搜索到
30
篇与
的结果
-
 python学习:正则表达式re模块的使用 1.常用常量1.1 re.I(re.IGNORECASE)执行不区分大小写的匹配;类似的表达式也[A-Z]将匹配小写字母。re.findall(r"[a-z]", "ah667GHD67DYT78") # Return:['a', 'h'] re.findall(r"[a-z]", "ah667GHD67DYT78",flags=re.IGNORECASE) # Return:['a', 'h', 'G', 'H', 'D', 'D', 'Y', 'T']1.2 re.S(re.DOTALL)使'.'特殊字符与任何字符都匹配,包括换行符;没有此标志,'.'将匹配除换行符以外的任何内容。s = '''first line second line third line''' re.findall(r".+", s) # Return:['first line', 'second line', 'third line'] re.findall(r".+", s, flags=re.DOTALL) # Return:['first line\nsecond line\nthird line']2.常用方法2.1 re.match(pattern,string,flags = 0 )对字符串从开头进行正则匹配 (匹配零个或者一个对象)如果字符串与模式匹配,则返回相应的匹配对象。re.match('a','abcade') # Return:<re.Match object; span=(0, 1), match='a'> re.match('\w+','abc123de') # Return:<re.Match object; span=(0, 8), match='abc123de'>如果字符串与模式不匹配,则返回None;re.match('z','abcade') # Return:None可以使用group()获取匹配结果re.match('a','abcade').group() # Return:'a'2.2 re.search(pattern,string,flags = 0 )扫描字符串以查找正则表达式模式产生匹配项的第一个位置(匹配零个或者一个对象),与re.match的区别re.match是从字符串的开头进行匹配re.search是从对字符串的挨个位置都进行尝试,指导匹配上或者尝试完所有位置如果匹配上,则返回相应的match对象。re.search('b','abcade') # Return:<re.Match object; span=(1, 2), match='b'> re.search('b','abcade').group() # Return:'b'如果字符串中没有位置与模式匹配,则返回None;re.search('z','abcade') # Return:None2.3 re.compile(pattern,flags = 0 )该方法同re.match和re.search将正则表达式模式编译为正则表达式对象,可使用match(),search()以及下面所述的其他方法将其用于匹配reg = re.compile('\d{2}') # 正则对象-匹配两个数字 reg.search('12abc') # Return:<re.Match object; span=(0, 2), match='12'> reg.search('12abc').group() # Return:12reg = re.compile('\d{2}') # 正则对象-匹配两个数字 reg.match('123abc') # Return:<re.Match object; span=(0, 2), match='12'> reg.match('12abc').group() # Return:122.4 re.fullmatch(pattern,string,flags = 0 )如果整个字符串与正则表达式模式匹配,则返回相应的match对象。re.fullmatch('\w+','abcade') # Return:<re.Match object; span=(0, 6), match='abcade'> re.fullmatch('\w+','abcade').group() # Return:'abcade'否则返回None;re.fullmatch('\w+','abca de') # Return:None2.5 re.split(pattern,string,maxsplit = 0,flags = 0 )通过正则表达式来split字符串。re.split(r'\W+', 'Words, words, words.') # Return:['Words', 'words', 'words', '']如果在pattern中使用了捕获括号,那么模式中所有组的文本也将作为结果列表的一部分返回。re.split(r'(\W+)', 'Words, words, words.') # Return:['Words', ', ', 'words', ', ', 'words', '.', '']如果分隔符中有捕获组,并且该匹配组在字符串的开头匹配,则结果将从空字符串开始。字符串的末尾也是如此:re.split(r'(\W+)', '...words, words...') # Return:['', '...', 'words', ', ', 'words', '...', '']如果maxsplit不为零,则最多会发生maxsplit分割,并将字符串的其余部分作为列表的最后一个元素返回。re.split(r'\W+', 'Words, words, words.',1) # Return:['Words', 'words, words.']2.6 re.findall(pattern,string,flags = 0 )从左到右扫描该字符串,以列表的形式返回所有的匹配项re.findall('a', 'This is a beautiful place!') # Return:['a', 'a', 'a'] re.findall('z', 'This is a beautiful place!') # Return:[]2.7 re.sub(pattern,repl,string,count = 0,flags = 0 )使用repl替换掉string中pattern成功匹配的匹配项,count参数表示将匹配到的内容进行替换的次数re.sub('\d', 'S', 'abc12jh45li78') #将匹配到所有的数字替换成S # Return:'abcSSjhSSliSS' re.sub('\d', 'S', 'abc12jh45li78', 2) #将匹配到的数字替换成S,只替换2次就停止 # Return:'abcSSjh45li78'如果找不到该模式, 则返回的字符串不变。