35 0.39 ~ ~ ~ ~ ~ ~ ~ ~ ~ Xie et al. [79] DeRPN AAAI 2019 0.586 0.557 0.571 ~ ~ ~ ~ ~ ~ ~ ~ ~ He et al. [29] SSTD ICCV 2017 0.46 0.31 0.37 ~ ~ ~ ~ ~ ~ ~ ~ ~ Liao et al. [44] RRD CVPR 2018 ~ ~ ~ 0.591 0.775 0.670 ~ ~ ~ ~ ~ ~ Richardson et al. [87] IJCAI 2019 ~ ~ ~ ~ ~ ~ 0.729 0.618 0.669 ~ ~ ~ Wang et al. [88] SAST ACMM 2019 ~ ~ ~ ~ ~ ~ 0.7935 0.6653 0.7237 ~ ~ ~ Xie et al.[61] SPCNet AAAI 2019 Hybrid ~ ~ ~ ~ ~ ~ 0.806 0.686 0.741 ~ ~ ~ Liu et al. [64] PMTD arXiv 2019 ~ ~ ~ ~ ~ ~ 0.844 0.763 0.801 ~ ~ ~ Liu et al. [80] BDN IJCAI 2019 ~ ~ ~ ~ ~ ~ 0.791 0.698 0.742 ~ ~ ~ Zhang et al. [81] LOMO CVPR 2019 ~ ~ ~ 0.791 0.602 0.684 0.802 0.672 0.731 ~ ~ ~ Zhou et al. [24] EAST CVPR 2017 0.504 0.324 0.395 ~ ~ ~ ~ ~ ~ ~ ~ ~ Zhong et al. [53] AF-RPN arXiv 2018 ~ ~ ~ ~ ~ ~ 0.75 0.66 0.70 ~ ~ ~ Liao et al. [91] DB AAAI 2020 ~ ~ ~ ~ ~ ~ 0.831 0.679 0.747 ~ ~ ~ Xiao et al. [93] SDM ECCV 2020 ~ ~ ~ ~ ~ ~ 0.8679 0.7526 0.8061 ~ ~ ~ 2.2.3 Detection Results on Irregular-Text DatasetsIn this section, we only select those methods suitable for irregular text detection. Method Model Source Time Method Category Total-text [74] SCUT-CTW1500 [75] P R F P R F Baek et al. [62] CRAFT CVPR 2019 Segmentation 0.876 0.799 0.836 0.860 0.811 0.835 Long et al. [46] TextSnake ECCV 2018 0.827 0.745 0.784 0.679 0.853 0.756 Tian et al. [83] CVPR 2019 ~ ~ ~ 81.7 84.2 80.1 Wang et al. [54] PSENet CVPR 2019 0.840 0.779 0.809 0.848 0.797 0.822 Wang et al. [88] SAST ACMM 2019 0.8557 0.7549 0.802 0.8119 0.8171 0.8145 Wang et al. [90] PAN ICCV 2019 0.893 0.81 0.85 0.864 0.812 0.837 Zhu et al. [55] SLPR arXiv 2018 Regression ~ ~ ~ 0.801 0.701 0.748 Liu et al. [63] CTD+TLOC PR 2019 ~ ~ ~ 0.774 0.698 0.734 Wang et al. [82] CVPR 2019 ~ ~ ~ 80.1 80.2 80.1 Liu et al. [84] CVPR 2019 0.814 0.791 0.802 0.787 0.761 0.774 Tang et al.[89] Seglink++ PR 2019 0.829 0.809 0.815 0.828 0.798 0.813 Wang et al. [92] ContourNet CVPR 2020 0.869 0.839 0.854 0.837 0.841 0.839 Zhang et al. [81] LOMO CVPR 2019 Hybrid 0.876 0.793 0.833 0.857 0.765 0.808 Xie et al.[61] SPCNet AAAI 2019 0.83 0.83 0.83 ~ ~ ~ Xue et al.[85] MSR IJCAI 2019 0.852 0.73 0.768 0.838 0.778 0.807 Liao et al. [91] DB AAAI 2020 0.871 0.825 0.847 0.869 0.802 0.834 Xiao et al.[93] SDM ECCV 2020 0.9085 0.8603 0.8837 0.884 0.8442 0.8636 3. Survey[A] [TPAMI-2015] Ye Q, Doermann D. Text detection and recognition in imagery: A survey[J]. IEEE transactions on pattern analysis and machine intelligence, 2015, 37(7): 1480-1500. paper[B] [Frontiers-Comput. Sci-2016] Zhu Y, Yao C, Bai X. Scene text detection and recognition: Recent advances and future trends[J]. Frontiers of Computer Science, 2016, 10(1): 19-36. paper[C] [arXiv-2018] Long S, He X, Ya C. Scene Text Detection and Recognition: The Deep Learning Era[J]. arXiv preprint arXiv:1811.04256, 2018. paper4. EvaluationIf you are insterested in developing better scene text detection metrics, some references recommended here might be useful.[A] Wolf, Christian, and Jean-Michel Jolion. "Object count/area graphs for the evaluation of object detection and segmentation algorithms." International Journal of Document Analysis and Recognition (IJDAR) 8.4 (2006): 280-296. paper[B] D. Karatzas, L. Gomez-Bigorda, A. Nicolaou, S. K. Ghosh, A. D.Bagdanov, M. Iwamura, J. Matas, L. Neumann, V. R. Chandrasekhar, S. Lu, F. Shafait, S. Uchida, and E. Valveny. ICDAR 2015 competition on robust reading. In ICDAR, pages 1156–1160, 2015. paper[C] Calarasanu, Stefania, Jonathan Fabrizio, and Severine Dubuisson. "What is a good evaluation protocol for text localization systems? Concerns, arguments, comparisons and solutions." Image and Vision Computing 46 (2016): 1-17. paper[D] Shi, Baoguang, et al. "ICDAR2017 competition on reading chinese text in the wild (RCTW-17)." 2017 14th IAPR International Conference on Document Analysis and Recognition (ICDAR). Vol. 1. IEEE, 2017. paper[E] Nayef, N; Yin, F; Bizid, I; et al. ICDAR2017 robust reading challenge on multi-lingual scene text detection and script identification-rrc-mlt. In Document Analysis and Recognition (ICDAR), 2017 14th IAPR International Conference on, volume 1, 1454–1459. IEEE.paper[F] Dangla, Aliona, et al. "A first step toward a fair comparison of evaluation protocols for text detection algorithms." 2018 13th IAPR International Workshop on Document Analysis Systems (DAS). IEEE, 2018. paper[G] He,Mengchao and Liu, Yuliang, et al. ICPR2018 Contest on Robust Reading for Multi-Type Web images. ICPR 2018. paper[H] Liu, Yuliang and Jin, Lianwen, et al. "Tightness-aware Evaluation Protocol for Scene Text Detection" Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR). 2019. paper code5. OCR ServiceOCRAPIFreeTesseract OCR Engine×√Azure√√ABBYY√√OCR Space√√SODA PDF OCR√√Free Online OCR√√Online OCR√√Super Tools√√Online Chinese Recognition√√Calamari OCR×√Tencent OCR√×6. References and Code [1] Yao C, Bai X, Liu W, et al. Detecting texts of arbitrary orientations in natural images. 2012 IEEE Conference on Computer Vision and Pattern Recognition(CVPR), 2012: 1083-1090. Paper[2] Yin X C, Yin X, Huang K, et al. Robust text detection in natural scene images. IEEE Transactions on Pattern Analysis & Machine Intelligence, 2013, 36(5): 970-83. Paper[3] Li Y, Jia W, Shen C, et al. Characterness: An indicator of text in the wild. IEEE transactions on image processing, 2014, 23(4): 1666-1677. Paper[4] Huang W, Qiao Y, Tang X. Robust scene text detection with convolution neural network induced mser trees. European Conference on Computer Vision(ECCV), 2014: 497-511. Paper[5] Kang L, Li Y, Doermann D. Orientation robust text line detection in natural images. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2014: 4034-4041. Paper[6] Sun L, Huo Q, Jia W, et al. A robust approach for text detection from natural scene images. Pattern Recognition, 2015, 48(9): 2906-2920. Paper[7] Yin X C, Pei W Y, Zhang J, et al. Multi-orientation scene text detection with adaptive clustering. IEEE Transactions on Pattern Analysis & Machine Intelligence, 2015 (9): 1930-1937. Paper[8] Liang G, Shivakumara P, Lu T, et al. Multi-spectral fusion based approach for arbitrarily oriented scene text detection in video images. IEEE Transactions on Image Processing, 2015, 24(11): 4488-4501. Paper[9] Wu L, Shivakumara P, Lu T, et al. A New Technique for Multi-Oriented Scene Text Line Detection and Tracking in Video. IEEE Trans. Multimedia, 2015, 17(8): 1137-1152. Paper[10] Zheng Z, Wei S, et al. Symmetry-based text line detection in natural scenes. IEEE Conference on Computer Vision & Pattern Recognition(CVPR), 2015. Paper[11] Tian S, Pan Y, Huang C, et al. Text flow: A unified text detection system in natural scene images. Proceedings of the IEEE international conference on computer vision(ICCV). 2015: 4651-4659. Paper[12] Buta M, et al. FASText: Efficient unconstrained scene text detector. 2015 IEEE International Conference on Computer Vision (ICCV). 2015: 1206-1214. Paper[13] Tian Z, Huang W, He T, et al. Detecting text in natural image with connectionist text proposal network. European conference on computer vision(ECCV), 2016: 56-72. Paper Code[14] Zhang Z, Zhang C, Shen W, et al. Multi-oriented text detection with fully convolutional networks. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition(CVPR). 2016: 4159-4167. Paper[15] Gupta A, Vedaldi A, Zisserman A. Synthetic data for text localisation in natural images. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition(CVPR). 2016: 2315-2324. Paper Code[16] S. Zhu and R. Zanibbi, A Text Detection System for Natural Scenes with Convolutional Feature Learning and Cascaded Classification, 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2016: 625-632. Paper[17] Tian S, Pei W Y, Zuo Z Y, et al. Scene Text Detection in Video by Learning Locally and Globally. IJCAI. 2016: 2647-2653. Paper[18] He T, Huang W, Qiao Y, et al. Text-attentional convolutional neural network for scene text detection. IEEE transactions on image processing, 2016, 25(6): 2529-2541. Paper[19] He, Dafang and Yang, Xiao and Huang, Wenyi and Zhou, Zihan and Kifer, Daniel and Giles, C Lee. Aggregating local context for accurate scene text detection. ACCV, 2016. Paper[20] Zhong Z, Jin L, Zhang S, et al. Deeptext: A unified framework for text proposal generation and text detection in natural images. arXiv preprint arXiv:1605.07314, 2016. Paper[21] Yao C, Bai X, Sang N, et al. Scene text detection via holistic, multi-channel prediction. arXiv preprint arXiv:1606.09002, 2016. Paper[22] Liao M, Shi B, Bai X, et al. TextBoxes: A Fast Text Detector with a Single Deep Neural Network. AAAI. 2017: 4161-4167. Paper Code[23] Shi B, Bai X, Belongie S. Detecting Oriented Text in Natural Images by Linking Segments. 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). IEEE, 2017: 3482-3490. Paper Code[24] Zhou X, Yao C, Wen H, et al. EAST: an efficient and accurate scene text detector. CVPR, 2017: 2642-2651. Paper Code[25] Liu Y, Jin L. Deep matching prior network: Toward tighter multi-oriented text detection. CVPR, 2017: 3454-3461. Paper[26] He W, Zhang X Y, Yin F, et al. Deep Direct Regression for Multi-Oriented Scene Text Detection. Proceedings of the IEEE International Conference on Computer Vision (ICCV). 2017: 745-753. Paper[27] Hu H, Zhang C, Luo Y, et al. Wordsup: Exploiting word annotations for character based text detection. ICCV, 2017. Paper[28] Wu Y, Natarajan P. Self-organized text detection with minimal post-processing via border learning. ICCV, 2017. Paper[29] He P, Huang W, He T, et al. Single shot text detector with regional attention. The IEEE International Conference on Computer Vision (ICCV). 2017, 6(7). Paper Code[30] Tian S, Lu S, Li C. Wetext: Scene text detection under weak supervision. ICCV, 2017. Paper[31] Zhu, Xiangyu and Jiang, Yingying et al. Deep Residual Text Detection Network for Scene Text. ICDAR, 2017. Paper[32] Tang Y , Wu X. Scene Text Detection and Segmentation Based on Cascaded Convolution Neural Networks. IEEE Transactions on Image Processing, 2017, 26(3):1509-1520. Paper[33] Yang C, Yin X C, Pei W Y, et al. Tracking Based Multi-Orientation Scene Text Detection: A Unified Framework with Dynamic Programming. IEEE Transactions on Image Processing, 2017. Paper[34] X. Ren, Y. Zhou, J. He, K. Chen, X. Yang and J. Sun, A Convolutional Neural Network-Based Chinese Text Detection Algorithm via Text Structure Modeling. in IEEE Transactions on Multimedia, vol. 19, no. 3, pp. 506-518, March 2017. Paper[35] Dai Y, Huang Z, Gao Y, et al. Fused text segmentation networks for multi-oriented scene text detection. arXiv preprint arXiv:1709.03272, 2017. Paper[36] Jiang Y, Zhu X, Wang X, et al. R2CNN: rotational region CNN for orientation robust scene text detection. arXiv preprint arXiv:1706.09579, 2017. Paper[37] Xing D, Li Z, Chen X, et al. ArbiText: Arbitrary-Oriented Text Detection in Unconstrained Scene. arXiv preprint arXiv:1711.11249, 2017. Paper[38] C. Wang, F. Yin and C. Liu, Scene Text Detection with Novel Superpixel Based Character Candidate Extraction. in 2017 14th IAPR International Conference on Document Analysis and Recognition (ICDAR), 2017, pp. 929-934. Paper[39] Sheng Zhang, Yuliang Liu, Lianwen Jin et al. Feature Enhancement Network: A Refined Scene Text Detector. In AAAI 2018. Paper[40] Dan Deng et al. PixelLink: Detecting Scene Text via Instance Segmentation. In AAAI 2018. Paper Code[41] Fangfang Wang, Liming Zhao, Xi L et al. Geometry-Aware Scene Text Detection with Instance Transformation Network. In CVPR 2018. Paper[42] Zichuan Liu, Guosheng Lin, Sheng Yang et al. Learning Markov Clustering Networks for Scene Text Detection. In CVPR 2018. Paper[43] Pengyuan Lyu, Cong Yao, Wenhao Wu et al. Multi-Oriented Scene Text Detection via Corner Localization and Region Segmentation. In CVPR 2018. Paper[44] Minghui L, Zhen Z, Baoguang S. Rotation-Sensitive Regression for Oriented Scene Text Detection. In CVPR 2018. Paper[45] Chuhui Xue et al. Accurate Scene Text Detection through Border Semantics Awareness and Bootstrapping. In ECCV 2018. Paper[46] Long, Shangbang and Ruan, Jiaqiang, et al. TextSnake: A Flexible Representation for Detecting Text of Arbitrary Shapes. In ECCV, 2018. Paper[47] Qiangpeng Yang, Mengli Cheng et al. IncepText: A New Inception-Text Module with Deformable PSROI Pooling for Multi-Oriented Scene Text Detection. In IJCAI 2018. Paper[48] Xiaoyu Yue et al. Boosting up Scene Text Detectors with Guided CNN. In BMVC 2018. Paper[49] Liao M, Shi B , Bai X. TextBoxes++: A Single-Shot Oriented Scene Text Detector. IEEE Transactions on Image Processing, 2018, 27(8):3676-3690. Paper Code[50] W. He, X. Zhang, F. Yin and C. Liu, Multi-Oriented and Multi-Lingual Scene Text Detection With Direct Regression, in IEEE Transactions on Image Processing, vol. 27, no. 11, pp.5406-5419, 2018. Paper[51] Ma J, Shao W, Ye H, et al. Arbitrary-oriented scene text detection via rotation proposals.in IEEE Transactions on Multimedia, 2018. Paper Code[52] Youbao Tang and Xiangqian Wu. Scene Text Detection Using Superpixel-Based Stroke Feature Transform and Deep Learning Based Region Classification. In TMM, 2018. Paper[53] Zhuoyao Zhong, Lei Sun and Qiang Huo. An Anchor-Free Region Proposal Network for Faster R-CNN based Text Detection Approaches. arXiv preprint arXiv:1804.09003. 2018. Paper[54] Wenhai W, Enze X, et al. Shape Robust Text Detection with Progressive Scale Expansion Network. In CVPR 2019. Paper Code[55] Zhu Y, Du J. Sliding Line Point Regression for Shape Robust Scene Text Detection. arXiv preprint arXiv:1801.09969, 2018. Paper[56] Linjie D, Yanxiang Gong, et al. Detecting Multi-Oriented Text with Corner-based Region Proposals. arXiv preprint arXiv: 1804.02690, 2018. Paper Code[57] Yongchao Xu, Yukang Wang, Wei Zhou, et al. TextField: Learning A Deep Direction Field for Irregular Scene Text Detection. arXiv preprint arXiv: 1812.01393, 2018. Paper[58] Xiaowei Tian, Dao Wu, Rui Wang, Xiaochun Cao. Focal Text: an Accurate Text Detection with Focal Loss. In ICIP 2018. Paper[59] Chenqin C, Pin L, Bing S. Feature Fusion Network for Scene Text Detection. In ICIP, 2018. Paper[60] Sabyasachi Mohanty et al. Recurrent Global Convolutional Network for Scene Text Detection. In ICIP 2018. Paper[61] Enze Xie, et al. Scene Text Detection with Supervised Pyramid Context Network. In AAAI 2019. Paper[62] Youngmin Baek, Bado Lee, et al. Character Region Awareness for Text Detection. In CVPR 2019. Paper[63] Yuliang L, Lianwen J, Shuaitao Z, et al. Curved Scene Text Detection via Transverse and Longitudinal Sequence Connection. Pattern Recognition, 2019. Paper Code[64] Jingchao Liu, Xuebo Liu, et al, Pyramid Mask Text Detector. arXiv preprint arXiv:1903.11800, 2019. Paper Code[79] Lele Xie, Yuliang Liu, Lianwen Jin, Zecheng Xie, DeRPN: Taking a further step toward more general object detection. In AAAI, 2019. Paper Code[80] Yuliang Liu, Lianwen Jin, et al, Omnidirectional Scene Text Detction with Sequential-free Box Discretization. In IJCAI, 2019.Paper Code[81] Chengquan Zhang, Borong Liang, et al, Look More Than Once: An Accurate Detector for Text of Arbitrary Shapes. In CVPR, 2019.Paper[82] Xiaobing Wang, Yingying Jiang, et al, Arbitrary Shape Scene Text Detection with Adaptive Text Region Representation. In CVPR, 2019. Paper[83] Zhuotao Tian, Michelle Shu, et al, Learning Shape-Aware Embedding for Scene Text Detection. In CVPR, 2019. Paper[84] Zichuan Liu, Guosheng Lin, et al, Towards Robust Curve Text Detection with Conditional Spatial Expansion. In CVPR, 2019. Paper[85] Xue C, Lu S, Zhang W. MSR: multi-scale shape regression for scene text detection. In IJCAI, 2019. Paper[86] Wang Y, Xie H, Fu Z, et al. DSRN: a deep scale relationship network for scene text detection. In IJCAI, 2019: 947-953. Paper[87] Elad Richardson, et al, It's All About The Scale -- Efficient Text Detection Using Adaptive Scaling. In WACV, 2020. Paper[88] Pengfei Wang, et al, A Single-Shot Arbitrarily-Shaped Text Detector based on Context Attended Multi-Task Learning. In ACMM, 2019. Paper[89] Jun Tang, et al, SegLink ++: Detecting Dense and Arbitrary-shaped Scene Text by Instance-aware Component Grouping. In PR, 2019. Paper[90] Wenhai Wang, et al, Efficient and Accurate Arbitrary-Shaped Text Detection with Pixel Aggregation Network. In ICCV, 2019. Paper[91] Minghui Liao, et al, Real-time Scene Text Detection with Differentiable Binarization. In AAAI, 2020. PaperCode[92] Wang, Yuxin, et al. ContourNet: Taking a Further Step toward Accurate Arbitrary-shaped Scene Text Detection. CVPR. 2020. PaperCode[93] Xiao, et al, Sequential Deformation for Accurate Scene Text Detection. In ECCV, 2020. Paper DatasetsUSTB-SV1K[65]:Xu-Cheng Yin, Xuwang Yin, Kaizhu Huang, and Hong-Wei Hao, Robust text detection in natural scene images, IEEE Trans. Pattern Analysis and Machine Intelligence (TPAMI), priprint, 2013. PaperSVT[66]: Wang,Kai, and S. Belongie. Word Spotting in the Wild. European Conference on Computer Vision(ECCV), 2010: 591-604. PaperICDAR2005[67]: Lucas, S: ICDAR 2005 text locating competition results. In: ICDAR ,2005. PaperICDAR2011[68]: Shahab, A, Shafait, F, Dengel, A: ICDAR 2011 robust reading competition challenge 2: Reading text in scene images. In: ICDAR, 2011. PaperICDAR2013[69]:D. Karatzas, F. Shafait, S. Uchida, et al. ICDAR 2013 robust reading competition. In ICDAR, 2013. PaperICDAR2015[70]:D. Karatzas, L. Gomez-Bigorda, A. Nicolaou, S. K. Ghosh, A. D.Bagdanov, M. Iwamura, J. Matas, L. Neumann, V. R. Chandrasekhar, S. Lu, F. Shafait, S. Uchida, and E. Valveny. ICDAR 2015 competition on robust reading. In ICDAR, pages 1156–1160, 2015. PaperMSRA-TD500[71]:C. Yao, X. Bai, W. Liu, Y. Ma, and Z. Tu, Detecting texts of arbitrary orientations in natural images. in Proc. IEEE Conf. Computer Vision and Pattern Recognition, 2012, pp.1083–1090.PaperCOCO-Text[72]:Veit A, Matera T, Neumann L, et al. Coco-text: Dataset and benchmark for text detection and recognition in natural images. arXiv preprint arXiv:1601.07140, 2016. PaperRCTW-17[73]:Shi B, Yao C, Liao M, et al. ICDAR2017 competition on reading chinese text in the wild (RCTW-17). Document Analysis and Recognition (ICDAR), 2017 14th IAPR International Conference on. IEEE, 2017, 1: 1429-1434. PaperTotal-Text[74]:Chee C K, Chan C S. Total-text: A comprehensive dataset for scene text detection and recognition.Document Analysis and Recognition (ICDAR), 2017 14th IAPR International Conference on. IEEE, 2017, 1: 935-942.PaperSCUT-CTW1500[75]:Yuliang L, Lianwen J, Shuaitao Z, et al. Curved Scene Text Detection via Transverse and Longitudinal Sequence Connection. Pattern Recognition, 2019.PaperMLT 2017[76]: Nayef, N; Yin, F; Bizid, I; et al. ICDAR2017 robust reading challenge on multi-lingual scene text detection and script identification-rrc-mlt. In Document Analysis and Recognition (ICDAR), 2017 14th IAPR International Conference on, volume 1, 1454–1459. IEEE. PaperOSTD[77]: Chucai Yi and YingLi Tian, Text string detection from natural scenes by structure-based partition and grouping, In IEEE Transactions on Image Processing, vol. 20, no. 9, pp. 2594–2605, 2011. PaperCTW[78]: Yuan T L, Zhu Z, Xu K, et al. Chinese Text in the Wild. arXiv preprint arXiv:1803.00085, 2018. PaperIf you find any problems in our resources, or any good papers/codes we have missed, please inform us at liuchongyu1996@gmail.com. Thank you for your contribution.CopyrightCopyright © 2019 SCUT-DLVC. All Rights Reserved.