re.sub('z', 'S', 'abc12jh45li78') # Return:'abc12jh45li78'2.8 re.subn(pattern,repl,string,count = 0,flags = 0 )执行与相同的操作sub(),但返回一个元组。(new_string, number_of_subs_made)re.subn('\d', 'S', 'abc12jh45li78') # Return:('abcSSjhSSliSS', 6) re.subn('\d', 'S', 'abc12jh45li78', 3) # Return:('abcSSjhS5li78', 3)3. 其他补充3.1 使用正则表达式匹配中文 re.findall(r"[\u4e00-\u9fa5]", "沿charlie在charlie五前等待。charlie charlie五前等四川八八六四") # Return:['沿', '在', '五', '前', '等', '待', '五', '前', '等', '四', '川', '八', '八', '六', '四']3.2 贪心匹配和非贪心匹配贪心匹配:正则表达式在有二义的情况下,会尽可能匹配最长的字符串Python的正则表达式默认是”贪心“的,这表示在有二义的情况下,会尽可能匹配最长的字符串。re.search(r'(ha){3,5}','hahahahaha').group() # Return:'hahahahaha'非贪心匹配:匹配尽可能最短的字符串使用方式:在有二义的正则表达式的后面跟一个问号re.search(r'(ha){3,5}?','hahahahaha').group() # Return:'hahaha'参考资料使用正则表达式Python之re模块python 正则表达式详解
python学习:正则表达式re模块的使用 1.常用常量1.1 re.I(re.IGNORECASE)执行不区分大小写的匹配;类似的表达式也[A-Z]将匹配小写字母。re.findall(r"[a-z]", "ah667GHD67DYT78") # Return:['a', 'h'] re.findall(r"[a-z]", "ah667GHD67DYT78",flags=re.IGNORECASE) # Return:['a', 'h', 'G', 'H', 'D', 'D', 'Y', 'T']1.2 re.S(re.DOTALL)使'.'特殊字符与任何字符都匹配,包括换行符;没有此标志,'.'将匹配除换行符以外的任何内容。s = '''first line second line third line''' re.findall(r".+", s) # Return:['first line', 'second line', 'third line'] re.findall(r".+", s, flags=re.DOTALL) # Return:['first line\nsecond line\nthird line']2.常用方法2.1 re.match(pattern,string,flags = 0 )对字符串从开头进行正则匹配 (匹配零个或者一个对象)如果字符串与模式匹配,则返回相应的匹配对象。re.match('a','abcade') # Return:<re.Match object; span=(0, 1), match='a'> re.match('\w+','abc123de') # Return:<re.Match object; span=(0, 8), match='abc123de'>如果字符串与模式不匹配,则返回None;re.match('z','abcade') # Return:None可以使用group()获取匹配结果re.match('a','abcade').group() # Return:'a'2.2 re.search(pattern,string,flags = 0 )扫描字符串以查找正则表达式模式产生匹配项的第一个位置(匹配零个或者一个对象),与re.match的区别re.match是从字符串的开头进行匹配re.search是从对字符串的挨个位置都进行尝试,指导匹配上或者尝试完所有位置如果匹配上,则返回相应的match对象。re.search('b','abcade') # Return:<re.Match object; span=(1, 2), match='b'> re.search('b','abcade').group() # Return:'b'如果字符串中没有位置与模式匹配,则返回None;re.search('z','abcade') # Return:None2.3 re.compile(pattern,flags = 0 )该方法同re.match和re.search将正则表达式模式编译为正则表达式对象,可使用match(),search()以及下面所述的其他方法将其用于匹配reg = re.compile('\d{2}') # 正则对象-匹配两个数字 reg.search('12abc') # Return:<re.Match object; span=(0, 2), match='12'> reg.search('12abc').group() # Return:12reg = re.compile('\d{2}') # 正则对象-匹配两个数字 reg.match('123abc') # Return:<re.Match object; span=(0, 2), match='12'> reg.match('12abc').group() # Return:122.4 re.fullmatch(pattern,string,flags = 0 )如果整个字符串与正则表达式模式匹配,则返回相应的match对象。re.fullmatch('\w+','abcade') # Return:<re.Match object; span=(0, 6), match='abcade'> re.fullmatch('\w+','abcade').group() # Return:'abcade'否则返回None;re.fullmatch('\w+','abca de') # Return:None2.5 re.split(pattern,string,maxsplit = 0,flags = 0 )通过正则表达式来split字符串。re.split(r'\W+', 'Words, words, words.') # Return:['Words', 'words', 'words', '']如果在pattern中使用了捕获括号,那么模式中所有组的文本也将作为结果列表的一部分返回。re.split(r'(\W+)', 'Words, words, words.') # Return:['Words', ', ', 'words', ', ', 'words', '.', '']如果分隔符中有捕获组,并且该匹配组在字符串的开头匹配,则结果将从空字符串开始。