-
IOU计算 IOU计算&判断两个矩形相交以及求出相交的区域求解图示一$$ IOU=area/(area1+area2-area) $$求解图示二理论分析-判断两个矩形相交以及求出相交的区域问题:给定两个矩形A和B,矩形A的左上角坐标为(Xa1,Ya1),右下角坐标为(Xa2,Ya2),矩形B的左上角坐标为(Xb1,Yb1),右下角 坐标为(Xb2,Yb2)。1.设计一个算法,确定两个矩形是否相交(即有重叠区域)对于这个问题,一般的思路就是判断一个矩形的四个顶点是否在另一个矩形的区域内。这个思路最简单,但是效率不高,并且存在错误,错误在哪里,下面分析一 下。 如上图,把矩形的相交(区域重叠)分成三种(可能也有其他划分),对于第三种情况,如图中的(3),两个矩形相交,但并不存在一个矩形的顶点在另一个矩形 内部。所以那种思路存在一个错误,对于这种情况的相交则检查不出。仔细观察上图,想到另一种思路,那就是判断两个矩形的中心坐标的水平和垂直距离,只要这两个值满足某种条件就可以相交。矩形A的宽 Wa = Xa2-Xa1 高 Ha = Ya2-Ya1矩形B的宽 Wb = Xb2-Xb1 高 Hb = Yb2-Yb1矩形A的中心坐标 (Xa3,Ya3) = ( (Xa2+Xa1)/2 ,(Ya2+Ya1)/2 )矩形B的中心坐标 (Xb3,Yb3) = ( (Xb2+Xb1)/2 ,(Yb2+Yb1)/2 )所以只要同时满足下面两个式子,就可以说明两个矩形相交。1) | Xb3-Xa3 | <= Wa/2 + Wb/22) | Yb3-Ya3 | <= Ha/2 + Hb/2即:| Xb2+Xb1-Xa2-Xa1 | <= Xa2-Xa1 + Xb2-Xb1| Yb2+Yb1-Ya2-Ya1 | <=Y a2-Ya1 + Yb2-Yb12.如果两个矩形相交,设计一个算法,求出相交的区域矩形Xc1 = max(Xa1,Xb1)Yc1 = max(Ya1,Yb1)Xc2 = min(Xa2,Xb2)Yc2 = min(Ya2,Yb2)这样就求出了矩形的相交区域。另外,注意到在不假设矩形相交的前提下,定义(Xc1,Yc1),(Xc2,Yc2),且Xc1,Yc1,Xc2,Yc2的值由上面四个式子得出。这样, 可以依据Xc1,Yc1,Xc2,Yc2的值来判断矩形相交。Xc1,Yc1,Xc2,Yc2只要同时满足下面两个式子,就可以说明两个矩形相交。3) Xc1 <= Xc24) Yc1 <= Yc2即:max(Xa1,Xb1) <= min(Xa2,Xb2)max(Ya1,Yb1) <= min(Ya2,Yb2)代码实现代码""" IOU计算 + input + box1:[box1_x1,box1_y1,box1_x2,box1_y2] + box2:[box2_x1,box2_y1,box2_x2,box2_y2] + output + iou值 """ def cal_iou(box1,box2): # 判断是否能相交 if abs(box2[2]+box2[0]-box1[2]-box1[0])>box2[2]-box2[0]+box1[2]-box1[0]: return 0 if abs(box2[3]+box2[1]-box1[3]-box1[1])>box2[3]-box2[1]+box1[3]-box1[1]: return 0 # 求相交区域左上角的坐标和右下角的坐标 box_intersect_x1 = max(box1[0], box2[0]) box_intersect_y1 = max(box1[1], box2[1]) box_intersect_x2 = min(box1[2], box2[2]) box_intersect_y2 = min(box1[3], box2[3]) # 求二者相交的面积 area_intersect = (box_intersect_y2 - box_intersect_y1) * (box_intersect_x2 - box_intersect_x1) # 求box1,box2的面积 area_box1 = (box1[2] - box1[0]) * (box1[3] - box1[1]) area_box2 = (box2[2] - box2[0]) * (box2[3] - box2[1]) # 求二者相并的面积 area_union = area_box1 + area_box2 - area_intersect # 计算iou(交并比) iou = area_intersect / area_union return iou验证box1 = [0,0,500,500] box2 = [250,250,750,750] iou = cal_iou(box1,box2) print(iou)0.14285714285714285人为验证图示import matplotlib.pyplot as plt fig1 = plt.figure() ax1 = fig1.add_subplot(111, aspect='equal') ax1.add_patch(plt.Rectangle((0, 0),500,500,color='b',alpha=0.5)) ax1.add_patch(plt.Rectangle((250, 250),500,500,color='b',alpha=0.5)) ax1.add_patch(plt.Rectangle((250, 250),250,250,color='r',alpha=0.5)) plt.xlim(0, 750) plt.ylim(0, 750) plt.show()由图易知:area_box1= 250000area_box2= 250000area_intersect= 62500area_union= 437500因此:iou = 62500 / 437500 = 0.14285714285714285参考资料yolo 算法中的IOU算法程序与原理解读:https://blog.csdn.net/caokaifa/article/details/80724842IOU的计算:https://www.cnblogs.com/darkknightzh/p/9043395.html判断两个矩形相交以及求出相交的区域:https://www.cnblogs.com/zhoug2020/p/7451340.html
-
YOLOv3学习:(三)模型输出解码 YOLOv3学习:(三)模型输出解码YOLOv3 模型输出输出模型输出解码-理论(以13*13为例)解码目标模型输出shape:[batch_size, 255, 13, 13] 255 = 3(先验框数量)*(x_offset+y_offset+w_scale+h_scale+有无物体置信度+类别置信度)即原模型将图像分割为13*13的小块进行预测,每个小块负责根据先验框预测3个框,每个预测框以小格的左上角为基准点,以先验框的w和h为基准。$$ 预测框w=先验框w \times e^{w\_scale} $$$$ 预测框h=先验框h \times e^{h\_scale} $$模型输出解码的目标即为将输出结果的x_offset+y_offset+w_scale+h_scale部分进行校正,变成以整个图片的最左上角(0,0)点为基准点,并对每个预测框的w,h根据先验框进行对应校正。最终的到3*13*13个预测框。即解码输出shape:[batch_size, 3*13*13,85] 85=x_offset+y_offset+w_scale+h_scale+有无物体置信度+类别置信度模型输出解码-代码# YOLOv3 超参数 from easydict import EasyDict super_param = \ { "anchors": [[[116, 90], [156, 198], [373, 326]], [[30, 61], [62, 45], [59, 119]], [[10, 13], [16, 30], [33, 23]]], "num_classes": 80, "img_size":(416,416), } super_param = EasyDict(super_param) print(super_param.img_size) # YOLOv3模型输出结果解码器 """ 模型输出结果解释: 以[batch_size, 255, 13, 13]为例 255 = 3(先验框数量)*(x_offset+y_offset+w+h+有无物体置信度+类别置信度) 代表将原图划分为13*13 然后每个小框负责预测3个框 每个框的中心点为(框的左上角x+x_offset,框的左上角y+y_offset) 每个框的w和h为 torch.exp(w.data) * anchor_w 和torch.exp(h.data) * anchor_h 解码输出结果解释: 实例对应输出shape为[batch_size,3*13*13,85],即共预测了3*13*13个boxm 每个box的具体参数为(x+y+w+h+有无物体置信度+80个类别置信度)共85个 """ class DecodeBox(nn.Module): def __init__(self, anchors = super_param.anchors[0], num_classes = super_param.num_classes, img_size = super_param.img_size): super(DecodeBox, self).__init__() self.anchors = anchors self.num_anchors = len(anchors) self.num_classes = num_classes self.img_size = img_size def forward(self, input): # 获取YOLOv3单路输出的结果shape信息 batch_size,input_height,input_width = input.size(0),input.size(2),input.size(3) # 计算步长 stride_h,stride_w = self.img_size[1] / input_height,self.img_size[0] / input_width # 把把先验框归一到特征层上 eg:[116, 90], [156, 198], [373, 326] --》[116/32, 90/32], [156/32, 198/32], [373/32, 326/32] scaled_anchors = [(anchor_width / stride_w, anchor_height / stride_h) for anchor_width, anchor_height in self.anchors] # 对预测结果进行reshape # eg:[batch_size, 255, 13, 13] -->[batch_size,num_anchors,input_height,input_width,5 + num_classes](batch_size,3,13,13,85) # 维度中的85包含了4+1+80,分别代表x_offset、y_offset、h和w、置信度、分类结果。 prediction = input.view(batch_size, self.num_anchors, 5 + self.num_classes, input_height, input_width).permute(0, 1, 3, 4, 2).contiguous() # 先验框的中心位置的调整参数 x_offset,y_offset = torch.sigmoid(prediction[..., 0]),torch.sigmoid(prediction[..., 1]) # 先验框的宽高调整参数 w,h = prediction[..., 2],prediction[..., 3] # Width.Height # 获得置信度,是否有物体 conf = torch.sigmoid(prediction[..., 4]) # 种类置信度 pred_cls = torch.sigmoid(prediction[..., 5:]) # Cls pred. FloatTensor = torch.cuda.FloatTensor if x_offset.is_cuda else torch.FloatTensor LongTensor = torch.cuda.LongTensor if x_offset.is_cuda else torch.LongTensor # 生成网格,先验框中心,网格左上角 grid_x = torch.linspace(0, input_width - 1, input_width).repeat(input_width, 1).repeat( batch_size * self.num_anchors, 1, 1).view(x_offset.shape).type(FloatTensor) grid_y = torch.linspace(0, input_height - 1, input_height).repeat(input_height, 1).t().repeat( batch_size * self.num_anchors, 1, 1).view(y_offset.shape).type(FloatTensor) # 生成先验框的宽高 anchor_w = FloatTensor(scaled_anchors).index_select(1, LongTensor([0])) anchor_h = FloatTensor(scaled_anchors).index_select(1, LongTensor([1])) anchor_w = anchor_w.repeat(batch_size, 1).repeat(1, 1, input_height * input_width).view(w.shape) anchor_h = anchor_h.repeat(batch_size, 1).repeat(1, 1, input_height * input_width).view(h.shape) # 计算调整后的先验框中心与宽高 pred_boxes = FloatTensor(prediction[..., :4].shape) pred_boxes[..., 0] = x_offset.data + grid_x pred_boxes[..., 1] = y_offset.data + grid_y pred_boxes[..., 2] = torch.exp(w.data) * anchor_w pred_boxes[..., 3] = torch.exp(h.data) * anchor_h # 用于将输出调整为相对于416x416的大小 _scale = torch.Tensor([stride_w, stride_h] * 2).type(FloatTensor) output = torch.cat((pred_boxes.view(batch_size, -1, 4) * _scale, conf.view(batch_size, -1, 1), pred_cls.view(batch_size, -1, self.num_classes)), -1) return output.data测试fake_out1 = torch.zeros((1,255,13,13)) print(fake_out1.shape) decoder = DecodeBox() out1_decode = decoder(fake_out1) print(out1_decode.shape)torch.Size([1, 255, 13, 13]) torch.Size([1, 507, 85])参考资料Pytorch 搭建自己的YOLO3目标检测平台(Bubbliiiing 深度学习 教程):https://www.bilibili.com/video/BV1Hp4y1y788?p=11&spm_id_from=pageDriver
-
【YOLOv3论文翻译】:YOLOv3:增量式的改进 【YOLOv3论文翻译】:YOLOv3:增量式的改进论文原文:YOLOv3: An Incremental Improvement摘要我们对YOLO进行了一系列更新!它包含一堆小设计,可以使系统的性能得到更新。我们也训练了一个新的、比较大的神经网络。虽然比上一版更大一些,但是精度也提高了。不用担心,它的速度依然很快。YOLOv3在320×320输入图像上运行时只需22ms,并能达到28.2mAP,其精度和SSD相当,但速度要快上3倍。使用之前0.5 IOU mAP的检测指标,YOLOv3的效果是相当不错。YOLOv3使用Titan X GPU,其耗时51ms检测精度达到57.9 AP50,与RetinaNet相比,其精度只有57.5 AP50,但却耗时198ms,相同性能的条件下YOLOv3速度比RetinaNet快3.8倍。与之前一样,所有代码在网址:https://pjreddie.com/yolo/。1. 引言有时候,一年内你主要都在玩手机,你知道吗?今年我没有做很多研究。我在Twitter上花了很多时间。研究了一下GAN。去年我留下了一点点的精力[12] [1];我设法对YOLO进行了一些改进。但是,实话实说,除了仅仅一些小的改变使得它变得更好之外,没有什么超级有趣的事情。我也稍微帮助了其他人的一些研究。其实,这就是今天我要讲的内容。我们有一篇论文快截稿了,并且我们还缺一篇关于YOLO更新内容的文章作为引用,但是我们没有引用来源。因此准备写一篇技术报告!技术报告的好处是他们不需要引言,你们都知道我为什么写这个。所以引言的结尾可以作为阅读本文剩余内容的一个指引。首先我们会告诉你YOLOv3的方案。其次我们会告诉你我们是如何实现的。我们也会告诉你我们尝试过但并不奏效的一些事情。最后我们将探讨这些的意义。2. 方案这节主要介绍YOLOv3的方案:我们主要从其他人的研究工作里获得了一些好思路、好想法。我们还训练了一个新的、比其他网络更好的分类网络。为了方便您理解,我们将带您从头到尾贯穿整个模型系统。![图1.这个图来自Focal Loss论文[9]。YOLOv3的运行速度明显快于其他具有可比性能的检测方法。检测时间基于M40或Titan X(这两个基本上是相同的GPU)。](/usr/uploads/auto_save_image/f1b7a2d2167837f377fafa85701fb668.png)2.1 边界框预测按照YOLO9000,我们的系统也使用维度聚类得到的anchor框来预测边界框[15]。网络为每个边界框预测的4个坐标:tx、ty、tw、th。假设格子距离图像的左上角偏移量为(cx,cy),先验边界框宽度和高度分别为:pw、ph,则预测结果对应为:训练时我们使用误差平方和损失。如果某个预测坐标的真值是$\hat{t^*}$,那么梯度就是真值(从真值框计算而得)和预测值之差:$\hat{t^*}-t^*$。真实值可以很容易地通过变换上述公式得到。YOLOv3使用逻辑回归预测每个边界框是目标的分数。如果真实标签框与某个边界框重叠的面积比与其他任何边界框都大,那么这个先验边界框得分为1。按照[17]的做法,如果先验边界框不是最好的,但是确实与目标的真实标签框重叠的面积大于阈值,我们就会忽略这个预测。我们使用阈值为0.5。与[17]不同,我们的系统只为每个真实目标分配一个边界框。如果先验边界框未分配到真实目标,则不会产生坐标或类别预测的损失,只会产生是否是目标的损失。![图2.维度先验和位置预测的边界框。我们使用聚类质心的偏移量预测框的宽度和高度。我们使用sigmoid函数预测相对于滤波器应用位置的框的中心坐标。这个图公然引用于自己的论文[15]。](/usr/uploads/auto_save_image/cf8bd0eecaa2aefdb8f1e86fbe6a4961.png)2.2 分类预测每个边界框都会使用多标签分类来预测框中可能包含的类。我们不用softmax,而是用单独的逻辑分类器,因为我们发现前者对于提升网络性能没什么作用。在训练过程中,我们用binary cross-entropy(二元交叉熵)损失来预测类别。当我们转向更复杂的领域,例如Open Images Dataset [7],上面的这种改变将变得很有用。这个数据集中有许多重叠的标签(例如女性和人)。使用softmax会强加这样一个假设——即每个框恰好只有一个类别,但通常情况并非如此。多标签的方式可以更好地模拟数据。2.3 跨尺度预测YOLOv3预测3种不同尺度的框。我们的系统使用类似特征金字塔网络的相似概念,并从这些尺度中提取特征[8]。在我们的基础特征提取器上添加了几个卷积层。其中最后一个卷积层预测了一个编码边界框、是否是目标和类别预测结果的三维张量。在我们的COCO实验[8]中,我们为每个尺度预测3个框,所以对于每个边界框的4个偏移量、1个目标预测和80个类别预测,最终的张量大小为N×N×[3×(4+1+80)]。接下来,我们从前面的2个层中取得特征图,并将其上采样2倍。我们还从网络中的较前的层中获取特征图,并将其与我们的上采样特征图进行拼接。这种方法使我们能够从上采样的特征图中获得更有意义的语义信息,同时可以从更前的层中获取更细粒度的信息。然后,我们添加几个卷积层来处理这个特征映射组合,并最终预测出一个相似的、大小是原先两倍的张量。我们再次使用相同的设计来预测最终尺寸的边界框。因此,第三个尺寸的预测将既能从所有先前的计算,又能从网络前面的层中的细粒度的特征中获益。我们仍然使用k-means聚类来确定我们的先验边界框。我们只是选择了9个类和3个尺度,然后在所有尺度上将聚类均匀地分开。在COCO数据集上,9个聚类分别为(10×13)、(16×30)、(33×23)、(30×61)、(62×45)、(59×119)、(116 × 90)、(156 × 198)、(373 × 326)。2.4 特征提取器我们使用一个新的网络来进行特征提取。我们的新网络融合了YOLOv2、Darknet-19和新发明的残差网络的思想。我们的网络使用连续的3×3和1×1卷积层,而且现在多了一些快捷连接(shortcut connetction),而且规模更大。它有53个卷积层,所以我们称之为... Darknet-53!这个新网络比Darknet-19功能强大很多,并且仍然比ResNet-101或ResNet-152更高效。以下是一些ImageNet上的结果:每个网络都使用相同的设置进行训练,并在256×256的图像上进行单精度测试。运行时间是在Titan X上用256×256图像进行测量的。因此,Darknet-53可与最先进的分类器相媲美,但浮点运算更少,速度更快。Darknet-53比ResNet-101更好,且速度快1.5倍。Darknet-53与ResNet-152相比性能差不多,但速度快比其2倍。Darknet-53也实现了最高的每秒浮点运算测量。这意味着网络结构可以更好地利用GPU,使它的评测更加高效、更快。这主要是因为ResNets的层数太多,效率不高。2.5 训练我们仍然在完整的图像上进行训练,没有使用难负样本挖掘(hard negative mining)或其他类似的方法。我们使用多尺度训练,使用大量的数据增强、批量标准化等标准的操作。我们使用Darknet神经网络框架进行训练和测试[12]。3 我们是如何做的YOLOv3表现非常好!请看表3。就COCO的平均AP指标而言,它与SSD类的模型相当,但速度提高了3倍。尽管如此,它仍然在这个指标上比像RetinaNet这样的其他模型差些。![表3.我很认真地从[9]中“窃取”了所有这些表格,他们花了很长时间才从头开始制作。好的,YOLOv3没问题。请记住,RetinaNet处理图像的时间要长3.8倍。YOLOv3比SSD变体要好得多,可与AP50指标上的最新模型相媲美。](/usr/uploads/auto_save_image/b315b290b4c82ed2f24a0538afbbfbd4.png)然而,当我们使用“旧的”检测指标——在IOU=0.5的mAP(或图表中的AP50)时,YOLOv3非常强大。其性能几乎与RetinaNet相当,并且远强于SSD。这表明YOLOv3是一个非常强大的检测器,擅长为目标生成恰当的框。然而,随着IOU阈值增加,性能显著下降,这表明YOLOv3预测的边界框与目标不能完美对齐。之前的YOLO不擅长检测小物体。但是,现在我们看到了这种趋势的逆转。随着新的多尺度预测,我们看到YOLOv3具有相对较高的APS性能。但是,它在中等和更大尺寸的物体上的表现相对较差。需要更多的研究来深入了解这一点。当我们在AP50指标上绘制准确度和速度关系图时(见图3),我们看到YOLOv3与其他检测系统相比具有显着的优势。也就是说,速度更快、性能更好。![图3. 再次改编自[9],这次显示的是在0.5 IOU指标上速度/准确度的折衷。你可以说YOLOv3是好的,因为它非常高并且在左边很远。 你能引用你自己的论文吗?猜猜谁会去尝试,这个人→[16]。哦,我忘了,我们还修复了YOLOv2中的数据加载bug,该bug的修复提升了2 mAP。将YOLOv3结果潜入这幅图中而没有改变原始布局。](/usr/uploads/auto_save_image/d381f8d42ff1a78d2af931002d8d9127.png)4 失败的尝试我们在研究YOLOv3时尝试了很多东西,但很多都不起作用。下面是我们要记住的血的教训。Anchor框的x、y偏移预测。我们尝试使用常规的Anchor框预测机制,比如利用线性激活将坐标x、y的偏移程度预测为边界框宽度或高度的倍数。但我们发现这种方法降低了模型的稳定性,并且效果不佳。用线性激活代替逻辑激活函数进行x、y预测。我们尝试使用线性激活代替逻辑激活来直接预测x、y偏移。这个改变导致MAP下降了几个点。focal loss。我们尝试使用focal loss。它使得mAP下降2个点。YOLOv3可能已经对focal loss试图解决的问题具有鲁棒性,因为它具有单独的目标预测和条件类别预测。因此,对于大多数样本来说,类别预测没有损失?或者有一些?我们并不完全确定。双IOU阈值和真值分配。Faster R-CNN在训练期间使用两个IOU阈值。如果一个预测与真实标签框重叠超过0.7,它就是一个正样本,若重叠为[0.3,0.7]之间,那么它会被忽略,若它与所有的真实标签框的IOU小于0.3,那么一个负样本。我们尝试了类似的策略,但无法取得好的结果。我们非常喜欢目前的更新,它似乎至少在局部达到了最佳。有些方法可能最终会产生好的结果,也许他们只是需要一些调整来稳定训练。5 这一切意味着什么YOLOv3是一个很好的检测器。速度很快、很准确。它在COCO平均AP介于0.5和0.95 IOU之间的指标的上并不理想。但是,对于旧的0.5 IOU检测指标上效果非常好。为什么我们要改变指标?COCO的原论文只是有这样一句含糊不清的句子:“一旦评估服务器完成,就会生成全面评测指标”。Russakovsky等人的报告说,人们很难区分0.3和0.5的IOU。“训练人类用视觉检查0.3 IOU的边界框,并且与0.5 IOU的框区别开来是非常困难的。“[16]如果人类很难说出差异,那么它也没有多重要吧?但是也许更好的问题是:“现在我们有了这些检测器,我们要做什么?”很多做关于这方面的研究的人都受聘于Google和Facebook。我想至少我们知道这项技术在好人的手中,绝对不会被用来收集您的个人信息并将其出售给......等等,您是说这正是它的用途?oh。其他花大钱资助视觉研究的人还有军方,他们从来没有做过任何可怕的事情,例如用新技术杀死很多人,等等.....(脚注:作者由the Office of Naval Research and Google资助支持。)我强烈地希望,大多数使用计算机视觉的人都用它来做一些快乐且有益的事情,比如计算一个国家公园里斑马的数量[11],或者追踪在附近徘徊的猫[17]。但是计算机视觉已经有很多可疑的用途,作为研究人员,我们有责任考虑我们的工作可能造成的损害,并思考如何减轻它的影响。我们欠这个世界太多。最后,不要再@我了。(因为哥已经退出Twitter这个是非之地了)。参考文献[1] Analogy. Wikipedia, Mar 2018. 1[2] M. Everingham, L. Van Gool, C. K. Williams, J. Winn, and A. Zisserman. The pascal visual object classes (voc) challenge. International journal of computer vision, 88(2):303–338, 2010. 6[3] C.-Y. Fu, W. Liu, A. Ranga, A. Tyagi, and A. C. Berg. Dssd: Deconvolutional single shot detector. arXiv preprint arXiv:1701.06659, 2017. 3[4] D. Gordon, A. Kembhavi, M. Rastegari, J. Redmon, D. Fox, and A. Farhadi. Iqa: Visual question answering in interactive environments. arXiv preprint arXiv:1712.03316, 2017. 1[5] K. He, X. Zhang, S. Ren, and J. Sun. Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 770–778, 2016. 3[6] J. Huang, V. Rathod, C. Sun, M. Zhu, A. Korattikara, A. Fathi, I. Fischer, Z.Wojna, Y. Song, S. Guadarrama, et al. Speed/accuracy trade-offs for modern convolutional object detectors. 3[7] I. Krasin, T. Duerig, N. Alldrin, V. Ferrari, S. Abu-El-Haija, A. Kuznetsova, H. Rom, J. Uijlings, S. Popov, A. Veit, S. Belongie, V. Gomes, A. Gupta, C. Sun, G. Chechik, D. Cai, Z. Feng, D. Narayanan, and K. Murphy. Openimages: A public dataset for large-scale multi-label and multi-class image classification. Dataset available fromhttps://github.com/openimages, 2017. 2[8] T.-Y. Lin, P. Dollar, R. Girshick, K. He, B. Hariharan, and S. Belongie. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 2117–2125, 2017. 2, 3[9] T.-Y. Lin, P. Goyal, R. Girshick, K. He, and P. Doll´ar. Focal loss for dense object detection. arXiv preprint arXiv:1708.02002, 2017. 1, 3, 4[10] T.-Y. Lin, M. Maire, S. Belongie, J. Hays, P. Perona, D. Ramanan, P. Doll´ar, and C. L. Zitnick. Microsoft coco: Common objects in context. In European conference on computer vision, pages 740–755. Springer, 2014. 2[11] W. Liu, D. Anguelov, D. Erhan, C. Szegedy, S. Reed, C.- Y. Fu, and A. C. Berg. Ssd: Single shot multibox detector. In European conference on computer vision, pages 21–37. Springer, 2016. 3[12] I. Newton. Philosophiae naturalis principia mathematica. William Dawson & Sons Ltd., London, 1687. 1[13] J. Parham, J. Crall, C. Stewart, T. Berger-Wolf, and D. Rubenstein. Animal population censusing at scale with citizen science and photographic identification. 2017. 4[14] J. Redmon. Darknet: Open source neural networks in c. http://pjreddie.com/darknet/, 2013–2016. 3[15] J. Redmon and A. Farhadi. Yolo9000: Better, faster, stronger. In Computer Vision and Pattern Recognition (CVPR), 2017 IEEE Conference on, pages 6517–6525. IEEE, 2017. 1, 2, 3[16] J. Redmon and A. Farhadi. Yolov3: An incremental improvement. arXiv, 2018. 4[17] S. Ren, K. He, R. Girshick, and J. Sun. Faster r-cnn: Towards real-time object detection with region proposal networks. arXiv preprint arXiv:1506.01497, 2015. 2[18] O. Russakovsky, L.-J. Li, and L. Fei-Fei. Best of both worlds: human-machine collaboration for object annotation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 2121–2131, 2015. 4[19] M. Scott. Smart camera gimbal bot scanlime:027, Dec 2017. 4[20] A. Shrivastava, R. Sukthankar, J. Malik, and A. Gupta. Beyond skip connections: Top-down modulation for object detection. arXiv preprint arXiv:1612.06851, 2016. 3[21] C. Szegedy, S. Ioffe, V. Vanhoucke, and A. A. Alemi. Inception-v4, inception-resnet and the impact of residual connections on learning. 2017. 3参考资料目标检测经典论文——YOLOv3论文翻译(纯中文版):YOLOv3:增量式的改进(YOLOv3: An Incremental Improvement):https://blog.csdn.net/Jwenxue/article/details/107749323?ops_request_misc=%25257B%252522request%25255Fid%252522%25253A%252522161268258716780274122037%252522%25252C%252522scm%252522%25253A%25252220140713.130102334.pc%25255Fblog.%252522%25257D&request_id=161268258716780274122037&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~blog~first_rank_v1~rank_blog_v1-12-107749323.pc_v1_rank_blog_v1&utm_term=YOLO
-
YOLOv3学习:(二)网络结构推导与实现 YOLOv3学习:(二)网络结构推导与实现网络结构图简版:网络结构图简版+特征图的大小变换:网络结构-详细版网络结构模块化网络结构图展开(超详细版)网络结构+示例-3D版(利用多尺度特征进行对象检测)9种尺度的先验框随着输出的特征图的数量和尺度的变化,先验框的尺寸也需要相应的调整。YOLO2已经开始采用K-means聚类得到先验框的尺寸,YOLO3延续了这种方法,为每种下采样尺度设定3种先验框,总共聚类出9种尺寸的先验框。在COCO数据集这9个先验框是:(10x13),(16x30),(33x23),(30x61),(62x45),(59x119),(116x90),(156x198),(373x326)。分配上,在最小的1313特征图上(有最大的感受野)应用较大的先验框(116x90),(156x198),(373x326),适合检测较大的对象。中等的2626特征图上(中等感受野)应用中等的先验框(30x61),(62x45),(59x119),适合检测中等大小的对象。较大的52*52特征图上(较小的感受野)应用较小的先验框(10x13),(16x30),(33x23),适合检测较小的对象。感受一下9种先验框的尺寸,下图中蓝色框为聚类得到的先验框。黄色框式ground truth,红框是对象中心点所在的网格。输入到输出的映射(包含输出参数的解释)不考虑神经网络结构细节的话,总的来说,对于一个输入图像,YOLO3将其映射到3个尺度的输出张量,代表图像各个位置存在各种对象的概率。我们看一下YOLO3共进行了多少个预测。对于一个416416的输入图像,在每个尺度的特征图的每个网格设置3个先验框,总共有 13133 + 26263 + 5252*3 = 10647 个预测。每一个预测是一个(4+1+80)=85维向量,这个85维向量包含边框坐标(4个数值),边框置信度(1个数值),对象类别的概率(对于COCO数据集,有80种对象)。对比一下,YOLO2采用13135 = 845个预测,YOLO3的尝试预测边框数量增加了10多倍,而且是在不同分辨率上进行,所以mAP以及对小物体的检测效果有一定的提升。代码实现代码import torch import torch.nn as nn # Darknet53 中的基本块--卷积块,由Conv+BN+LeakyReLU共同组成 class ConvBNReLU(nn.Module): def __init__(self,in_channels,out_channels,kernel_size,stride,padding): super(ConvBNReLU,self).__init__() self.conv = nn.Conv2d(in_channels,out_channels,kernel_size,stride,padding) self.BN = nn.BatchNorm2d(out_channels) self.leaky_relu = nn.ReLU6(inplace=True) def forward(self,x): x = self.conv(x) x = self.BN(x) x = self.leaky_relu(x) return x # Darknet53 中的基本块--下采样块,用卷积(stride=2)实现 class DownSample(nn.Module): def __init__(self,in_channels,out_channels): super(DownSample,self).__init__() self.down_samp = nn.Conv2d(in_channels,out_channels,3,2,1) def forward(self,x): x = self.down_samp(x) return x # Darknet53 中的基本块--ResBlock class ResBlock(nn.Module): def __init__(self, nchannels): super(ResBlock, self).__init__() mid_channels = nchannels // 2 self.conv1x1 = ConvBNReLU(nchannels, mid_channels,1,1,0) self.conv3x3 = ConvBNReLU(mid_channels, nchannels,3,1,1) def forward(self, x): out = self.conv3x3(self.conv1x1(x)) return out + x # YOLOv3 骨干网络 -DarkNet53 class DarkNet53_YOLOv3(nn.Module): def __init__(self): super(DarkNet53_YOLOv3, self).__init__() self.conv_bn_relu = ConvBNReLU(3,32,3,1,1) self.down_samp_0 = DownSample(32,64) self.res_block_1 = ResBlock(64) self.down_samp_1 = DownSample(64,128) self.res_block_2 = ResBlock(128) self.down_samp_2 = DownSample(128,256) self.res_block_3 = ResBlock(256) self.down_samp_3 = DownSample(256,512) self.res_block_4 = ResBlock(512) self.down_samp_4 = DownSample(512,1024) self.res_block_5 = ResBlock(1024) def forward(self, x): out1 = self.conv_bn_relu(x) out1 = self.down_samp_0(out1) out1 = self.res_block_1(out1) out1 = self.down_samp_1(out1) out1 = self.res_block_2(out1) out1 = self.res_block_2(out1) out1 = self.down_samp_2(out1) out1 = self.res_block_3(out1) out1 = self.res_block_3(out1) out1 = self.res_block_3(out1) out1 = self.res_block_3(out1) out1 = self.res_block_3(out1) out1 = self.res_block_3(out1) out1 = self.res_block_3(out1) out1 = self.res_block_3(out1) out1 = self.res_block_3(out1) out2 = self.down_samp_3(out1) out2 = self.res_block_4(out2) out2 = self.res_block_4(out2) out2 = self.res_block_4(out2) out2 = self.res_block_4(out2) out2 = self.res_block_4(out2) out2 = self.res_block_4(out2) out2 = self.res_block_4(out2) out2 = self.res_block_4(out2) out2 = self.res_block_4(out2) out3 = self.down_samp_4(out2) out3 = self.res_block_5(out3) out3 = self.res_block_5(out3) out3 = self.res_block_5(out3) out3 = self.res_block_5(out3) out3 = self.res_block_5(out3) return out1,out2,out3 # YOLOv3 13*13 输出分支的darknet53后的几层 class Out1LastLayers(nn.Module): #input_shape = (1024, 13, 13) out_shape = (255,13,13) out_branck_shape = (512,13,13) def __init__(self): super(Out1LastLayers, self).__init__() self.conv1x1 = ConvBNReLU(1024,512,1,1,0) self.conv3x3 = ConvBNReLU(512, 1024,3,1,1) self.conv1x1_last = ConvBNReLU(1024,255,1,1,0) def forward(self,x): out = self.conv1x1(x) out = self.conv3x3(out) out = self.conv1x1(out) out = self.conv3x3(out) out = self.conv1x1(out) out_branch = out out = self.conv3x3(out) out = self.conv1x1_last(out) return out,out_branch # YOLOv3 26*26 输出分支的darknet53后的几层 class Out2LastLayers(nn.Module): #input_shape = (512, 26, 26) out_shape = (255,26,26) out_branck_shape = (256,26,26) def __init__(self): super(Out2LastLayers, self).__init__() self.conv1x1 = ConvBNReLU(512,256,1,1,0) self.conv3x3 = ConvBNReLU(256,512,3,1,1) self.up_sample = nn.Upsample(scale_factor=2, mode='nearest') self.conv1x1_after_concat = ConvBNReLU(768,256,1,1,0) self.conv1x1_last = ConvBNReLU(512,255,1,1,0) def forward(self,x,x_branch): out = self.conv1x1(x_branch) out = self.up_sample(out) out = torch.cat([x,out],1) out = self.conv1x1_after_concat(out) out = self.conv3x3(out) out = self.conv1x1(out) out = self.conv3x3(out) out = self.conv1x1(out) out_branch = out out = self.conv3x3(out) out = self.conv1x1_last(out) return out,out_branch # YOLOv3 52*52 输出分支的darknet53后的几层 class Out3LastLayers(nn.Module): #input_shape = (256, 52, 52) out_shape = (255,52,52) def __init__(self): super(Out3LastLayers, self).__init__() self.conv1x1 = ConvBNReLU(256,128,1,1,0) self.conv3x3 = ConvBNReLU(128,256,3,1,1) self.up_sample = nn.Upsample(scale_factor=2, mode='nearest') self.conv1x1_after_concat = ConvBNReLU(384,128,1,1,0) self.conv1x1_last = ConvBNReLU(256,255,1,1,0) def forward(self,x,x_branch): out = self.conv1x1(x_branch) out = self.up_sample(out) out = torch.cat([x,out],1) out = self.conv1x1_after_concat(out) out = self.conv3x3(out) out = self.conv1x1(out) out = self.conv3x3(out) out = self.conv1x1(out) out = self.conv3x3(out) out = self.conv1x1_last(out) return out # YOLOv3模型 class YOLOv3(nn.Module): def __init__(self): super(YOLOv3, self).__init__() self.darknet53 = DarkNet53_YOLOv3() self.out1_last_layers = Out1LastLayers() self.out2_last_layers = Out2LastLayers() self.out3_last_layers = Out3LastLayers() def forward(self, x): out3,out2,out1 = self.darknet53(x) # out1.shape,out2.shape,out3.shape = (256, 52, 52),(512, 26, 26),(1024, 13, 13) out1,out1_branch = self.out1_last_layers(out1) out2,out2_branch = self.out2_last_layers(out2,out1_branch) out3 = self.out3_last_layers(out3,out2_branch) return out1,out2,out3输入输出测试fake_input = torch.zeros((1,3,416,416)) print(fake_input.shape) model = YOLOv3() out1,out2,out3= model(fake_input) print(out1.shape,out2.shape,out3.shape)torch.Size([1, 3, 416, 416]) torch.Size([1, 255, 13, 13]) torch.Size([1, 255, 26, 26]) torch.Size([1, 255, 52, 52])参考资料YOLOv3网络结构和解析:https://blog.csdn.net/dz4543/article/details/90049377Darknet53网络各层参数详解:https://blog.csdn.net/qq_40210586/article/details/106144197目标检测0-02:YOLO V3-网络结构输入输出解析:https://blog.csdn.net/weixin_43013761/article/details/98349080YOLOv3 深入理解:https://www.jianshu.com/p/d13ae1055302