字符串的末尾也是如此:re.split(r'(\W+)', '...words, words...') # Return:['', '...', 'words', ', ', 'words', '...', '']如果maxsplit不为零,则最多会发生maxsplit分割,并将字符串的其余部分作为列表的最后一个元素返回。re.split(r'\W+', 'Words, words, words.',1) # Return:['Words', 'words, words.']2.6 re.findall(pattern,string,flags = 0 )从左到右扫描该字符串,以列表的形式返回所有的匹配项re.findall('a', 'This is a beautiful place!') # Return:['a', 'a', 'a'] re.findall('z', 'This is a beautiful place!') # Return:[]2.7 re.sub(pattern,repl,string,count = 0,flags = 0 )使用repl替换掉string中pattern成功匹配的匹配项,count参数表示将匹配到的内容进行替换的次数re.sub('\d', 'S', 'abc12jh45li78') #将匹配到所有的数字替换成S # Return:'abcSSjhSSliSS' re.sub('\d', 'S', 'abc12jh45li78', 2) #将匹配到的数字替换成S,只替换2次就停止 # Return:'abcSSjh45li78'如果找不到该模式, 则返回的字符串不变。re.sub('z', 'S', 'abc12jh45li78') # Return:'abc12jh45li78'2.8 re.subn(pattern,repl,string,count = 0,flags = 0 )执行与相同的操作sub(),但返回一个元组。(new_string, number_of_subs_made)re.subn('\d', 'S', 'abc12jh45li78') # Return:('abcSSjhSSliSS', 6) re.subn('\d', 'S', 'abc12jh45li78', 3) # Return:('abcSSjhS5li78', 3)3. 其他补充3.1 使用正则表达式匹配中文 re.findall(r"[\u4e00-\u9fa5]", "沿charlie在charlie五前等待。charlie charlie五前等四川八八六四") # Return:['沿', '在', '五', '前', '等', '待', '五', '前', '等', '四', '川', '八', '八', '六', '四']3.2 贪心匹配和非贪心匹配贪心匹配:正则表达式在有二义的情况下,会尽可能匹配最长的字符串Python的正则表达式默认是”贪心“的,这表示在有二义的情况下,会尽可能匹配最长的字符串。re.search(r'(ha){3,5}','hahahahaha').group() # Return:'hahahahaha'非贪心匹配:匹配尽可能最短的字符串使用方式:在有二义的正则表达式的后面跟一个问号re.search(r'(ha){3,5}?','hahahahaha').group() # Return:'hahaha'参考资料使用正则表达式Python之re模块python 正则表达式详解 -
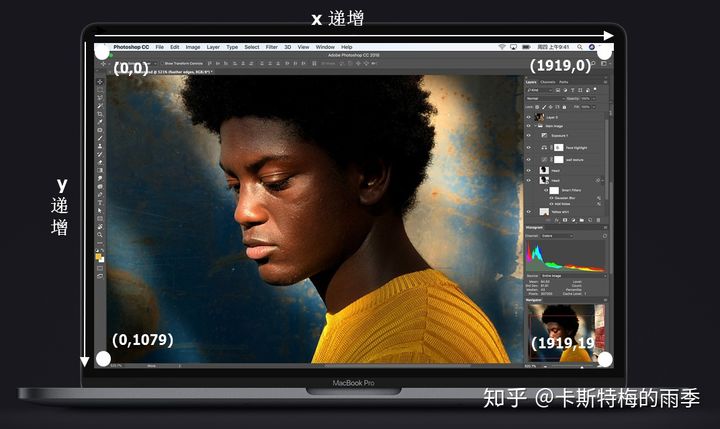
PyAutoGUI—通过python控制鼠标与键盘实现图形界面自动化 简介基本信息PyAutoGUI是一个Python语言的键鼠自动化库,简单来说和按键精灵的功能一样。但是因为是Python的类库,所以可以使用Python代码配合一些其他类库完成更加强大的功能坐标轴系统pyautogui的鼠标函数使用x,y坐标,原点在屏幕左上角,向右x坐标增加,向下y坐标增加,所有坐标都是正整数,没有负数坐标。如图所示:功能使用1.获取屏幕宽高pyautogui.size() #返回屏幕宽高像素数的元组 #例如,如果屏幕分辨率为1920*1080,那么左上角的坐标为(0,0), #右下角的坐标是(1919,1079)2.控制鼠标确定鼠标当前位置pyautogui.position() #确定鼠标当前位置,返回x,y坐标的元组移动pyautogui.moveTo(x,y[,duration = t]) # 将鼠标移动到屏幕指定位置, #x,y是目标位置的横纵坐标,duration指定鼠标光标移动到目标位置 #所需要的秒数,t可以为整数或浮点数,省略duration参数表示 #立即将光标移动到指定位置(在PyAutoGUI函数中,所有的duration #关键字参数都是可选的) #Attention:所有传入x,y坐标的地方,都可以用坐标x,y #的元组或列表替代,(x,y)/[x,y] pyautogui.moveRel(x,y[,duration = t]) #相对于当前位置移动光标, #这里的x,y不再是目标位置的坐标,而是偏移量, #如,pyautogui.moveRel(100,0,duration=0.25) #表示光标相对于当前所在位置向右移动100个像素点击:按下鼠标按键,然后放开,同时不移动位置pyautogui.mouseDown() #按下鼠标按键(左键) pyautogui.mouseUp() #释放鼠标按键(左键) pyautogui.click() #向计算机发送虚拟的鼠标点击(click()函数只是前面两个函数调用的方便封装) #默认在当前光标位置,使用鼠标左键点击 pyautogui.click([x,y,button='left/right/middle']) #在(x,y)处点击鼠标左键、右键、中键 #但不推荐使用这种方法,下面这种方法效果更好 #pyautogui.moveTo(x,y,duration=t) #pyautogui.click() pyautogui.doubleClick() #双击鼠标左键 pyautogui.rightClick() #单击鼠标右键 pyautogui.middleClick() #单击鼠标中键拖动:按住一个键不放,同时移动鼠标pyautogui.dragTo(x,y[,duration=t) #将鼠标拖动到指定位置 #x,y:x坐标,y坐标 pyautogui.dragRel(x,y[,duration=t]) #将鼠标拖动到相对当前位置的位置 #x,y:水平移动,垂直移动滚动pyautogui.scroll() #控制窗口上下滚动(滚动发生在鼠标的当前位置) #正数表示向上滚动,负数表示向下滚动, #滚动单位的大小需要具体尝试3.控制键盘输入字符串pyautogui.typewrite(s[,duration=t]) #向文本框发送字符串 #可选的duration参数在输入单个字符之间添加短暂的时间暂停 #Attention:只能用于输入英文输入键字符串不是所有的键都很容易用单个文本字符来表示。