-
YOLOv3学习:(一)Darknet-53结构推导与实现 YOLOv3学习:(一)Darknet-53结构推导与实现原生Darknet-53网络结构代码实现-1(更易读)模型代码import torch import torch.nn as nn # Darknet53 中的基本块--卷积块,由Conv+BN+LeakyReLU共同组成 class ConvBNReLU(nn.Module): def __init__(self,in_channels,out_channels,kernel_size,stride,padding): super(ConvBNReLU,self).__init__() self.conv = nn.Conv2d(in_channels,out_channels,kernel_size,stride,padding) self.BN = nn.BatchNorm2d(out_channels) self.leaky_relu = nn.ReLU6(inplace=True) def forward(self,x): x = self.conv(x) x = self.BN(x) x = self.leaky_relu(x) return x # Darknet53 中的基本块--下采样块,用卷积(stride=2)实现 class DownSample(nn.Module): def __init__(self,in_channels,out_channels): super(DownSample,self).__init__() self.down_samp = nn.Conv2d(in_channels,out_channels,3,2,1) def forward(self,x): x = self.down_samp(x) return x # Darknet53 中的基本块--ResBlock class ResBlock(nn.Module): def __init__(self, nchannels): super(ResBlock, self).__init__() mid_channels = nchannels // 2 self.conv1x1 = ConvBNReLU(nchannels, mid_channels,1,1,0) self.conv3x3 = ConvBNReLU(mid_channels, nchannels,3,1,1) def forward(self, x): out = self.conv3x3(self.conv1x1(x)) return out + x num_classes=1000 darknet53= nn.Sequential() darknet53.add_module('conv_bn_relu',ConvBNReLU(3,32,3,1,1)) darknet53.add_module('down_samp_0',DownSample(32,64)) darknet53.add_module('res_block_1_1',ResBlock(64)) darknet53.add_module('down_samp_1',DownSample(64,128)) darknet53.add_module('res_block_2_1',ResBlock(128)) darknet53.add_module('res_block_2_2',ResBlock(128)) darknet53.add_module('down_samp_2',DownSample(128,256)) darknet53.add_module('res_block_3_1',ResBlock(256)) darknet53.add_module('res_block_3_2',ResBlock(256)) darknet53.add_module('res_block_3_3',ResBlock(256)) darknet53.add_module('res_block_3_4',ResBlock(256)) darknet53.add_module('res_block_3_5',ResBlock(256)) darknet53.add_module('res_block_3_6',ResBlock(256)) darknet53.add_module('res_block_3_7',ResBlock(256)) darknet53.add_module('res_block_3_8',ResBlock(256)) darknet53.add_module('down_samp_3',DownSample(256,512)) darknet53.add_module('res_block_4_1',ResBlock(512)) darknet53.add_module('res_block_4_2',ResBlock(512)) darknet53.add_module('res_block_4_3',ResBlock(512)) darknet53.add_module('res_block_4_4',ResBlock(512)) darknet53.add_module('res_block_4_5',ResBlock(512)) darknet53.add_module('res_block_4_6',ResBlock(512)) darknet53.add_module('res_block_4_7',ResBlock(512)) darknet53.add_module('res_block_4_8',ResBlock(512)) darknet53.add_module('down_samp_4',DownSample(512,1024)) darknet53.add_module('res_block_5_1',ResBlock(1024)) darknet53.add_module('res_block_5_2',ResBlock(1024)) darknet53.add_module('res_block_5_3',ResBlock(1024)) darknet53.add_module('res_block_5_4',ResBlock(1024)) darknet53.add_module('avg_pool',nn.AvgPool2d(kernel_size=8,stride=1)) darknet53.add_module('flatten',nn.Flatten()) darknet53.add_module('linear',nn.Linear(in_features=1024,out_features=num_classes)) darknet53.add_module('softmax',nn.Softmax(dim=1)) print(darknet53)输入输出验证fake_imput = torch.zeros((1,3,256,256)) print(fake_imput.shape) output = darknet53(fake_imput) print(output.shape)torch.Size([1, 3, 256, 256]) torch.Size([1, 1000])代码实现-2(代码更少)import torch import torch.nn as nn def Conv3x3BNReLU(in_channels,out_channels,stride=1): return nn.Sequential( nn.Conv2d(in_channels=in_channels,out_channels=out_channels,kernel_size=3,stride=stride,padding=1), nn.BatchNorm2d(out_channels), nn.ReLU6(inplace=True) ) def Conv1x1BNReLU(in_channels,out_channels): return nn.Sequential( nn.Conv2d(in_channels=in_channels,out_channels=out_channels,kernel_size=1,stride=1,padding=0), nn.BatchNorm2d(out_channels), nn.ReLU6(inplace=True) ) class Residual(nn.Module): def __init__(self, nchannels): super(Residual, self).__init__() mid_channels = nchannels // 2 self.conv1x1 = Conv1x1BNReLU(in_channels=nchannels, out_channels=mid_channels) self.conv3x3 = Conv3x3BNReLU(in_channels=mid_channels, out_channels=nchannels) def forward(self, x): out = self.conv3x3(self.conv1x1(x)) return out + x class Darknet53(nn.Module): def __init__(self, num_classes=1000): super(Darknet53, self).__init__() self.first_conv = Conv3x3BNReLU(in_channels=3, out_channels=32) self.block1 = self._make_layers(in_channels=32,out_channels=64, block_num=1) self.block2 = self._make_layers(in_channels=64,out_channels=128, block_num=2) self.block3 = self._make_layers(in_channels=128,out_channels=256, block_num=8) self.block4 = self._make_layers(in_channels=256,out_channels=512, block_num=8) self.block5 = self._make_layers(in_channels=512,out_channels=1024, block_num=4) self.avg_pool = nn.AvgPool2d(kernel_size=8,stride=1) self.linear = nn.Linear(in_features=1024,out_features=num_classes) self.softmax = nn.Softmax(dim=1) def _make_layers(self, in_channels,out_channels, block_num): _layers = [] _layers.append(Conv3x3BNReLU(in_channels=in_channels, out_channels=out_channels, stride=2)) for _ in range(block_num): _layers.append(Residual(nchannels=out_channels)) return nn.Sequential(*_layers) def forward(self, x): x = self.first_conv(x) x = self.block1(x) x = self.block2(x) x = self.block3(x) x = self.block4(x) x = self.block5(x) x = self.avg_pool(x) x = x.view(x.size(0),-1) x = self.linear(x) out = self.softmax(x) return x model = Darknet53() print(model) input = torch.randn(1,3,256,256) out = model(input) print(out.shape)YOLOv3中的Darknet53的网络各层参数详解参考资料Pytorch实现Darknet-53:https://blog.csdn.net/qq_41979513/article/details/102680028Darknet53网络各层参数详解:https://blog.csdn.net/qq_40210586/article/details/106144197
-
【YOLOv2论文翻译】YOLO9000:更好、更快、更强 【YOLOv2论文翻译】YOLO9000:更好、更快、更强论文原文:YOLO9000:Better, Faster, Stronger项目主页:YOLO: Real-Time Object Detection摘要我们引入了一个先进的实时目标检测系统YOLO9000,可以检测超过9000个目标类别。首先,我们提出了对YOLO检测方法的各种改进,既有新发明的一些东西,也参考了前人的工作。改进后的模型YOLOv2在PASCAL VOC和COCO等标准检测任务上性能是最好的。使用一种新颖的、多尺度训练方法,同样的YOLOv2模型可以以不同的尺度运行,从而在速度和准确性之间获得了良好的权衡。以67FPS的检测速度,YOLOv2在VOC 2007上获得了76.8 mAP。而检测速度40FPS时,YOLOv2获得了78.6 mAP,比使用ResNet的Faster R-CNN和SSD等先进方法表现更出色,同时仍然运行速度显著更快。最后我们提出了一种联合训练目标检测与分类的方法。使用这种方法,我们在COCO检测数据集和ImageNet分类数据集上同时训练YOLO9000。我们的联合训练允许YOLO9000预测未标注的检测数据目标类别的检测结果。我们在ImageNet检测任务上验证了我们的方法。YOLO9000在ImageNet检测验证集上获得19.7 mAP,尽管200个类别中只有44个具有检测数据。不在COCO中的156个类别上,YOLO9000获得16.0 mAP。但YOLO可以检测到200多个类别;它预测超过9000个不同目标类别的检测结果。并且它仍然能实时运行。1. 引言通用目的的目标检测系统应该是快速的、准确的,并且能够识别各种各样的目标。自从引入神经网络以来,检测框架变得越来越快速和准确。但是,大多数检测方法仍然受限于一小部分目标。与分类和标记等其他任务的数据集相比,目前目标检测数据集是有限的。最常见的检测数据集包含成千上万到数十万张具有成百上千个标签的图像3[2]。分类数据集有数以百万计的图像,数十或数十万个类别20。我们希望检测能够扩展到目标分类的级别。但是,标注检测图像要代价比标注分类或贴标签要大得多(标签通常是用户免费提供的)。因此,我们不太可能在近期内看到与分类数据集相同规模的检测数据集。我们提出了一种新的方法来利用我们已经拥有的大量分类数据,并用它来扩大当前检测系统的范围。我们的方法使用目标分类的分层视图,允许我们将不同的数据集组合在一起。我们还提出了一种联合训练算法,使我们能够在检测和分类数据上训练目标检测器。我们的方法利用有标签的检测图像来学习精确定位物体,同时使用分类图像来增加词表和鲁棒性。使用这种方法我们训练YOLO9000,一个实时的目标检测器,可以检测超过9000种不同的目标类别。首先,我们改进YOLO基础检测系统,产生最先进的实时检测器YOLOv2。然后利用我们的数据集组合方法和联合训练算法对来自ImageNet的9000多个类别以及COCO的检测数据训练了一个模型。我们的所有代码和预训练模型都可以在http://pjreddie.com/yolo9000/在线获得。2. 更好与最先进的检测系统相比,YOLO有许多缺点。YOLO与Fast R-CNN的误差分析比较表明,YOLO存在大量的定位误差。此外,与基于region proposal的方法相比,YOLO召回率相对较低。因此,我们主要侧重于提高召回率和改进目标精确定位,同时保持分类准确性。计算机视觉一般趋向于更大、更深的网络6[17]。更好的性能通常取决于训练更大的网络或将多个模型组合在一起。但是,在YOLOv2中,我们需要一个更精确的检测器,而且需要它仍然很快。我们不是扩大我们的网络,而是简化网络,然后让表示更容易学习。我们将过去的工作与我们自己的新概念汇集起来,以提高YOLO的性能。表2列出了结果总结。批归一化。会获得收敛性的显著改善,同时消除了对其他形式正则化的需求[7]。通过在YOLO的所有卷积层上添加批归一化,我们在mAP中获得了超过2%的改进。批归一化也有助于模型正则化。通过批归一化,我们可以从模型中删除dropout而不会过拟合。高分辨率分类器。有最先进的检测方法都使用在ImageNet[16]上预训练的分类器。从AlexNet开始,大多数分类器对小于256×256[8]的输入图像进行操作。YOLO初始版本以224×224分辨率的图像训练分类器网络,并在检测时将分辨率提高到448。这意味着网络必须同时切换到学习目标检测和调整到新的输入分辨率。对于YOLOv2,我们首先在ImageNet上以448×448的分辨率对分类网络进行10个迭代周期的fine tune。这使得网络来调整其卷积核以便更好地处理更高分辨率的输入。然后我们对得到的网络进行fine tune并用于检测任务。这个高分辨率分类网络使我们增加了近4%的mAP。具有Anchor框的卷积。YOLO直接使用卷积特征提取器顶部的全连接层来预测边界框的坐标。Faster R-CNN使用手动选择的先验来预测边界框而不是直接预测坐标[15]。Faster R-CNN中的region proposal网络(RPN)仅使用卷积层来预测Anchor框的偏移和置信度。由于预测层是卷积类型的层,所以RPN在特征图的每个位置上预测这些偏移。预测偏移而不是坐标简化了问题,并且使网络更容易学习。我们从YOLO中移除全连接层,并使用Anchor框来预测边界框。首先,我们去除了一个池化层,使网络卷积层输出具有更高的分辨率。我们还缩小了网络,操作416×416的输入图像而不是448×448。我们这样做是因为我们要在我们的特征图中位置个数是奇数,所以只会有一个中心格子。目标,特别是大目标,往往占据图像的中心,所以在中心有一个单独的位置来预测这些目标的很好的,而不是四个都相邻的位置。YOLO的卷积层将图像下采样32倍,所以通过使用416的输入图像,我们得到了13×13的输出特征图。当我们移动到Anchor框时,我们也将类预测机制与空间位置分离,预测每个Anchor框的类别和目标。与YOLO类似,是否为目标的预测仍然预测了真值和proposal的边界框的IOU,并且类别预测预测了当存在目标时该类别的条件概率。使用Anchor框,我们的精度发生了一些小的下降。YOLO对每张图像只预测98个边界框,但是使用Anchor框我们的模型预测超过一千个。如果不使用Anchor框,我们的中间模型将获得69.5的mAP,召回率为81%。使用Anchor框的模型得到了69.2 mAP,召回率为88%。尽管mAP下降了一点,但召回率的上升意味着我们的模型有更大的改进空间。维度聚类。当Anchor框与YOLO一起使用时,我们遇到了两个问题。首先是边界框尺寸是手工挑选的。网络可以学习到如何适当调整边界框,但如果我们为网络选择更好的先验,我们可以使网络更容易学习它以便获得更好的检测结果。我们不用手工选择先验,而是在训练集边界框上运行k-means聚类,自动找到好的先验。如果我们使用欧式距离的标准k-means,那么较大的边界框比较小的边界框产生更多的误差。然而,我们真正想要的是产生好的IOU分数的先验,这是独立于边界框大小的。因此,对于我们的距离度量,我们使用:d(box,centroid)=1−IOU(box,centroid)如图2所示,我们运行不同k值的k-means,并画出平均IOU与最接近的几何中心的关系图。我们选择k=5时模型复杂性和高召回率之间的具有良好的权衡。聚类中心与手工挑选的Anchor框明显不同。聚类结果有更短更宽的边界框,也有更高更细的边界框。在表1中我们将平均IOU与我们聚类策略中最接近的先验以及手工选取的Anchor框进行了比较。仅有5个先验中心的平均IOU为61.0,其性能类似于9个Anchor框的60.9。如果我们使用9个中心,我们会看到更高的平均IOU。这表明使用k-means来生成我们的边界框会以更好的表示开始训练模型,并使得任务更容易学习。直接定位预测。当YOLO使用Anchor框时,我们会遇到第二个问题:模型不稳定,特别是在早期的迭代过程中。大部分的不稳定来自预测边界框的(x,y)位置。在region proposal网络中,网络预测值tx和ty,(x, y)中心坐标计算如下:例如,预测tx=1会将边界框向右移动Anchor框的宽度,预测tx=−1会将其向左移动相同的宽度。这个公式是不受限制的,所以任何Anchor框都可以在图像任一点结束,而不管在哪个位置预测该边界框。随机初始化模型需要很长时间才能稳定以预测合理的偏移量。我们没有预测偏移量,而是按照YOLO的方法预测相对于网格单元位置的位置坐标。这使得真值落到了0和1之间。我们使用logistic激活函数来限制网络的预测值落在这个范围内。网络预测输出特征图中每个格子的5个边界框。网络预测每个边界框的5个坐标,tx、ty、tw、th和to。如果格子相对于图像的左上角偏移量为(cx, cy),边界框先验的宽度和高度为pw, ph,那么预测结果对应为:由于我们限制位置预测参数化更容易学习,使网络更稳定。使用维度聚类以及直接预测边界框中心位置的方式比使用Anchor框的版本将YOLO提高了近5%。细粒度特征。这个修改后的YOLO在13×13特征图上预测检测结果。虽然这对于大型目标来说已经足够了,但它通过更细粒度的特征定位出更小的目标。Faster R-CNN和SSD都在网络的各种特征图上运行他们提出的网络,以获得一系列的分辨率。我们采用不同的方法,仅仅添加一个passthrough层,从26x26分辨率的更早层中提取特征。passthrough层通过将相邻特征堆叠到不同的通道而不是空间位置来连接较高分辨率特征和较低分辨率特征,类似于ResNet中的恒等映射。将26×26×512特征图变成13×13×2048特征图(译者注:如何将26×26×512变成13×13×2048?26×26×512首先变成4个13×13×512,然后在通道方向上将4个拼接在一起就成了13×13×2048),其可以与原始特征连接。我们的检测器运行在这个扩展的特征图之上,以便它可以访问细粒度的特征。这会使性能提高1%。多尺度训练。原来的YOLO使用448×448的输入分辨率。通过添加Anchor框,我们将分辨率更改为416×416。但是,由于我们的模型只使用卷积层和池化层,因此它可以动态调整大小。我们希望YOLOv2能够鲁棒地运行在不同大小的图像上,因此我们可以将该特性训练到模型中。我们没有固定输入图像的大小,而是每隔几次迭代就改变网络。每隔10个批次我们的网络会随机选择一个新的图像尺寸大小。由于我们的模型缩减了32倍,我们从下面的32的倍数中选择:{320,352,…,608}。因此最小的是320×320,最大的是608×608。我们将网络调整到这些尺寸并继续训练。这个模型架构迫使网络学习如何在各种输入维度上完成较好的预测。这意味着相同的网络可以预测不同分辨率下的检测结果。在更小尺寸上网络运行速度更快,因此YOLOv2在速度和准确性之间得到了一个简单的折衷。分辨率较低时YOLOv2可以作为一个低成本、相当准确的检测器。在288×288时,其运行速度超过90FPS,mAP与Fast R-CNN差不多。这使其成为小型GPU、高帧率视频或多视频流的理想选择。在高分辨率下,YOLOv2是VOC 2007上最先进的检测器,mAP达到了78.6,同时能够保持实时检测的速度要求。如表3所示为YOLOv2与其他框架在VOC 2007上的比较。图4进一步实验。我们在VOC 2012上训练YOLOv2检测模型。表4所显为YOLOv2与其他最先进的检测系统性能比较的结果。YOLOv2取得了73.4 mAP的同时运行速度比比对方法快的多。我们在COCO上进行了训练,并与表5中其他方法进行比较。在VOC指标(IOU = 0.5)上,YOLOv2得到44.0 mAP,与SSD和Faster R-CNN相当。![表5:在COCO test-dev2015数据集上的结果。表改编自[11]](/usr/uploads/auto_save_image/f017206828388e0fedf5e4b4cd5b27c6.png)3. 更快我们不仅希望检测是准确的,而且我们还希望它速度也快。大多数检测应用(如机器人或自动驾驶机车)依赖于低延迟预测。为了最大限度提高性能,我们从头开始设计YOLOv2。大多数检测框架依赖于VGG-16作为的基础特征提取器[17]。VGG-16是一个强大的、准确的分类网络,但它有些过于复杂。在单张图像224×224分辨率的情况下,VGG-16的卷积层运行一次前向传播需要306.90亿次浮点运算。YOLO框架使用基于GoogLeNet架构[19]的自定义网络。这个网络比VGG-16更快,一次前向传播只有85.2亿次的计算操作。然而,它的准确性比VGG-16略差(译者注:ILSVRC2014竞赛中GoogLeNet获得分类任务第一名,VGG第二名,但是在定位任务中VGG是第一名)。在ImageNet上,对于单张裁剪图像,224×224分辨率下的top-5准确率,YOLO的自定义模型获得了88.0%,而VGG-16则为90.0%。Darknet-19。我们提出了一个新的分类模型作为YOLOv2的基础。我们的模型建立在网络设计先前工作以及该领域常识的基础上。与VGG模型类似,我们大多使用3×3卷积核,并在每个池化步骤之后使得通道数量加倍[17]。按照Network in Network(NIN)的工作,我们使用全局平均池化的结果做预测,并且使用1×1卷积核来压缩3×3卷积之间的特征表示[9]。我们使用批归一化来稳定训练、加速收敛,并正则化模型[7]。我们的最终模型叫做Darknet-19,它有19个卷积层和5个最大池化层。完整描述请看表6。Darknet-19只需要55.8亿次运算来处理图像,但在ImageNet上却达到了72.9%的top-1准确率和91.2%的top-5准确率。分类训练。我们使用Darknet神经网络结构,使用随机梯度下降、初始学习率为0.1、学习率多项式衰减系数为4、权重衰减为0.0005、动量为0.9,在标准ImageNet 1000类分类数据集上训练网络160个迭代周期[13]。在训练过程中,我们使用标准的数据增强技巧,包括随机裁剪、旋转、以及色调、饱和度和曝光的改变。如上所述,在我们对224×224的图像进行初始训练之后,我们对网络在更大的尺寸448上进行了fine tune。对于这种fine tune,我们使用上述参数进行训练,但是只有10个迭代周期,并且以10−3的学习率开始(译者注:fine-tune时通常会使用较低的学习率)。在这种更高的分辨率下,我们的网络达到了76.5%的top-1准确率和93.3%的top-5准确率。检测训练。我们修改这个网络使得可以用于检测任务,删除了最后一个卷积层,加上了三层具有1024个卷积核的3×3卷积层,每层后面接1×1卷积层,卷积核数量与我们检测输出数量一致。对于VOC,我们预测5个边界框,每个边界框有5个坐标和20个类别,所以有125个卷积核。我们还添加了从最后的3×3×512层到倒数第二层卷积层的直通层,以便我们的模型可以使用细粒度特征。我们训练网络160个迭代周期,初始学习率为10−3,在60个和90个迭代周期时将学习率除以10。我们使用0.0005的权重衰减和0.9的动量。我们对YOLO和SSD进行类似的数据增强:随机裁剪、色彩改变等。我们对COCO和VOC使用相同的训练策略。4. 更强我们提出了一个联合训练分类和检测数据的机制。我们的方法使用标记为检测的图像来学习边界框坐标预测和目标之类的特定检测信息以及如何对常见目标进行分类。它使用仅具有类别标签的图像来扩展可检测类别的数量。在训练期间,我们混合来自检测数据集和分类数据集的图像。当我们的网络看到标记为检测的图像时,我们可以基于完整的YOLOv2损失函数进行反向传播。当它看到一个分类图像时,我们只能从该架构特定的分类部分反向传播损失。这种方法存在一些挑战。检测数据集只有常见目标和通用标签,如“狗”或“船”。分类数据集具有更广更深的标签范围。ImageNet有超过一百种品种的狗,包括Norfolk terrier,Yorkshire terrier和Bedlington terrier。如果我们想在两个数据集上训练,我们需要一个连贯的方式来合并这些标签。大多数分类方法使用跨所有可能类别的softmax层来计算最终的概率分布。使用softmax假定这些类是互斥的。这给数据集的组合带来了问题,例如你不想用这个模型来组合ImageNet和COCO,因为类Norfolk terrier和dog不是互斥的。我们可以改为使用多标签模型来组合不假定互斥的数据集。这种方法忽略了我们已知的关于数据的所有结构,例如,所有的COCO类是互斥的。分层分类。ImageNet标签是从WordNet中提取的,这是一个构建概念及其相互关系的语言数据库[12]。在WordNet中,Norfolk terrier和Yorkshire terrier都是terrier的下义词,terrier是一种hunting dog,hunting dog是dog,dog是canine等。分类的大多数方法假设标签是一个扁平结构,但是对于数据集的组合,结构正是我们所需要的。WordNet的结构是有向图,而不是树,因为语言是复杂的。例如,dog既是一种canine(犬),也是一种domestic animal(家畜),它们都是WordNet中的同义词。我们不是使用完整的图结构,而是通过从ImageNet的概念中构建分层树来简化问题。为了构建这棵树,我们检查了ImageNet中的视觉名词,并查看它们通过WordNet图到根节点的路径,在这种情况下是“物理对象”。许多同义词通过图只有一条路径,所以首先我们将所有这些路径添加到我们的树中。然后我们反复检查我们留下的概念,并尽可能少地添加生长树的路径。所以如果一个概念有两条路径到一个根,一条路径会给我们的树增加三条边,另一条只增加一条边,我们选择更短的路径。最终的结果是WordTree,一个视觉概念的分层模型。为了使用WordTree进行分类,我们预测每个节点的条件概率,以得到同义词集合中每个同义词下义词的概率。例如,在terrier节点我们预测:Pr(Norfolk terrier|terrier)Pr(Yorkshire terrier|terrier)Pr(Bedlington terrier|terrier)...如果我们想要计算一个特定节点的绝对概率,我们只需沿着通过树到达根节点的路径,再乘以条件概率。所以如果我们想知道一张图片是否是Norfolk terrier,我们计算:Pr(Norfolk terrier)=Pr(Norfolk terrier|terrier)*Pr(terrier|hunting dog)…*Pr(mammal|Pr(animal)*Pr(animal|physical object)对于分类任务,我们假定图像只包含一个目标:Pr(physical object)=1。为了验证这种方法,我们在使用1000类ImageNet构建的WordTree上训练Darknet-19模型。为了构建WordTree1k,我们添加了所有将标签空间从1000扩展到1369的中间节点。在训练过程中,我们将真实标签向树上面传播,以便如果图像被标记为Norfolk terrier,则它也被标记为dog和mammal等。为了计算条件概率,我们的模型预测了具有1369个值的向量,并且我们计算了相同概念的下义词在所有同义词集上的softmax,见图5。使用与之前相同的训练参数,我们的分层Darknet-19达到71.9%的top-1准确率和90.4%的top-5准确率。尽管增加了369个额外的概念,而且我们的网络预测了一个树状结构,但我们的准确率仅下降了一点点。以这种方式进行分类也有一些好处。在新的或未知的目标类别上性能不会下降太多。例如,如果网络看到一只狗的照片,但不确定它是什么类型的狗,它仍然会高度自信地预测“狗”,但是扩展到下义词后可能有更低的置信度。这个构想也适用于检测。现在,我们不是假定每张图像都有一个目标,而是使用YOLOv2的目标预测器给我们Pr(physical object)的值。检测器预测边界框和概率树。我们遍历树,在每个分割中采用最高的置信度路径,直到达到某个阈值,然后我们预测目标类。使用WordTree组合数据集。我们可以使用WordTree以合理的方式将多个数据集组合在一起。我们只需将数据集中的类别映射到树中的同义词集(synsets)即可。图6显示了使用WordTree来组合来自ImageNet和COCO的标签的示例。WordNet是非常多样化的,所以我们可以在大多数数据集中使用这种技术。联合分类和检测。现在我们可以使用WordTree组合数据集,我们可以在分类和检测上训练联合模型。我们想要训练一个非常大规模的检测器,所以我们使用COCO检测数据集和完整的ImageNet版本中的前9000个类来创建我们的组合数据集。我们还需要评估我们的方法,因此还添加了ImageNet检测挑战中未包含的类。该数据集的对应的WordTree有9418个类别。ImageNet相比于COCO是一个更大的数据集,所以我们通过对COCO进行过采样来平衡数据集,使得ImageNet仅仅大于4:1的比例。使用这个数据集我们训练YOLO9000。我们使用基础的YOLOv2架构,但只有3个先验(priors)而不是5个来限制输出大小。当我们的网络看到一个检测图像时,我们正常地对损失进行反向传播。对于分类损失,我们仅在等于或高于标签对应的层对损失进行反向传播。例如,如果标签是“狗”,我们将沿着树向下进一步预测“德国牧羊犬”与“金毛猎犬”之间的差异,因为我们没有这些信息。当它看到分类图像时,我们只能反向传播分类损失。要做到这一点,我们只需找到预测该类别最高概率的边界框,然后计算其预测树上的损失。我们还假设预测边界框与真实标签重叠至少0.3的IOU,并且基于这个假设反向传播目标损失。使用这种联合训练,YOLO9000学习使用COCO中的检测数据来查找图像中的目标,并学习使用来自ImageNet的数据对各种目标进行分类。我们在ImageNet检测任务上评估了YOLO9000。ImageNet的检测任务与COCO共有的目标类别有44个,这意味着YOLO9000只能看到大多数测试图像的分类数据,而不是检测数据。YOLO9000在从未见过任何标记的检测数据的情况下,整体上获得了19.7 mAP,在不相交的156个目标类别中获得了16.0 mAP。这个mAP高于DPM的结果,但是YOLO9000在不同的数据集上训练,只有部分监督[4]。它也同时检测9000个其他目标类别,所有的都是实时的。当我们分析YOLO9000在ImageNet上的性能时,我们发现它很好地学习了新的动物种类,但是却在像服装和设备这样的学习类别中效果不好。新动物更容易学习,因为目标预测可以从COCO中的动物泛化的很好。相反,COCO没有任何类型的衣服的边界框标签,只有针对人的检测标签,因此YOLO9000很难建模好“墨镜”或“泳裤”等类别。5. 结论我们介绍了YOLOv2和YOLO9000,两个实时检测系统。YOLOv2在各种检测数据集上都是最先进的,也比其他检测系统更快。此外,它可以运行在各种图像大小,以提供速度和准确性之间的平滑折衷。YOLO9000是一个通过联合优化检测和分类来检测9000多个目标类别的实时框架。我们使用WordTree将各种来源的数据和我们的联合优化技术相结合,在ImageNet和COCO上同时进行训练。YOLO9000是在检测和分类之间缩小数据集大小差距的重要一步。我们的许多技术都可以泛化到目标检测之外。我们对ImageNet的WordTree表示为图像分类提供了更丰富、更详细的输出空间。使用分层分类的数据集组合在分类和分割领域将是有用的。像多尺度训练这样的训练技术可以为各种视觉任务提供益处。对于未来的工作,我们希望使用类似的技术来进行弱监督的图像分割。我们还计划使用更强大的匹配策略来改善我们的检测结果,以在训练期间将弱标签分配给分类数据。计算机视觉需要大量标记的数据。我们将继续寻找方法,将不同来源和数据结构的数据整合起来,形成更强大的视觉世界模型。参考文献[1] S. Bell, C. L. Zitnick, K. Bala, and R. Girshick. Inside-outside net: Detecting objects in context with skip pooling and recurrent neural networks. arXiv preprint arXiv:1512.04143, 2015. 6[2] J. Deng, W. Dong, R. Socher, L.-J. Li, K. Li, and L. Fei- Fei. Imagenet: A large-scale hierarchical image database. In Computer Vision and Pattern Recognition, 2009. CVPR 2009. IEEE Conference on, pages 248–255. IEEE, 2009. 1[3] M. Everingham, L. Van Gool, C. K. Williams, J. Winn, and A. Zisserman. The pascal visual object classes (voc) challenge. International journal of computer vision, 88(2):303– 338, 2010. 1[4] P. F. Felzenszwalb, R. B. Girshick, and D. McAllester. Discriminatively trained deformable part models, release 4. http://people.cs.uchicago.edu/pff/latent-release4/. 8[5] R. B. Girshick. Fast R-CNN. CoRR, abs/1504.08083, 2015. 4, 5, 6[6] K. He, X. Zhang, S. Ren, and J. Sun. Deep residual learning for image recognition. arXiv preprint arXiv:1512.03385, 2015. 2, 4, 5[7] S. Ioffe and C. Szegedy. Batch normalization: Accelerating deep network training by reducing internal covariate shift. arXiv preprint arXiv:1502.03167, 2015. 2, 5[8] A. Krizhevsky, I. Sutskever, and G. E. Hinton. Imagenet classification with deep convolutional neural networks. In Advances in neural information processing systems, pages 1097–1105, 2012. 2[9] M. Lin, Q. Chen, and S. Yan. Network in network. arXiv preprint arXiv:1312.4400, 2013. 5[10] T.-Y. Lin, M. Maire, S. Belongie, J. Hays, P. Perona, D. Ramanan, P. Dollar, and C. L. Zitnick. Microsoft coco: Common objects in context. In European Conference on Computer Vision, pages 740–755. Springer, 2014. 1, 6[11] W. Liu, D. Anguelov, D. Erhan, C. Szegedy, and S. E. Reed. SSD: single shot multibox detector. CoRR, abs/1512.02325, 2015. 4, 5, 6[12] G. A. Miller, R. Beckwith, C. Fellbaum, D. Gross, and K. J. Miller. Introduction to wordnet: An on-line lexical database. International journal of lexicography, 3(4):235–244, 1990. 6[13] J. Redmon. Darknet: Open source neural networks in c. http://pjreddie.com/darknet/, 2013–2016. 5[14] J. Redmon, S. Divvala, R. Girshick, and A. Farhadi. You only look once: Unified, real-time object detection. arXiv preprint arXiv:1506.02640, 2015. 4, 5[15] S. Ren, K. He, R. Girshick, and J. Sun. Faster r-cnn: Towards real-time object detection with region proposal net- works. arXiv preprint arXiv:1506.01497, 2015. 2, 3, 4, 5, 6[16] O. Russakovsky, J. Deng, H. Su, J. Krause, S. Satheesh, S. Ma, Z. Huang, A. Karpathy, A. Khosla, M. Bernstein, A. C. Berg, and L. Fei-Fei. ImageNet Large Scale Visual Recognition Challenge. International Journal of Computer Vision (IJCV), 2015. 2[17] K. Simonyan and A. Zisserman. Very deep convolutional networks for large-scale image recognition. arXiv preprint arXiv:1409.1556, 2014. 2, 5[18] C. Szegedy, S. Ioffe, and V. Vanhoucke. Inception-v4, inception-resnet and the impact of residual connections on learning. CoRR, abs/1602.07261, 2016. 2[19] C. Szegedy, W. Liu, Y. Jia, P. Sermanet, S. Reed, D. Anguelov, D. Erhan, V. Vanhoucke, and A. Rabinovich. Going deeper with convolutions. CoRR, abs/1409.4842, 2014. 5[20] B. Thomee, D. A. Shamma, G. Friedland, B. Elizalde, K. Ni, D. Poland, D. Borth, and L.-J. Li. Yfcc100m: The new data in multimedia research. Communications of the ACM, 59(2):64–73, 2016. 1参考资料目标检测经典论文——YOLOv2论文翻译(纯中文版):YOLO9000:更好、更快、更强:https://blog.csdn.net/jwenxue/article/details/107749188?utm_medium=distribute.pc_relevant.none-task-blog-baidujs_baidulandingword-18&spm=1001.2101.3001.4242
-
【YOLOv1论文翻译】:YOLO: 一体化的,实时的物体检测 【YOLOv1论文翻译】:YOLO: 一体化的,实时的物体检测论文原文:You Only Look Once Unified, Real-Time Object Detection摘要 我们介绍一种新的物体检测方法YOLO。与先前的物体检测方法是重新设置分类器来执行检测不同,我们将物体检测方法看做一个回归问题,去预测空间分离的边界框和相关类别概率。单个神经网络从整个图片中一次性预测边界框和类别概率。由于整个检测流程是一个单一网络,所以可以进行端到端的直接对检测性能进行优化。 我们的这种单一网络结构体系速度非常快。我们的基本YOLO模型实时处理图像速度为每秒45帧。较小的YOLO模型版本,Fast YOLO可以实现每秒155帧的实时检测速度,同时实现mAP是其他物体检测网络的两倍左右。与当前最先进的物体检测方法相比,YOLO会出现较多的定位误差,但是从背景中检测出假阳性目标较少。最后,YOLO可以学习物体非常抽象的特征,所以在自然图像之外的其他检测领域比如艺术品的检测中,YOLO优于包括DPM和R-CNN在内的其他检测方法。1.介绍 人们只需瞥一眼图片就知道图片中有什么物体,物体的位置及它们之间的联系。人类的视觉系统是快速而准确的,使我们可以做很复杂的事,比如开车时不用刻意去思考。快速,准确的物体检测算法将允许计算机在没有专用传感器的情况下驾驶汽车,使辅助设备能够向人类用户传达实时场景信息,并释放通用,响应式机器人系统的潜力。 当前的检测系统重新利用分类器来执行检测。 为了检测物体,这些系统为该物体提供一个分类器,并在不同的位置评估它,并在测试图像中进行缩放。 像可变形零件模型(DPM)这样的系统使用滑动窗口方法,其中分类器在整个图像上以均匀间隔的位置运行[10]。 最近的方法比如R-CNN使用候选区域的方法,首先在图像中生成候选框,然后在候选框上运行分类器。分类之后,后续的操作是优化边界框、消除重复检测,最后根据图像中其他物体来重新定位边界框。这些复杂的流程很慢而且优化困难,因为每个组件都需要单独训练。 我们将物体检测系统,输入图像像素输出边界框坐标和类概率,重新设计为一个回归问题。使用我们的系统,只需运行一次就可以知道图像中有什么物体以及物体的位置。 YOLO非常简单:参考图片1,单个神经网络可以同时预测多个边界框和类概率 ,YOLO直接在整个图像上训练,并直接优化检测性能。这个统一的模型比传统的物体检测方法有几个优势。 第一,YOLO速度非常快。由于我们的检测是当做一个回归问题,不需要很复杂的流程。在测试的时候我们只需将一个新的图片输入网络来检测物体。在Titan X GPU上我们的基本网络检测速度可以实现45帧每秒,快速版本检测速度可以达到155帧每秒。这意味着我们可以以小于25毫秒的延迟处理流媒体视频。此外YOLO相比其他实时检测系统可以达到两倍的mAP,请参阅我们的项目网页http://pjreddie.com/yolo/.,上面有我们项目在网络摄像头上的实时运行演示。 第二,YOLO在预测时可以整体的检测图像。与基于滑动窗口和候选区域的方法不同,在训练和测试期间YOLO可以看到整个图像,所以它隐式的编码相关类的上下文信息及外观。Fast R-CNN是一种顶级的检测方法,由于它无法看到更大的上下文信息所以会从背景中检测出错误的物体,YOLO出现背景误差的概率是Fast R-CNN的一半。 第三,YOLO学习图像的抽象特征。当在自然图像上进行训练,并在艺术品上测试时,YOLO的效果大幅优于DPM和R-CNN等顶级检测方法。由于YOLO是高度抽象化的,所以在应用到新的领域或者有意外输入时不太会出现故障。 YOLO 在检测准确率上仍然大幅落后于最好的检测方法。虽然YOLO可以很快的识别出图像中的物体,但是在精准定位物体尤其是较小的物体位置上还需要更多的努力。我们在实验中正进一步测试如何平衡这些方面。 我们所有的训练和测试代码都是开源的,还提供一些预训练的模型可供下载。2.统一检测 我们将物体检测的单独组件集成到一个神经网络中。我们的网络使用整个图像的特征来预测每个边界框,网络还同时预测所有类的所有边界框,这也就意味着我们的网络全面的预测整个图像和图像中的所有的类。YOLO网络的设计保证能够实现端到端的训练和实时检测的速度,同时实现较高的检测平均精度。 