例如,如何把Shift键或左箭头键表示为单个字符串?在PyAutoGUI中,这些键表示为短的字符串值,如'esc'表示Esc键,'enter'表示Enter,我们把这些字符串称之为键字符串。pyautogui.typewrite([键盘键字符串]) #除了单个字符串,还可以向typewrite()函数传递键字符串的列表 #如 pyautogui.typewrite(['a','b','left','left','X','Y']) #按'a'键,'b'键,然后按左箭头两次,然后按'X'和'Y' #输出结果为XYab pyautogui.keyDown() #根据传入的键字符串,向计算机发送虚拟的按键(按下) pyautogui.keyUp() #根据传入的键字符串,向计算机发送虚拟的释放(释放) pyautogui.press() #前面两个函数的封装,模拟完整的击键(按下并释放)举例:pyautogui.keyDown('shift');pyautogui.press('4');pyautogui.keyUp('shift') #按下Shift,按下并释放4,然后释放Shift完整的键字符串如下:键盘键字符串 含义 'a','b','c','A','C','1','2','3', 单个字符的键 '!','@','#'等 'enter' 回车 ‘esc' ESC键 'shiftleft','shiftright' 左右Shift键 'altleft','altright' 左右Alt键 'ctrlleft','ctrlright' 左右Ctrl键 ‘tab'(or '\t') Tab键 'backspace','delete' Backspace键和Delete键 'pageup','pagedown' Page Up 和Page Down键 'home','end' Home键和End键 'up','down','left','right' 上下左右箭头键 'f1','f2','f3'等 F1至F12键 'volumemute','volumeup',volumedown' 静音,放大音量和减小音量键 'pause' 暂停键 'capslock','numlock','scrolllock' Caps Lock,Num Lock和 Scroll Lock键 'insert' Insert键 'printscreen' Prtsc或Print Screen键 'winleft','winright' 左右Win键(在windows上) 'command' Command键(在OS X上) 'option' Option键(在OS X上)快捷键组合pyautogui.hotkey() #接收多个字符串参数,顺序按下,再按相反的顺序释放举例:pyautogui.hotkey('ctrl','c') #按住Ctrl键,然后按C键,然后释放C键和Ctrl键 相当于 pyautogui.keyDown('ctrl') pyautogui.keyDown('c') pyautogui.keyUp('c') pyautogui.keyUp('ctrl')参考资料Python键鼠操作自动化库PyAutoGUI简介PyAutoGUI——图形用户界面自动化
-
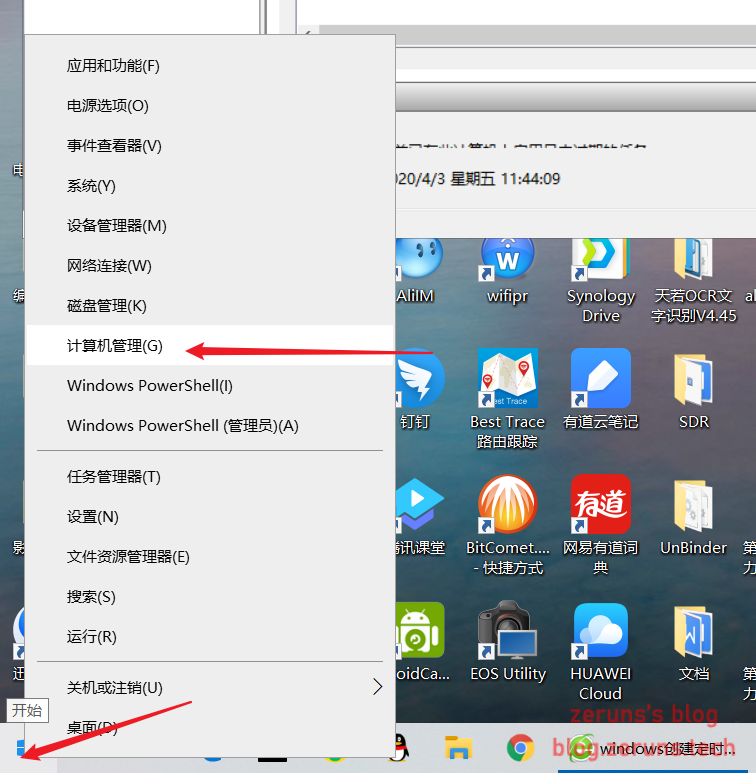
python实现阿里云域名ipv4和ipv6 ddns 1.前言首先得有一个阿里云的域名:https://www.aliyun.com/minisite/goods?userCode=jdjc69nf然后你的IP必须是公网IP,不然解析了也没用。本文章讲怎样通过阿里云的SDK来添加修改域名解析,检查本机IP与解析的IP是否一致,不一致自动修改解析,达到动态解析的目的,主要用于家庭宽带这些动态IP的地方。2.安装阿里云SDK和其他第三方库pip install aliyun-python-sdk-core-v3 pip install aliyun-python-sdk-domain pip install aliyun-python-sdk-alidns pip install requests3.获取accessKeyId和accessSecret可以在阿里云控制台个人中心直接获取,但是一般建议使用RAM角色来进行权限控制,这样这个accessKey和accessSecret就只能操作域名,不能操作其他的资源,相对会比较安全。关于RAM快速入门:https://help.aliyun.com/document_detail/28637.html?source=5176.11533457&userCode=jdjc69nf4.源码下载-官方4.1 下载地址gitee:https://gitee.com/zeruns/aliddns_Pythongithub:https://github.com/zeruns/-Python-aliddns_ipv4-ipv6将aliddns.py文件下载下来。然后用notepad++或其他编辑器打开,按照注释提示修改并保存。然后运行一下看看有没有问题:打开cmd输入python 脚本目录4.2源码备份from aliyunsdkcore.client import AcsClient from aliyunsdkcore.acs_exception.exceptions import ClientException from aliyunsdkcore.acs_exception.exceptions import ServerException from aliyunsdkalidns.request.v20150109.DescribeSubDomainRecordsRequest import DescribeSubDomainRecordsRequest from aliyunsdkalidns.request.v20150109.DescribeDomainRecordsRequest import DescribeDomainRecordsRequest import requests from urllib.request import urlopen import json ipv4_flag = 1 # 是否开启ipv4 ddns解析,1为开启,0为关闭 ipv6_flag = 1 # 是否开启ipv6 ddns解析,1为开启,0为关闭 accessKeyId = "accessKeyId" # 将accessKeyId改成自己的accessKeyId accessSecret = "accessSecret" # 将accessSecret改成自己的accessSecret domain = "4v7p.top" # 你的主域名 name_ipv4 = "ipv4.test" # 要进行ipv4 ddns解析的子域名 name_ipv6 = "ipv6.test" # 要进行ipv6 ddns解析的子域名 client = AcsClient(accessKeyId, accessSecret, 'cn-hangzhou') def update(RecordId, RR, Type, Value): # 修改域名解析记录 from aliyunsdkalidns.request.v20150109.UpdateDomainRecordRequest import UpdateDomainRecordRequest request = UpdateDomainRecordRequest() request.set_accept_format('json') request.set_RecordId(RecordId) request.set_RR(RR) request.set_Type(Type) request.set_Value(Value) response = client.do_action_with_exception(request) def add(DomainName, RR, Type, Value): # 添加新的域名解析记录 from aliyunsdkalidns.request.v20150109.AddDomainRecordRequest import AddDomainRecordRequest request = AddDomainRecordRequest() request.set_accept_format('json') request.set_DomainName(DomainName) request.set_RR(RR) # https://blog.zeruns.tech request.set_Type(Type) request.set_Value(Value) response = client.do_action_with_exception(request) if ipv4_flag == 1: request = DescribeSubDomainRecordsRequest() request.set_accept_format('json') request.set_DomainName(domain) request.set_SubDomain(name_ipv4 + '.' + domain) response = client.do_action_with_exception(request) # 获取域名解析记录列表 domain_list = json.loads(response) # 将返回的JSON数据转化为Python能识别的 ip = urlopen('https://api-ipv4.ip.sb/ip').read() # 使用IP.SB的接口获取ipv4地址 ipv4 = str(ip, encoding='utf-8') print("获取到IPv4地址:%s" % ipv4) if domain_list['TotalCount'] == 0: add(domain, name_ipv4, "A", ipv4) print("新建域名解析成功") elif domain_list['TotalCount'] == 1: if domain_list['DomainRecords']['Record'][0]['Value'].strip() != ipv4.strip(): update(domain_list['DomainRecords']['Record'][0]['RecordId'], name_ipv4, "A", ipv4) print("修改域名解析成功") else: # https://blog.zeruns.tech print("IPv4地址没变") elif domain_list['TotalCount'] > 1: from aliyunsdkalidns.request.v20150109.DeleteSubDomainRecordsRequest import DeleteSubDomainRecordsRequest request = DeleteSubDomainRecordsRequest() request.set_accept_format('json') request.set_DomainName(domain) # https://blog.zeruns.tech request.set_RR(name_ipv4) response = client.do_action_with_exception(request) add(domain, name_ipv4, "A", ipv4) print("修改域名解析成功") print("本程序版权属于zeruns,博客:https://blog.zeruns.tech") if ipv6_flag == 1: request = DescribeSubDomainRecordsRequest() request.set_accept_format('json') request.set_DomainName(domain) request.set_SubDomain(name_ipv6 + '.' + domain) response = client.do_action_with_exception(request) # 获取域名解析记录列表 domain_list = json.loads(response) # 将返回的JSON数据转化为Python能识别的 ip = urlopen('https://api-ipv6.ip.sb/ip').read() # 使用IP.SB的接口获取ipv6地址 ipv6 = str(ip, encoding='utf-8') print("获取到IPv6地址:%s" % ipv6) if domain_list['TotalCount'] == 0: add(domain, name_ipv6, "AAAA", ipv6) print("新建域名解析成功") elif domain_list['TotalCount'] == 1: if domain_list['DomainRecords']['Record'][0]['Value'].strip() != ipv6.strip(): update(domain_list['DomainRecords']['Record'][0]['RecordId'], name_ipv6, "AAAA", ipv6) print("修改域名解析成功") else: # https://blog.zeruns.tech print("IPv6地址没变") elif domain_list['TotalCount'] > 1: from aliyunsdkalidns.request.v20150109.DeleteSubDomainRecordsRequest import DeleteSubDomainRecordsRequest request = DeleteSubDomainRecordsRequest() request.set_accept_format('json') request.set_DomainName(domain) request.set_RR(name_ipv6) # https://blog.zeruns.tech response = client.do_action_with_exception(request) add(domain, name_ipv6, "AAAA", ipv6) print("修改域名解析成功")6.