我们的系统将输入图像划分成S × S个网格。如果一个物体的中心点在某个网格中,则这个网格负责检测这个物体。每个网格单元预测B个边界框以及每个边界框的confidence(置信度)。这些confidence反映了网络模型对该边界框是否含有物体的信心,以及边界框位置预测的准确度。 在形式上我们将confidence定义为 C = Pr(Object) ∗ IOU truth pred( Pr(Object)网格存在物体为1,不存在为0),如果网格中不包含物体则Pr(Object) = 0则confidence为0,包含物体Pr(Object) = 1则confidence等于预测边界框和真实边界框的IOU(交并比)。 每个边界框有5个预测值:x,y,w,h,confidence,(x,y)代表预测边界框的中心点坐标,w,h是边界框的宽度和高度,confidence是预测边界框和真实边界框的IOU。 每个网格预测C个条件类别概率, Pr(Class i |Object),这是网格中含有物体的条件下属于某个类别的概率,每个网格只预测一组条件类别概率,B个边界框公用。 测试时我们将条件类概率和confidence相乘,为我们提供了每个边界框在各个类别的得分值 ,这些得分值代表该类别物体出现在框中的概率和边界框与物体的拟合程度。 在PASCAL VOC数据集上评估YOLO,S = 7,B = 2,C = 20(因为PASCAL VOC数据集中有20个标记类) ,我们的最终预测结果是7 × 7 × 30张量。2.1设计 我们将模型以卷积神经网络来实现,在PASCAL VOC数据集上评估。网络的初始卷积层用来提取图像特征,全连接层用来预测类别概率和坐标。 我们的网络结构受到图像分类网络GoogLeNet[34]的启发,我们的网络包括24层卷积层和2层全连接层,不同于GoogLeNet使用的Inception块,我们使用和Lin等人【22】一样的结构,一个1×1卷积层后面跟一个3×3卷积层。完整的网络结构可以查看图片3。 为了加快检测速度我们还训练了一个快速的YOLO版本。Fast YOLO 使用较少的卷积层,9层而不是普通版的24层,和更小的卷积核。除了网络较小,Fast YOLO和YOLO训练和测试参数是一样的。我们的网络最终输出是7 × 7 × 30的预测张量。2.2训练 我们在ImageNet 1000类数据集上预训练我们的卷积层。预训练时我们使用图3中的前20为向量、一个平均池化层、一个全连接层。我们训练这个网络一周时间, 在ImageNet 2012数据集中获得了88%准确率排名位于前5名,与 Caffe上训练的模型中的GoogLeNet模型相当。我们使用 Darknet框架进行所有的训练和预测。 然后我们转化网络执行检测。Ren等人提出在预训练模型中加入卷积层和全连接层可以提高性能[29]。根据他们的想法,我们添加了随机初始化参数的4个卷积层和2个全连接层。检测任务需要细粒度的视觉信息,所以我们将网络输入的分辨率从224×224增加到448×448。 我们在最后一层输出类别概率和边界框坐标。我们通过图像的宽度和高度来标准化边界框的宽度和高度至0到1之间,我们将边界框x和y坐标参数化为相对特定网格的偏移量,使其值处于0到1之间。我们对最后一层使用线性激活函数,其他层使用以下激活函数。 我们使用平方和误差来优化模型。使用平方和误差较容易优化,但是不能完全符合我们最大化平均精度的目标。它将定位误差和分类误差同等对待是不太合理的,而且在图像中有很多网格不包含任何物体,将这些网格的置信度趋向于零时的梯度将会超过含有物体的网格的梯度,这会导致网络不稳定,从而使网络在训练初期就出现梯度爆炸。 为了弥补这一点,我们增加了边界框坐标预测损失的权重,并减少了不包含物体的边界框的置信度预测损失的权重。我们使用两个参数λcoord和λnoobj来完成这个。我们设置λcoord = 5和λnoobj =0 .5。 平方和误差计算损失时将大框和小框同等对待,同样的一个损失值对大框的影响小于对小框的影响。为了解决这个问题,我们计算损失时先对框的宽度和高度求根号再计算平方和。 YOLO为每个网格预测多个边界框。在训练时我们希望每个物体只有一个边界框负责检测这个物体。我们选择和真实物体位置IOU最大的边界框作为负责检测这个物体的边界框。这使得我们的边界框预测变量都负责预测特定物体。所以每个预测变量可以更好地预测边界框尺寸,纵横比或物体类别,从而改善整体召回率。 训练期间我们优化下图中的损失函数: 其中的$1^{obj}_{ij}$代表的是第i个网格中是否含有物体,以及第i个网格中的第j个边界框负责预测这个物体。 请注意,如果网格中含有物体,损失函数只需考虑分类损失(因此条件类概率在前面讲)。如果这个预测器负责预测真实边界框(和网格中的所有预测器都有最高的IOU),损失函数只考虑预测坐标损失。 我们在PASCAL VOC 2007和2012的训练和验证数据集上对网络进行了大约135个epochs的训练。当在VOC 2012上测试的时候,我们也包含了VOC 2007的测试数据用来训练。训练中我们的batch size为64,momentum为0.9,decay为0.0005。 我们的learning rate(学习率)计划如下:在第一个epoch中我们将learning rate慢慢的从0.001提高到0.01,如果我们从较高的学习率开始训练,由于不稳定的梯度会导致网络发散。我们以0.01训练75个epoch,再以0.001训练30个epoch,以0.0001训练30个epoch。 为了避免过拟合我们使用了dropout (神经元随机失效)层和数据增强的办法。在第一个连接层之后,速率为0.5的dropout层防止了层之间的联合性(dropout强迫一个神经单元,和随机挑选出来的其他神经单元共同工作,达到好的效果。消除减弱了神经元节点间的联合适应性,增强了泛化能力。)[18]。对于数据增强,我们引入达到原始图像大小20%的随机缩放和平移。我们还在HSV色彩空间中随机调整图像的曝光和饱和度达1.5倍。2.3前向传播 和训练时一样,在检测测试图像时只需网络执行一次预测。在PASCAL VOC上为每个图像预测98个边界框,每个边界框预测一个置信度得分。不像基于分类器的检测方法,YOLO因为只需运行一个网络,所以执行速度很快。 网格的设计在边界框预测中强制实现空间多样性。通常我们很清楚物体落入哪个网格中,并且模型为每个物体只预测一个边界框。但是,一些比较大的物体或者是在跨越多个网格边界的物体,可以被多个网格都很好的检测出来(即一个物体被多次检测出来造成多重检测问题)。可以使用NMS(非极大值抑制)来解决这种多重检测的问题。虽然NMS对YOLO性能的影响不像对R-CNN、DPM性能影响那么大,但也能提升2-3%的mAP值。2.4 YOLO的局限性 YOLO对边界框预测施加了强烈的空间约束,因为每个网格单元只预测两个框,并且只能有一个类。这种空间约束限制了模型能预测网格附近物体的数量。我们的模型在图像中出现的成群的小物体(比如鸟群)时将会出现物体间的竞争。 由于我们的模型从数据中学习如何预测边界框,因此它遇到新的数据或数据不寻常的高宽比或配置时将较难适应。因为我们的模型在输入图像中有多个下采样层,所以我们的模型是使用相对粗糙的特征来预测边界框。最后,我们在训练一个损失函数不断提高检测性能时,我们将小边框和大边框的损失同等对待。一个较小损失值对较大的边界框来说影响较小,但是对较小的边界框则意味着会极大地影响IOU。我们的误差主要来自检测定位误差。3.与其他检测系统对比 物体检测是计算机视觉领域的核心问题。检测流程通常是从输入图像中提取一组特征开始的(Haar [25], SIFT [23],HOG [4], convolutional features [6]) 。然后分类器[36, 21, 13, 10] 或定位器 [1, 32] 在特征空间中识别物体。这些分类器或定位器在整个图像上或在图像中某些区域子集上以滑动窗口方式运行[35,15,39]。我们将YOLO检测系统与几个顶级检测框架进行了比较,突出了主要的相似点和不同点。 Deformable Parts Model DPM 使用sliding window(滑动窗口)方法执行物体检测[10]。DPM使用不相交的管道来提取静态特征,对区域分类,预测高分边界框等。我们的系统用单个卷积神经网络取代了以上各个部分。网络是同时执行特征提取,边界框预测,非最大抑制和上下文推理这些操作。我们的网络不是静态的,而是在线训练和优化的。我们的网络是统一架构的比DPM速度更快更准确。 R-CNN R-CNN是使用region proposals(候选区域)的方式而不是滑动窗口的方式。Selective Search(选择性搜索)[35]生成候选的边界框,一个卷积网络提取特征,一个SVM给边界框评分,线性模型调整边界框,NMS消除重复检测。需要精确调整复杂的检测管道的每个阶段,这导致训练得到的系统运行缓慢,测试时每张图片耗时超过40s。 YOLO和R-CNN有一些相似之处。每个网格使用卷积特征预测候选框并对其评分。但是我们的系统对网格的预测施加空间限制,这一定程度上减少了重复检测问题。相比R-CNN提出约2000候选框,我们的YOLO提出较少的候选框只有98个。最后,我们整合了这些单独的组件,形成一个单一的同时优化的模型。 其他快速检测系统 Fast 和 Faster R-CNN 专注于通过共享计算和使用网络 候选区域取代选择性搜索来提高R-CNN的速度。虽然它们的速度和准确性都比R-CNN有所提高,但两者仍然达不到实时检测的要求。 许多工作集中在提高DPM速度上[31] [38] [5]。他们通过级联的方式加快HOG计算,并泛华到GPUs上。但是,DPM的实时速度只有30HZ。YOLO不是试图优化复杂的检测管道中的单个组件,而是完全抛出管道,并且设计的运行速度很快。单一类别的检测器比如人脸检测或者人员检测可以得到很好的优化,因为这些任务处理的特征变化较少。YOLO是一种通用的检测器,可以同时检测多种物体。 Deep MultiBox. 与R-CNN不同,Szegedy等人训练一个卷积网络而不是使用选择性搜索来预测感兴趣的区域。MultiBox还可以通过用单个类别预测替换置信预测来执行单个目标检测。但是MultiBox不能执行通用检测,因为它只是复杂管线中的一部分,还需要进一步的图像分类补丁。YOLO和MultiBox都使用卷积网络来预测图像中的边界框,但YOLO是一个完整的检测系统。 OverFeat Sermanet等人训练卷积神经网络以执行定位并使该定位器适于执行检测[32]。 OverFeat有效地执行滑动窗口检测,但它仍然是一个不相交的系统。OverFeat优化了定位,而不是检测性能。像DPM一样,定位器在进行预测时仅看到本地信息。OverFeat不能推测全局上下文,因此需要大量的后处理来产生相关检测。 MultiGrasp 我们的工作在设计方面类似于Redmon [27] 等人的抓取检测的工作。我们的网格预测边界框的方式是基于MultiGrasp为抓取检测的设计。但是抓取检测比物体检测要简单得多。MultiGrasp只需要从包含一个物体的图像中预测单个可抓取区域即可,它不必估计物体的大小,位置或边界或预测它的类,只需要找到适合抓取的区域。YOLO预测图像中多个类的多个对象的边界框和类概率。4.实验 首先我们在PASCAL VOC 2007上对比YOLO和其他实时检测系统。为了理解YOLO和多个R-CNN变体的区别,我们探讨了在VOC 2007上YOLO和Fast R-CNN(R-CNN系列变体中性能最高的版本[14])的损失。基于不同的错误文件,我们展示了YOLO可以重新调整Fast R-CNN的检测并且减少背景误报的错误,从而显著的提高性能。我们还展示了在VOC 2012上的测试性能,并和当前最先进的方法的mAP对比。最后,我们展示了在两个艺术品数据集上,YOLO比其他检测器更容易迁移到其他领域。4.1和其他实时系统对比 对象检测的许多研究工作都集中在快速制作标准检测管道上。 [5] [38] [31] [14] 17 。然而,只有Sadeghi等人,创造了一个实时检测系统(每秒30帧或更快)[31],我们将YOLO与他们在30Hz或100Hz下运行的DPM的GPU实现进行比较。而其他人的努力没有达到实时检测的要求。我们还比较了它们的相对mAP和速度,以检查物体检测系统的准确性和性能之间的权衡。 Fast YOLO是在PASCAL上最快的物体检测方法,而且据我们所知它也是目前最快的物体检测方法。它达到了52.7%的mAP,这比以前的实时检测系统的准确率高出一倍以上。YOLO在保持实时性能的同时将mAP提高到63.4%。 我们也用VGG-16来训练YOLO。这个模型比YOLO准确率更高但是速度降低很多。它与依赖于VGG-16的其他检测系统相比是更有效的,但由于它达不到实时系统速度要求,所以本文的其他部分将重点放在我们的这个更快的模型上。 最快的DPM可以在不牺牲太多mAP的情况下有效加速DPM,但仍然会将实时性能降低2倍[38]。与神经网络方法相比,它还受到DPM检测精度相对较低的限制。 R-CNN减去R用静态边界框提议取代选择性搜索[20]。虽然它的速度比R-CNN速度快得多,但是它还还达不到实时的要求, 而且因为没有很好的建议框所以精度很受影响。 快速R-CNN加速了R-CNN的分类阶段,但仍然依赖于选择性搜索,每个图像大约需要2秒才能生成建议边界框。所以虽然它的mAP很高,但是速度只有0.5 fps达不到实时速度要求。 目前的Fast R-CNN使用一个神经网络替代选择性搜索来生成建议边界框。比如:Szegedy等人。在我们的测试中,他们最精确的模型速度达到7 fps,而较小的,不太精确的模型以速度达到18 fps。VGG-16版本的Fast R-CNN比YOLO的mAP高10,但是速度比YOLO慢6倍。Zeiler-Fergus Faster R-CNN仅比YOLO慢2.5倍,但是精度还是不及YOLO。4.2. VOC 2007误差分析 为了进一步研究YOLO和最先进的检测器之间的差异,我们将详细分析在VOC 2007上的检测结果。我们将YOLO与Fast R-CNN进行比较,因为Fast R-CNN是P ASCAL上性能最高的检测器之一,它的检测是公开的。 我们使用Hoiem等人的方法和工具[19]。对于测试时的每个类别,我们查看该类别的前N个预测。 每个预测都是正确的,或者根据错误类型进行如下分类: 正确:正确类别 并且 IOU>.5 定位:正确类别 并且 .5>IOU>.1 相似:相似的类别 并且 IOU>.1 其他:类别错误 并且IOU>.1 背景:所有类别上IOU<.1 图4显示了所有20个类中平均每种错误类型的细分。YOLO努力的去准确定位物体。YOLO中的定位错误比其他所有类型错误之和还多。Fast R-CNN的定位错误更少但是背景错误更多,它最好的检测结果中有13.6%是假阳(本来不含有物体误报为有物体)。Fast R-CNN对背景的误报错误是YOLO的三倍。 4.3. Fast R-CNN和YOLO相结合 与Fast R-CNN相比,YOLO的背景误报错误要少得多。 通过使用YOLO减小Fast R-CNN的背景误报错误,我们可以显着提升性能。对于R-CNN预测的每个边界框,我们检查YOLO是否预测了一个类似的框。如果确实如此,我们会根据YOLO预测的概率和两个框之间的重叠来提高该预测得分。 最好的Fast R-CNN模型在VOC 2007测试集上获得了71.8%的mAP。当与YOLO结合使用时,其mAP增加了3.2%达到75.0%。 我们还尝试将最好的Fast R-CNN模型与其他几个版本的Fast R-CNN相结合。 这些结合使mAP小幅增加0.3%和0.6%之间,详见表2。 YOLO带来的性能提升不是模型集成的结果,因为集成不同版本的Fast R-CNN几乎没有什么性能提升。相反,正是因为YOLO在测试中犯了各种各样的错误,导致它能很有效地提升Fast R-CNN的性能。不幸的是因为我们是分别训练各个模型然后结合结果,所以系统没有从YOLO的快速性上受益,速度没有什么提高。但是,因为YOLO速度很快,所以相对单独的Fast R-CNN,结合YOLO之后不会增加多少计算时间。4.4 VOC 2012结果 在VOC 2012测试集中,YOLO的mAP分数为57.9%。这低于现有技术水平,更接近使用VGG-16的原始R-CNN,参见表3。与最接近的竞争对手相比,我们的系统在小物体检测时有物体间竞争。在瓶子,羊,电视/监视器等类别上,YOLO得分比R-CNN或Feature Edit低8-10%。然而,在其他类别如猫和火车上,YOLO实现了更高的性能。我们的Fast R-CNN + YOLO组合模型是性能最高的检测方法之一。 Fast R-CNN从与YOLO的组合中获得了2.3%的提升,使其在公共排行榜上提升了5位。4.5抽象性 艺术作品中的人物检测 用于对象检测的学术数据集是从同一分布中提取训练和测试数据。 在实际应用中,很难预测所有可能的用例,测试数据可能与系统之前的情况不同[3]。我们将YOLO与其他检测系统在毕加索数据集[12]和人物艺术数据集[3]上进行了比较,这两个数据集是用来测试艺术品中的人员检测。 图5展示了YOLO和其他系统的性能比较。作为参考,我们提供了只在VOC2007上训练的模型的人员检测AP。 Picasso模型在VOC 2012上训练,而People-Art 在VOC2010上训练。 R-CNN在VOC 2007上有较高的AP,但是在艺术品领域性能就急剧下降。R-CNN使用选择性搜索来调整自然图像的建议边界框。 R-CNN中的分类器步骤只能看到小区域,所以需要很好的建议边界框。 DPM在应用于艺术品时可以很好的保持它的AP。之前的工作认为DPM表现良好是因为它具有物体的形状和布局的空间模型。虽然DPM不会像R-CNN那样退化,但是它的起始AP比较低。5.实地场景的实时检测 YOLO是一款快速而准确的检测器,非常适合应用在计算机视觉领域。我们将YOLO连接到网络摄像头,并验证它是否保持实时性能,计算时间时包括从摄像头获取图像并显示检测结果的时间。由此生成的系统是交互式的。虽然YOLO可以单独处理图像,但是当它和网络摄像头连接起来时就像一个追踪系统,在物体运动或者变化的时候实时检测系统。系统演示和源代码可以在我们的项目网站上找到:http://pjreddie.com/yolo/。6:结论 我们介绍了一款一体化(端到端)的物体检测系统YOLO。我们的模型结构很简单,可以在整个图像上进行训练。与基于分类器的方法不同,YOLO针对与检测性能直接相关的损失函数来训练,而且整个模型是联合训练的。 Fast YOLO是目前文献中最快的通用物体检测系统,YOLO引领目前最先进的实时物体检测技术。YOLO还可以很好的迁移到新的领域,这使它成为需要快速高效的物体检测系统的应用的理想选择。致谢:本项工作得到了ONR N00014-13-1-0720,NSF IIS-1338054和艾伦杰出研究员奖的部分支持。参考文献[1] M. B. Blaschko and C. H. Lampert. Learning to localize ob- jects with structured output regression. In Computer Vision– ECCV 2008, pages 2–15. Springer, 2008. 4[2] L. Bourdev and J. Malik. Poselets: Body part detectors trained using 3d human pose annotations. In International Conference on Computer Vision (ICCV), 2009. 8[3] H. Cai, Q. Wu, T. Corradi, and P. Hall. The cross- depiction problem: Computer vision algorithms for recog- nising objects in artwork and in photographs. arXiv preprint arXiv:1505.00110, 2015. 7[4] N. Dalal and B. Triggs. Histograms of oriented gradients for human detection. In Computer Vision and Pattern Recogni- tion, 2005. CVPR 2005. IEEE Computer Society Conference on, volume 1, pages 886–893. IEEE, 2005. 4, 8[5] T. Dean, M. Ruzon, M. Segal, J. Shlens, S. Vijaya- narasimhan, J. Yagnik, et al. Fast, accurate detection of 100,000 object classes on a single machine. In Computer Vision and Pattern Recognition (CVPR), 2013 IEEE Confer- ence on, pages 1814–1821. IEEE, 2013. 5[6] J. Donahue, Y. Jia, O. Vinyals, J. Hoffman, N. Zhang, E. Tzeng, and T. Darrell. Decaf: A deep convolutional acti- vation feature for generic visual recognition. arXiv preprint arXiv:1310.1531, 2013. 4[7] J. Dong, Q. Chen, S. Yan, and A. Yuille. Towards unified object detection and semantic segmentation. In Computer Vision–ECCV 2014, pages 299–314. Springer, 2014. 7[8] D. Erhan, C. Szegedy, A. Toshev, and D. Anguelov. Scalable object detection using deep neural networks. In Computer Vision and Pattern Recognition (CVPR), 2014 IEEE Confer- ence on, pages 2155–2162. IEEE, 2014. 5, 6[9] M. Everingham, S. M. A. Eslami, L. Van Gool, C. K. I. Williams, J. Winn, and A. Zisserman. The pascal visual ob- ject classeschallenge: A retrospective. International Journal of Computer Vision, 111(1):98–136, Jan. 2015. 2[10] P.F.Felzenszwalb, R.B.Girshick, D.McAllester, andD.Ra- manan. Object detection with discriminatively trained part based models. IEEE Transactions on Pattern Analysis and Machine Intelligence, 32(9):1627–1645, 2010. 1, 4[11] S. Gidaris and N. Komodakis. Object detection via a multi- region & semantic segmentation-aware CNN model. CoRR, abs/1505.01749, 2015. 7[12] S. Ginosar, D. Haas, T. Brown, and J. Malik. Detecting peo- pleincubistart. InComputerVision-ECCV2014Workshops, pages 101–116. Springer, 2014. 7[13] R. Girshick, J. Donahue, T. Darrell, and J. Malik. Rich fea- ture hierarchies for accurate object detection and semantic segmentation. In Computer Vision and Pattern Recognition (CVPR), 2014 IEEE Conference on, pages 580–587. IEEE, 2014. 1, 4, 7[14] R. B. Girshick. Fast R-CNN. CoRR, abs/1504.08083, 2015. 2, 5, 6, 7[15] S. Gould, T. Gao, and D. Koller. Region-based segmenta- tion and object detection. In Advances in neural information processing systems, pages 655–663, 2009. 4[16] B. Hariharan, P. Arbeláez, R. Girshick, and J. Malik. Simul- taneous detection and segmentation. In Computer Vision– ECCV 2014, pages 297–312. Springer, 2014. 7[17] K.He, X.Zhang, S.Ren, andJ.Sun. Spatialpyramidpooling in deep convolutional networks for visual recognition. arXiv preprint arXiv:1406.4729, 2014. 5[18] G. E. Hinton, N. Srivastava, A. Krizhevsky, I. Sutskever, and R. R. Salakhutdinov. Improving neural networks by pre- venting co-adaptation of feature detectors. arXiv preprint arXiv:1207.0580, 2012. 4[19] D.Hoiem, Y.Chodpathumwan, andQ.Dai. Diagnosingerror in object detectors. In Computer Vision–ECCV 2012, pages 340–353. Springer, 2012. 6[20] K. Lenc and A. Vedaldi. R-cnn minus r. arXiv preprint arXiv:1506.06981, 2015. 5, 6[21] R. Lienhart and J. Maydt. An extended set of haar-like fea- tures for rapid object detection. In Image Processing. 2002. Proceedings. 2002 International Conference on, volume 1, pages I–900. IEEE, 2002. 4[22] M. Lin, Q. Chen, and S. Yan. Network in network. CoRR, abs/1312.4400, 2013. 2[23] D. G. Lowe. Object recognition from local scale-invariant features. In Computer vision, 1999. The proceedings of the seventh IEEE international conference on, volume 2, pages 1150–1157. Ieee, 1999. 4[24] D. Mishkin. Models accuracy on imagenet 2012 val. https://github.com/BVLC/caffe/wiki/ Models-accuracy-on-ImageNet-2012-val. Ac- cessed: 2015-10-2. 3[25] C. P. Papageorgiou, M. Oren, and T. Poggio. A general framework for object detection. In Computer vision, 1998. sixth international conference on, pages 555–562. IEEE, 1998. 4[26] J. Redmon. Darknet: Open source neural networks in c. http://pjreddie.com/darknet/, 2013–2016. 3[27] J.RedmonandA.Angelova. Real-timegraspdetectionusing convolutional neural networks. CoRR, abs/1412.3128, 2014. 5[28] S. Ren, K. He, R. Girshick, and J. Sun. Faster r-cnn: To- wards real-time object detection with region proposal net- works. arXiv preprint arXiv:1506.01497, 2015. 5, 6, 7[29] S. Ren, K. He, R. B. Girshick, X. Zhang, and J. Sun. Object detection networks on convolutional feature maps. CoRR, abs/1504.06066, 2015. 3, 7[30] O. Russakovsky, J. Deng, H. Su, J. Krause, S. Satheesh, S. Ma, Z. Huang, A. Karpathy, A. Khosla, M. Bernstein, A. C. Berg, and L. Fei-Fei. ImageNet Large Scale Visual Recognition Challenge. International Journal of Computer Vision (IJCV), 2015. 3[31] M. A. Sadeghi and D. Forsyth. 30hz object detection with dpm v5. In Computer Vision–ECCV 2014, pages 65–79. Springer, 2014. 5, 6[32] P. Sermanet, D. Eigen, X. Zhang, M. Mathieu, R. Fergus, and Y. LeCun. Overfeat: Integrated recognition, localiza- tion and detection using convolutional networks. CoRR, abs/1312.6229, 2013. 4, 5[33] Z.ShenandX.Xue. Domoredropoutsinpool5featuremaps for better object detection. arXiv preprint arXiv:1409.6911, 2014. 7[34] C. Szegedy, W. Liu, Y. Jia, P. Sermanet, S. Reed, D. Anguelov, D. Erhan, V. Vanhoucke, and A. Rabinovich. Going deeper with convolutions. CoRR, abs/1409.4842, 2014. 2[35] J. R. Uijlings, K. E. van de Sande, T. Gevers, and A. W. Smeulders. Selective search for object recognition. Inter- national journal of computer vision, 104(2):154–171, 2013. 4[36] P. Viola and M. Jones. Robust real-time object detection. International Journal of Computer Vision, 4:34–47, 2001. 4[37] P. Viola and M. J. Jones. Robust real-time face detection. International journal of computer vision, 57(2):137–154, 2004. 5[38] J. Yan, Z. Lei, L. Wen, and S. Z. Li. The fastest deformable part model for object detection. In Computer Vision and Pat- tern Recognition (CVPR), 2014 IEEE Conference on, pages 2497–2504. IEEE, 2014. 5, 6[39] C. L. Zitnick and P. Dollár. Edge boxes: Locating object pro- posals from edges. In Computer Vision–ECCV 2014, pages 391–405. Springer, 2014. 4参考资料YOLOv1论文翻译:https://blog.csdn.net/woduoxiangfeiya/article/details/80866155
-
Pytorch 实战:卷积神经网络(CNN)实现MINIST手写数字识别 实验环境torch = 1.6.0torchvision = 0.7.0matplotlib = 3.3.3 # 绘图用progressbar = 2.5 # 绘制进度条用easydict # 超参数字典功能增强使用数据集手写数字集MINIST导入相关的包# 导包 import torch import torch.nn as nn import torch.optim as optim from torch.utils.data import DataLoader import torchvision from torchvision import datasets,transforms import matplotlib.pyplot as plt import random from progressbar import *设置超参数from easydict import EasyDict #增强python的dict的功能用 # 定义超参数 super_param = { "batch_size":256, "device": torch.device('cuda:0' if torch.cuda.is_available() else 'cpu'), "epochs":10, "lr":0.3, } super_param = EasyDict(super_param) print(super_param){'batch_size': 16, 'device': device(type='cuda', index=0), 'epochs': 10, 'lr': 0.3, 'hidden_num': 15}数据处理(下载、处理、加载数据到DataLoader)# 下载、加载数据 # 构transform(pipeline),对图像做处理 transform = transforms.Compose([ transforms.ToTensor(), transforms.Normalize((0.1307,),(0.3081,)) #正则化 ]) # 下载数据 trainsets = datasets.MNIST('data',train=True,download=True,transform=transform) testsets = datasets.MNIST('data',train=False,download=True,transform=transform) # dataloader 加载数据 train_loader = DataLoader(trainsets,batch_size=super_param.batch_size,shuffle=True) test_loader = DataLoader(trainsets,batch_size=super_param.batch_size,shuffle=True)查看数据样例查看数据样例【单张】# 查看数据样例-单张 image,label = trainsets[random.randint(0,len(trainsets))] print('label=',label) plt.imshow(image.permute(1,2,0),cmap='gray') plt.show()查看数据样例【一批】# 查看数据样例-一批 images,labels = next(iter(test_loader)) data_sample_img = torchvision.utils.make_grid(images).numpy().transpose(1,2,0) print('labels=',labels) plt.figure(dpi=200) plt.xticks([]) plt.yticks([]) plt.imshow(data_sample_img) plt.show()构建CNN网络模型 -简单版- 使用Sequential## 构建CNN模型-简单版-使用Sequential model = nn.Sequential( nn.Conv2d(in_channels=1,out_channels=10,kernel_size=5,stride=1,padding=0),# b*1*28*28-->b*10*24*24 nn.ReLU(), nn.MaxPool2d(2),# b*10*24*24-->b*10*12*12 nn.Conv2d(10,20,3,1,0),# b*10*12*12-->b*20*10*10 nn.ReLU(), nn.Flatten(),#b*20*10*10-->b*2000 nn.Linear(2000,500),#b*2000-->b*500 nn.ReLU(), nn.Linear(500,10),#b*500-->b*10 nn.ReLU(), nn.Softmax(), ) print(model)Sequential( (0): Conv2d(1, 10, kernel_size=(5, 5), stride=(1, 1)) (1): ReLU() (2): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False) (3): Conv2d(10, 20, kernel_size=(3, 3), stride=(1, 1)) (4): ReLU() (5): Flatten(start_dim=1, end_dim=-1) (6): Linear(in_features=2000, out_features=500, bias=True) (7): ReLU() (8): Linear(in_features=500, out_features=10, bias=True) (9): ReLU() (10): Softmax(dim=None) )构建CNN网络模型 -使用自定义类# 构建网络模型 - 使用自定义类 class Digit_Rec(nn.Module): def __init__(self): super(Digit_Rec,self).__init__() self.conv1 = nn.Conv2d(1,10,5) #1:灰度图片的通道,10:输出通道,5:kernel self.relu1 = nn.ReLU() self.max_pool = nn.MaxPool2d(2,2) self.conv2 = nn.Conv2d(10,20,3) #10:输入通道,20:输出通道,3:Kernel self.relu2 = nn.ReLU() self.fc1 = nn.Linear(20*10*10,500) # 20*10*10:输入通道,500:输出通道 self.relu3 = nn.ReLU() self.fc2 = nn.Linear(500,10) # 500:输入通道,10:输出通道 self.relu4 = nn.ReLU() self.softmax = nn.Softmax(dim=1) def forward(self,x): batch_size = x.size(0) # x的格式:batch_size x 1 x 28 x 28 拿到了batch_size x = self.conv1(x) # 输入:batch*1*28*28 输出:batch*10*24*24 x = self.relu1(x) x = self.max_pool(x) # 输入:batch*10*24*24输出:batch*10*12*12 x = self.conv2(x) x = self.relu2(x) x = x.view(batch_size,-1) #fatten 展平 -1自动计算维度,20*10*10=2000 x = self.fc1(x) # 输入:batch*2000 输出:batch*500 x = self.relu3(x) x = self.fc2(x) # 输入:batch*500 输出:batch*10 x = self.relu4(x) output = self.softmax(x) # 计算分类后,每个数字的概率值 return output model = Digit_Rec() print(model)Digit_Rec( (conv1): Conv2d(1, 10, kernel_size=(5, 5), stride=(1, 1)) (relu1): ReLU() (max_pool): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False) (conv2): Conv2d(10, 20, kernel_size=(3, 3), stride=(1, 1)) (relu2): ReLU() (fc1): Linear(in_features=2000, out_features=500, bias=True) (relu3): ReLU() (fc2): Linear(in_features=500, out_features=10, bias=True) (relu4): ReLU() (softmax): Softmax(dim=1) )定义损失函数和优化器# 定义损失函数和优化 criterion = nn.CrossEntropyLoss() optimizer = torch.optim.SGD(model.parameters(),lr=super_param.lr)定义模型训练单个epoch函数# 定义模型训练单个epoch函数 def train_model_epoch(model,train_loader,super_param,criterion,optimzer,epoch): model.train()#训练声明 for batch_index,(images,labels) in enumerate(train_loader): # 数据上device images,labels = images.to(super_param.device),labels.to(super_param.device) # 梯度清零 optimzer.zero_grad() # 前向传播 output = model(images) # 计算损失 loss = criterion(output,labels) # 反向传播,计算梯度 loss.backward() # 参数更新(优化) optimzer.step() # 打印训练参考信息,每1000个batch打印一次 if batch_index % 1000 == 0: print("Epoch:{} Batch Index(batch_size={}):{}/{} Loss:{}". format(epoch,super_param.batch_size,batch_index,len(train_loader),loss.item()))定义模型验证方法# 定义模型验证方法 def test_model(model,test_loader,super_param,criterion): model.eval()#测试声明 # 数据统计 correct_num,test_loss = 0.0,0.0 #正确数,测试损失 #定义进度条 widgets = ['模型测试中: ',Percentage(), ' ', Bar('#'),' ', Timer(),' ', ETA()] pbar = ProgressBar(widgets=widgets, maxval=100).start() # 取消计算梯度,避免更新模型参数 with torch.no_grad(): for batch_index,(images,labels) in enumerate(test_loader): # 数据上devics images,labels = images.to(super_param.device),labels.to(super_param.device) # 模型预测 output = model(images) # 计算测试损失 test_loss += criterion(output,labels).item() # 确定预测结果是哪个数字 pred = output.argmax(dim=1) #argmax返回 值,索引 dim=1表示要索引 # 统计预测正确数量 correct_num += pred.eq(labels.view_as(pred)).sum().item() #更新进度条进度 pbar.update(batch_index/len(test_loader)*100) #释放进度条 pbar.finish() #打印测试信息 test_loss = test_loss/len(test_loader.dataset) test_accuracy = correct_num / len(test_loader.dataset) print("Test --- Avg Loss:{},Accuracy:{}\n".format(test_loss,test_accuracy)) return test_loss,test_accuracy模型训练和测试# 模型训练和测试 #模型上device mode = model.to(super_param.device) #记录每个epoch的测试数据、用于绘图 epoch_list = [] loss_list = [] accuracy_list = [] for epoch in range(super_param.epochs): train_model_epoch(model,train_loader,super_param,criterion,optimizer,epoch) test_loss,test_accuracy = test_model(model,test_loader,super_param,criterion) # 数据统计 epoch_list.append(epoch) loss_list.append(test_loss) accuracy_list.append(test_accuracy)查看数据统计结果# 查看数据统计结果 fig = plt.figure(figsize=(12,12),dpi=70) #子图1 ax1 = plt.subplot(2,1,1) title = "bach_size={},lr={}".format(super_param.batch_size,super_param.lr) plt.title(title,fontsize=15) plt.xlabel('Epochs',fontsize=15) plt.ylabel('Loss',fontsize=15) plt.xticks(fontsize=13) plt.yticks(fontsize=13) plt.plot(epoch_list,loss_list) #子图2 ax2 = plt.subplot(2,1,2) plt.xlabel('Epochs',fontsize=15) plt.ylabel('Accuracy',fontsize=15) plt.xticks(fontsize=13) plt.yticks(fontsize=13) plt.plot(epoch_list,accuracy_list,'r') plt.show()
-