设置定时任务6.1 Linux操作使用crontab -e写入定时任务即可。例如:6.2 windows操作右键点击电脑左下角,再点击计算机管理点击任务计划程序,再点击创建任务,输入要设置的任务名称。新建触发器,执行间隔可以自己设置,持续时间改成无限期。新建操作,这一步很重要,配置错误就会导致脚本文件执行不成功!!!最后确认就行。参考资料Python实现阿里云域名DDNS支持ipv4和ipv6:https://developer.aliyun.com/article/755182
-
Python图片处理库PIL的使用 Python图片处理库PIL的使用1.加载图片、查看文件信息1.1加载图片。图片地址可以是相对路径,也可以是相对路径如果文件打开失败, 将抛出IOError异常。from PIL import Image img = Image.open(图片地址)1.2显示图片img.show()1.3查看图片属性format属性指定了图像文件的格式,如果图像不是从文件中加载的则为None。size属性是一个2个元素的元组,包含图像宽度和高度(像素)。mode属性定义了像素格式,常用的像素格式为:“L” (luminance) - 灰度图, “RGB” , “CMYK”。print(img.format, img.size, img.mode)JPEG (750, 300) RGB1.4 保存图片img.save("./save.jpg")2.使用滤镜2.0 使用方式from PIL import ImageFilter #滤镜所需要的包 img.filter(滤镜效果)常用滤镜有如下:滤镜名称含义ImageFilter.BLUR模糊滤镜ImageFilter.CONTOUR轮廓ImageFilter.EDGE_ENHANCE边界加强ImageFilter.EDGE_ENHANCE_MORE边界加强(阀值更大)ImageFilter.EMBOSS浮雕滤镜ImageFilter.FIND_EDGES边界滤镜ImageFilter.SMOOTH平滑滤镜ImageFilter.SMOOTH_MORE平滑滤镜(阀值更大)ImageFilter.SHARPEN锐化滤镜2.1滤镜效果图原图模糊-ImageFilter.BLUR轮廓(铅笔画)-ImageFilter.CONTOUR边界加强-ImageFilter.EDGE_ENHANCE边界加强(阀值更大)-ImageFilter.EDGE_ENHANCE_MORE浮雕-ImageFilter.EMBOSS边界-ImageFilter.FIND_EDGES(其实相当于背景涂黑,线条白色)平滑-ImageFilter.SMOOTH平滑(阀值更大)-ImageFilter.SMOOTH_MORE锐化-ImageFilter.SHARPEN2.2 自定义滤镜class SELF_FILTER(ImageFilter.BuiltinFilter): name = "SELF_FILTER" filterargs=(3,3),2,0,( -1,-1,-1, -1,9,-1, -1,-1,-1, ) result = img.filter(SELF_FILTER) result.show()3.图像局部切割# 导包 from PIL import Image # 加载图片 img = Image.open("./img.jpg") # 查看图片大小 print(img.size) #(750, 300) # 设置切割范围 (点1x,点1y,点2x,点2y) area = (170,80,580,240) # 切割图片 img_crop = img.crop(area) # 查看结果 img_crop.show()4.图像粘贴(叠加)# 导包 from PIL import Image # 准备图片 img = Image.open("./img.jpg") area = Image.open("./area.jpg") # 图片(粘贴)叠加 会直接改变原图,不产生新的图片 # 格式:图片1.paste(图片2,位置) 位置为左上角的(x,y) img.paste(area,(0,0)) # 查看效果 img.show()5.图像拼接--通过图像粘贴(叠加)实现# 导包 from PIL import Image # 准备图片 img1 = Image.open("./img.jpg") img2 = Image.open("./img.jpg") # 创建拼接结果的空白图:new(模式,大小,颜色) """ 模式:'RGB'/'RGBA' 大小:(width,height) 颜色:(R,G,B) """ empty = Image.new('RGB',(750,600),(255,255,255)) # 通过图像粘贴(叠加)实现图片拼接 empty.paste(img1,(0,0)) empty.paste(img2,(0,300)) # 查看效果 empty.show()结果6.图片缩放--会按比例缩放,不会拉伸# 导包 from PIL import Image # 准备图片 img = Image.open("./img.jpg") print(img.size) #(750, 300) # 缩放 -- 直接修改原图,不产生新图 new_size = (375,150) img.thumbnail(new_size) print(img.size) #(375, 150) # 查看效果 img.show()结果(750, 300) (375, 150)7.镜像翻转7.1 左右镜像# 导包 from PIL import Image # 准备图片 img = Image.open("./img.jpg") # 左右镜像 img_lr = img.transpose(Image.FLIP_LEFT_RIGHT) # 查看效果 img_lr原图:7.2 上下镜像# 导包 from PIL import Image # 准备图片 img = Image.open("./img.jpg") # 上下镜像 img_tb = img.transpose(Image.FLIP_TOP_BOTTOM) # 查看效果 img_tb镜像图8. 