Pytorch 实战:BP神经网络实现MINIST实现手写数字识别(单层感知机) Pytorch 实战:BP神经网络实现MINIST实现手写数字识别(单层感知机)实验环境torch = 1.6.0torchvision = 0.7.0matplotlib = 3.3.3 # 绘图用progressbar = 2.5 # 绘制进度条用easydict # 超参数字典功能增强使用数据集手写数字集MINIST导入相关的包# 导包 import torch import torch.nn as nn import torch.optim as optim from torch.utils.data import DataLoader import torchvision from torchvision import datasets,transforms import matplotlib.pyplot as plt import random from progressbar import *设置超参数from easydict import EasyDict #增强python的dict的功能用 # 定义超参数 super_param = { "batch_size":128, "device": torch.device('cuda:0' if torch.cuda.is_available() else 'cpu'), "epochs":10, "lr":0.3, 'hidden_num':15, #隐藏层神经元数量 } super_param = EasyDict(super_param) print(super_param){'batch_size': 16, 'device': device(type='cuda', index=0), 'epochs': 10, 'lr': 0.3, 'hidden_num': 15}数据处理(下载、处理、加载数据到DataLoader)# 下载、加载数据 # 构transform(pipeline),对图像做处理 transform = transforms.Compose([ transforms.ToTensor(), transforms.Normalize((0.1307,),(0.3081,)) #正则化 ]) # 下载数据 trainsets = datasets.MNIST('data',train=True,download=True,transform=transform) testsets = datasets.MNIST('data',train=False,download=True,transform=transform) # dataloader 加载数据 train_loader = DataLoader(trainsets,batch_size=super_param.batch_size,shuffle=True) test_loader = DataLoader(trainsets,batch_size=super_param.batch_size,shuffle=True)查看数据样例查看数据样例【单张】# 查看数据样例-单张 image,label = trainsets[random.randint(0,len(trainsets))] print('label=',label) plt.imshow(image.permute(1,2,0),cmap='gray') plt.show()查看数据样例【一批】# 查看数据样例-一批 images,labels = next(iter(test_loader)) data_sample_img = torchvision.utils.make_grid(images).numpy().transpose(1,2,0) print('labels=',labels) plt.figure(dpi=200) plt.xticks([]) plt.yticks([]) plt.imshow(data_sample_img) plt.show()构建BP网络模型 -简单版- 使用Sequential## 构建网络模型-BP model = nn.Sequential( nn.Flatten(), nn.Linear(28*28,super_param.hidden_num), nn.ReLU(), nn.Linear(super_param.hidden_num,10), nn.ReLU(), nn.Softmax(), ) print(model)Sequential( (0): Flatten() (1): Linear(in_features=784, out_features=15, bias=True) (2): ReLU() (3): Linear(in_features=15, out_features=10, bias=True) (4): ReLU() (5): Softmax(dim=None) )构建BP网络模型 -使用自定义类## 构建BP网络模型 -使用自定义类 class Digit_Rec(nn.Module): def __init__(self,hidden_num): super(Digit_Rec,self).__init__() self.fc1 = nn.Linear(28*28,hidden_num) self.relu1 = nn.ReLU() self.fc2 = nn.Linear(hidden_num,10) self.relu2 = nn.ReLU() self.softmax = nn.Softmax(dim=1) def forward(self,x): batch_size = x.size(0) # x的格式:batch_size x 1 x 28 x 28 拿到了batch_size x = x.view(batch_size,28*28) # flatten out = self.fc1(x) out = self.relu1(out) out = self.fc2(out) out = self.relu2(out) out = self.softmax(out) return out model = Digit_Rec(super_param.hidden_num) print(model)Digit_Rec( (fc1): Linear(in_features=784, out_features=50, bias=True) (relu1): ReLU() (fc2): Linear(in_features=50, out_features=10, bias=True) (relu2): ReLU() (softmax): Softmax(dim=1) )定义损失函数和优化器# 定义损失函数和优化 criterion = nn.CrossEntropyLoss() optimizer = torch.optim.SGD(model.parameters(),lr=super_param.lr)定义模型训练单个epoch函数# 定义模型训练单个epoch函数 def train_model_epoch(model,train_loader,super_param,criterion,optimzer,epoch): model.train()#训练声明 for batch_index,(images,labels) in enumerate(train_loader): # 数据上device images,labels = images.to(super_param.device),labels.to(super_param.device) # 梯度清零 optimzer.zero_grad() # 前向传播 output = model(images) # 计算损失 loss = criterion(output,labels) # 反向传播,计算梯度 loss.backward() # 参数更新(优化) optimzer.step() # 打印训练参考信息,每1000个batch打印一次 if batch_index % 1000 == 0: print("Epoch:{} Batch Index(batch_size={}):{}/{} Loss:{}". format(epoch,super_param.batch_size,batch_index,len(train_loader),loss.item()))定义模型验证方法# 定义模型验证方法 def test_model(model,test_loader,super_param,criterion): model.eval()#测试声明 # 数据统计 correct_num,test_loss = 0.0,0.0 #正确数,测试损失 #定义进度条 widgets = ['模型测试中: ',Percentage(), ' ', Bar('#'),' ', Timer(),' ', ETA()] pbar = ProgressBar(widgets=widgets, maxval=100).start() # 取消计算梯度,避免更新模型参数 with torch.no_grad(): for batch_index,(images,labels) in enumerate(test_loader): # 数据上devics images,labels = images.to(super_param.device),labels.to(super_param.device) # 模型预测 output = model(images) # 计算测试损失 test_loss += criterion(output,labels).item() # 确定预测结果是哪个数字 pred = output.argmax(dim=1) #argmax返回 值,索引 dim=1表示要索引 # 统计预测正确数量 correct_num += pred.eq(labels.view_as(pred)).sum().item() #更新进度条进度 pbar.update(batch_index/len(test_loader)*100) #释放进度条 pbar.finish() #打印测试信息 test_loss = test_loss/len(test_loader.dataset) test_accuracy = correct_num / len(test_loader.dataset) print("Test --- Avg Loss:{},Accuracy:{}\n".format(test_loss,test_accuracy)) return test_loss,test_accuracy模型训练和测试# 模型训练和测试 #模型上device mode = model.to(super_param.device) #记录每个epoch的测试数据、用于绘图 epoch_list = [] loss_list = [] accuracy_list = [] for epoch in range(super_param.epochs): train_model_epoch(model,train_loader,super_param,criterion,optimizer,epoch) test_loss,test_accuracy = test_model(model,test_loader,super_param,criterion) # 数据统计 epoch_list.append(epoch) loss_list.append(test_loss) accuracy_list.append(test_accuracy)查看数据统计结果# 查看数据统计结果 fig = plt.figure(figsize=(12,12),dpi=70) #子图1 ax1 = plt.subplot(2,1,1) title = "hidden_neuron_num={},bach_size={},lr={}".format(super_param.hidden_num,super_param.batch_size,super_param.lr) plt.title(title,fontsize=15) plt.xlabel('Epochs',fontsize=15) plt.ylabel('Loss',fontsize=15) plt.xticks(fontsize=13) plt.yticks(fontsize=13) plt.plot(epoch_list,loss_list) #子图2 ax2 = plt.subplot(2,1,2) plt.xlabel('Epochs',fontsize=15) plt.ylabel('Accuracy',fontsize=15) plt.xticks(fontsize=13) plt.yticks(fontsize=13) plt.plot(epoch_list,accuracy_list,'r') plt.show()隐藏层神经元数量=15隐藏层神经元数量=30隐藏层神经元数量=50
-
YOLOv1学习:(二)损失函数理解和实现 YOLOv1学习:(二)损失函数理解和实现损失函数形式损失函数理解1预测框的中心点(x, y) 造成的损失(即对损失函数有贡献)是图中的第一行。其中$||_{ij}^{obj}$为控制函数,在标签中包含物体的那些格点处,该值为1;若格点不含有物体,该值为 0。也就是只对那些有真实物体所属的格点进行损失计算,若该格点不包含物体则不进行此项损失计算,因此预测数值不对此项损失函数造成影响(因为这个预测数值根本不带入此项损失函数计算)。预测框的高度(w, h)造成的损失(即对损失函数有贡献)是图中的第二行。其中 $||_{ij}^{obj}$为控制函数,含义与预测中心一样。1、2项就是边框回归。第三行与第四行,都是预测框的置信度C。当该格点不含有物体时,该置信度的标签为0;若含有物体时,该置信度的标签为预测框与真实物体框的IOU数值(IOU计算公式为:两个框交集的面积除以并集的面积)。其中第三行函数的$||_{ij}^{obj}$依然为控制函数,在标签中包含物体的那些格点处,该值为1;若格点不含有物体,该值为 0。也就是只对那些有真实物体所属的格点进行损失计算,若该格点不包含物体则不进行此项损失计算,因此预测数值不对此项损失函数造成影响(因为这个预测数值根本不带入此项损失函数计算)。第四行的$||_{ij}^{obj}$也控制函数,只是含义与第三项的相反,在标签中不含物体的那些格点处,该值为1;若格点含有物体,该值为 0。也就是只对那些没有真实物体所属的格点进行损失计算,若该格点包含物体(包含物体置信度损失已经在第三项计算了)则不进行此项损失计算,因此预测数值不对此项损失函数造成影响(因为这个预测数值根本不带入此项损失函数计算)。第五行为物体类别概率P,对应的类别位置,该标签数值为1,其余位置为0,与分类网络相同。其中此项$||_{ij}^{obj}$也为控制函数,在标签中包含物体的那些格点处,该值为1;若格点不含有物体,该值为 0。也就是只对那些有真实物体所属的格点进行物体类别损失计算,若该格点不包含物体则不进行此项损失计算,因此预测数值不对此项损失函数造成影响(因为这个预测数值根本不带入此项损失函数计算)。此时再来看${\lambda}_{coord}$ 与${\lambda}_{noobj}$ ,Yolo面临的物体检测问题,是一个典型的类别数目不均衡的问题。其中49个格点,含有物体的格点往往只有3、4个,其余全是不含有物体的格点。此时如果不采取点措施,那么物体检测的mAP不会太高,因为模型更倾向于不含有物体的格点。因此${\lambda}_{coord}$ 与 ${\lambda}_{noobj}$的作用,就是让含有物体的格点,在损失函数中的权重更大,让模型更加“重视”含有物体的格点所造成的损失。在论文中, ${\lambda}_{coord}$ 与 ${\lambda}_{noobj}$ 的取值分别为5与0.5。损失函数理解2-损失函数分为三个部分$$ ||_{ij}^{obj}表示cell中是否含有真实物体的中心,含有则1,否则取0 $$① 坐标误差为什么宽和高要带根号???对不同大小的bbox预测中,相比于大bbox预测偏一点,小box预测偏一点更不能忍受。作者用了一个比较取巧的办法,就是将box的width和height取平方根代替原本的height和width(主要为了平衡小目标检测预测的偏移)② IOU误差这里的$\hat{C_i}$分别表示 1 和 0 $,C_i=Pr(Object)*IOU_{pred}^{truth}$③ 分类误差这个很容易理解(激活函数的输出)。损失函数代码实现实现""" + input + pred: (batch_size,30,7,7)的网络输出数据 + labels: (batch_size,30,7,7)的样本标签数据 + output + 当前批次样本的平均损失 """ """ + YOLOv1 的损失分为3部分 + 坐标预测损失 + 置信度预测损失 + 含object的box的confidence预测损失 + 不含object的box的confidence预测损失 + 类别预测损失 """ class Loss_YOLOv1(nn.Module): def __init__(self,batch_size=1): super(Loss_YOLOv1,self).__init__() self.batch_size = batch_size """ box格式转换 + input + src_box : [box_x_lefttop,box_y_lefttop,box_w,box_h] + output + dst_box : [box_x1,box_y1,box_x2,box_y2] """ def convert_box_type(self,src_box): x,y,w,h = tuple(src_box) x1,y1 = x,y x2,y2 = x+w,y+w return [x1,y1,x2,y2] """ iou计算 """ def cal_iou(self,box1,box2): # 求相交区域左上角的坐标和右下角的坐标 box_intersect_x1 = max(box1[0], box2[0]) box_intersect_y1 = max(box1[1], box2[1]) box_intersect_x2 = min(box1[2], box2[2]) box_intersect_y2 = min(box1[3], box2[3]) # 求二者相交的面积 area_intersect = (box_intersect_y2 - box_intersect_y1) * (box_intersect_x2 - box_intersect_x1) # 求box1,box2的面积 area_box1 = (box1[2] - box1[0]) * (box1[3] - box1[1]) area_box2 = (box2[2] - box2[0]) * (box2[3] - box2[1]) # 求二者相并的面积 area_union = area_box1 + area_box2 - area_intersect # 计算iou(交并比) iou = area_intersect / area_union return iou def forward(self,pred,target): lambda_noobj = 0.5 # lambda_noobj参数 lambda_coord = 5 # lambda_coord参数 site_pred_loss = 0 # 坐标预测损失 obj_confidence_pred_loss = 0 # 含object的box的confidence预测损失 noobj_confidence_pred_loss = 0 #不含object的box的confidence预测损失 class_pred_loss = 0 # 类别预测损失 for batch_size_index in range(self.batch_size): # batchsize循环 for x_index in range(7): # x方向网格循环 for y_index in range(7): # y方向网格循环 # 获取单个网格的预测数据和真实数据 pred_data = pred[batch_size_index,:,x_index,y_index] # [x,y,w,h,confidence,x,y,w,h,confidence,cls*20] true_data = target[batch_size_index,:,x_index,y_index] #[x,y,w,h,confidence,x,y,w,h,confidence,cls*20] if true_data[4]==1:# 如果包含物体 # 解析预测数据和真实数据 pred_box_confidence_1 = pred_data[0:5] # [x,y,w,h,confidence1] pred_box_confidence_2 = pred_data[5:10] # [x,y,w,h,confidence2] true_box_confidence = true_data[0:5] # [x,y,w,h,confidence] # 获取两个预测box并计算与真实box的iou iou1 = self.cal_iou(self.convert_box_type(pred_box_confidence_1[0:4]),self.convert_box_type(true_box_confidence[0:4])) iou2 = self.cal_iou(self.convert_box_type(pred_box_confidence_2[0:4]),self.convert_box_type(true_box_confidence[0:4])) # 在两个box中选择iou大的box负责预测物体 if iou1 >= iou2: better_box_confidence,bad_box_confidence = pred_box_confidence_1,pred_box_confidence_2 better_iou,bad_iou = iou1,iou2 else: better_box_confidence,bad_box_confidence = pred_box_confidence_2,pred_box_confidence_1 better_iou,bad_iou = iou2,iou1 # 计算坐标预测损失 site_pred_loss += lambda_coord * torch.sum((better_box_confidence[0:2]- true_box_confidence[0:2])**2) # x,y的预测损失 site_pred_loss += lambda_coord * torch.sum((better_box_confidence[2:4].sqrt()-true_box_confidence[2:4].sqrt())**2) # w,h的预测损失 # 计算含object的box的confidence预测损失 obj_confidence_pred_loss += (better_box_confidence[4] - better_iou)**2 # iou比较小的bbox不负责预测物体,因此confidence loss算在noobj中 # 因此还需计算不含object的box的confidence预测损失 noobj_confidence_pred_loss += lambda_noobj * (bad_box_confidence[4] - bad_iou)**2 # 计算类别损失 class_pred_loss += torch.sum((pred_data[10:] - true_data[10:])**2) else: # 如果不包含物体,则只有置信度损失--noobj_confidence_pred_loss # [4,9]代表取两个预测框的confidence noobj_confidence_pred_loss += lambda_noobj * torch.sum(pred[batch_size_index,(4,9),x_index,y_index]**2) loss = site_pred_loss + obj_confidence_pred_loss + noobj_confidence_pred_loss + class_pred_loss return loss/self.batch_size调用测试label1 = torch.rand([1,30,7,7]) label2 = torch.rand([1,30,7,7]) print(label1.shape,label2.shape) print(loss(label1,label2))torch.Size([1, 30, 7, 7]) torch.Size([1, 30, 7, 7]) tensor(14.6910)参考资料YOLO V1损失函数理解:http://www.likecs.com/show-65912.htmlYOLOv1算法理解:https://www.cnblogs.com/ywheunji/p/10808989.html【目标检测系列】yolov1的损失函数详解(结合pytorch代码):https://blog.csdn.net/gbz3300255/article/details/109179751yolo-yolo v1损失函数理解:https://blog.csdn.net/qq_38236744/article/details/106724596



![Scene Text Detection Resources(场景文字识别资源汇总) [转载] [翻译]](https://blog.inat.top/usr/themes/Joe/assets/thumb/34.jpg)
![Scene Text Detection Resources(场景文字识别资源汇总)[转载]](https://blog.inat.top/usr/themes/Joe/assets/thumb/21.jpg)