文字水印-把文字写到图上# 导包 from PIL import Image,ImageFont,ImageDraw # 准备图片 img = Image.open("./img.jpg") # 创建字体对象 # ImageFont.truetype(字体文件,字号) 笔 font = ImageFont.truetype('./BOD_B.TTF',60) # 创建draw对象 纸 draw = ImageDraw.Draw(img) # 文字渲染 # draw.text(坐标,文字内容,font = 字体对象,fill = 文字颜色) draw.text((0,0),"Hello World",font = font,fill = (255,0,0)) # 查看效果 img.show()结果9. 生成简单的数字验证码# 导包 from PIL import Image,ImageFont,ImageDraw import random # 创建空白图片 img = Image.new('RGB',(120,60),(255,255,255)) # 渲染背景 draw = ImageDraw.Draw(img) for i in range(0,120): for j in range(0,60): r = random.randint(60,255) g = random.randint(60,255) b = random.randint(60,255) draw.point((i,j),(r,g,b)) # 背景模糊 img = img.filter(ImageFilter.BLUR) # 渲染文字 draw = ImageDraw.Draw(img) font = ImageFont.truetype('./BOD_B.TTF',40) draw.text((20,10),"2345",font = font,fill = (0,0,0)) # 查看效果 img.show()参考资料python pil 第三方库实战之三:ImageFilter滤镜小试:https://blog.csdn.net/kanwenzhang/article/details/51936742PIL告诉你这么处理图片让你不再加班处理图片:https://www.bilibili.com/video/BV1yE411L7dR?p=11&spm_id_from=pageDriver
-
python下载m3u8视频 python下载m3u8视频单线程版import requests import os import re import threading # m3u8 url & vedio name m3u8_url = "https://www.hyxrzs.com/20201217/Jt4nKiPm/index.m3u8" base_url = "https://www.hyxrzs.com" vedio_name = "超人总动员" #创建用于合并的临时文件夹,用于存放ts文件 if not os.path.exists('merge'): os.system('mkdir merge') # 模拟浏览器header,防止误伤 headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36'} # 获取m3u8文件的内容 m3u8_content = requests.get(m3u8_url,headers=headers).text # 判断是否是最终的 is_final_m3u8 = not "m3u8" in m3u8_content # 当 m3u8 作为主播放列表(Master Playlist)时,其内部提供的是同一份媒体资源的多份流列表资源(Variant Stream) # 如果不是最终的m3u8,进入下一层找到最终的m3u8 (针对m3u8多分辨率适配的情况,会先有一个针对不同分辨率的m3u8索引文件) if not is_final_m3u8: # 解析出真正的m3u8_content for m3u8_url in m3u8_content.split('\n'): if "m3u8" in m3u8_url: m3u8_url = base_url +m3u8_url m3u8_content = requests.get(m3u8_url,headers=headers).text break m3u8_content_split_list = m3u8_content.split('\n') # 判断视频是否经过AES-128加密,如果加密过则获取加密方式和加密秘钥 key = '' for index,line in enumerate(m3u8_content_split_list): # 判断视频是否经过AES-128加密 if "#EXT-X-KEY" in line: #获取加密方式 method_pos = line.find("METHOD") comma_pos = line.find(",") method = line[method_pos:comma_pos].split('=')[1] print("该视频经过加密,加密方式为:", method) #获取加密密钥 uri_pos = line.find("URI") quotation_mark_pos = line.rfind('"') key_path = line[uri_pos:quotation_mark_pos].split('"')[1] key_url = m3u8_url.replace("index.m3u8",key_path) res = requests.get(key_url) key = res.content #从m3u8文件中解析出ts地址集 play_list = [] key = '' for index,line in enumerate(m3u8_content_split_list): #以下拼接方式可能会根据自己的需求进行改动 if '#EXTINF' in line: # 如果加密,直接提取每一级的.ts文件链接地址 if 'http' in m3u8_content_split_list[index + 1]: href = m3u8_content_split_list[index + 1] play_list.append(href) # 如果没有加密,直接构造出url链接 elif('ad0.ts' not in m3u8_content_split_list[index + 1]): href = base_url + m3u8_content_split_list[index+1] play_list.append(href) print("m3u8文件解析成功,共解析到",len(play_list),"个ts文件") # 封装下载当个ts文件的函数 def down_ts(index,ts_url,cryptor = False): # 获取ts content if not cryptor: ts_content = requests.get(ts_url,headers=headers).content else: ts_content = cryptor.decrypt(requests.get(ts_url,headers=headers).content)#获取bing解密ts # 写入文件 with open('merge/' + str(index+1) + '.ts','wb') as file: file.write(ts_content) print('第{}/{}个ts文件下载完成'.format(index+1,len(play_list))) # 根据ts地址集下载ts文件 print("开始下载所有的ts文件") if(len(key)):# 如果加密过 from Crypto.Cipher import AES cryptor = AES.new(key, AES.MODE_CBC, key) for index,ts_url in enumerate(play_list): down_ts(index,ts_url,cryptor) else: # 如果未加密 for index,ts_url in enumerate(play_list): down_ts(index,ts_url) print('所有ts文件都已下载完成') # 合并ts文件为mp4 并删除下载的ts文件 merge_cmd = "cat " for i in range(len(os.listdir("./merge"))): merge_cmd += "merge/"+ str(i+1) +".ts " merge_cmd += ">>vedio/"+vedio_name+".mp4" del_cmd = 'rm merge/*.ts' os.system(merge_cmd)#执行合并命令 os.system(del_cmd)#执行删除命令 print(vedio_name,'.mp4下载已完成')多线程版备注:目前该版本还存在问题(频繁下载被服务器断开连接),如过未下载完成则多次重复执行即可import requests import os import re import threading # m3u8 url & vedio name m3u8_url = "https://www.hyxrzs.com/20201217/Jt4nKiPm/index.m3u8" base_url = "https://www.hyxrzs.com" vedio_name = "超人总动员" #使用多线程技术 thread_list = [] max_connections = 2 # 定义最大线程数 pool_sema = threading.BoundedSemaphore(max_connections) # 或使用Semaphore方法 #创建用于合并的临时文件夹,用于存放ts文件 if not os.path.exists('merge'): os.system('mkdir merge') # 模拟浏览器header,防止误伤 headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36'} # 获取m3u8文件的内容 m3u8_content = requests.get(m3u8_url,headers=headers).text # 判断是否是最终的 is_final_m3u8 = not "m3u8" in m3u8_content # 当 m3u8 作为主播放列表(Master Playlist)时,其内部提供的是同一份媒体资源的多份流列表资源(Variant Stream) # 如果不是最终的m3u8,进入下一层找到最终的m3u8 (针对m3u8多分辨率适配的情况,会先有一个针对不同分辨率的m3u8索引文件) if not is_final_m3u8: # 解析出真正的m3u8_content for m3u8_url in m3u8_content.split('\n'): if "m3u8" in m3u8_url: m3u8_url = base_url +m3u8_url m3u8_content = requests.get(m3u8_url,headers=headers).text break m3u8_content_split_list = m3u8_content.split('\n') # 判断视频是否经过AES-128加密,如果加密过则获取加密方式和加密秘钥 key = '' for index,line in enumerate(m3u8_content_split_list): # 判断视频是否经过AES-128加密 if "#EXT-X-KEY" in line: #获取加密方式 method_pos = line.find("METHOD") comma_pos = line.find(",") method = line[method_pos:comma_pos].split('=')[1] print("该视频经过加密,加密方式为:", method) #获取加密密钥 uri_pos = line.find("URI") quotation_mark_pos = line.rfind('"') key_path = line[uri_pos:quotation_mark_pos].split('"')[1] key_url = m3u8_url.replace("index.m3u8",key_path) res = requests.get(key_url) key = res.content #从m3u8文件中解析出ts地址集 play_list = [] key = '' for index,line in enumerate(m3u8_content_split_list): #以下拼接方式可能会根据自己的需求进行改动 if '#EXTINF' in line: # 如果加密,直接提取每一级的.ts文件链接地址 if 'http' in m3u8_content_split_list[index + 1]: href = m3u8_content_split_list[index + 1] play_list.append(href) # 如果没有加密,直接构造出url链接 elif('ad0.ts' not in m3u8_content_split_list[index + 1]): href = base_url + m3u8_content_split_list[index+1] play_list.append(href) print("m3u8文件解析成功,共解析到",len(play_list),"个ts文件") print("上次下载完成了",len(os.listdir("./merge")),"个ts文件") # 封装下载当个ts文件的函数 def down_ts(index,ts_url,cryptor = False): # 获取ts content if not cryptor: ts_content = requests.get(ts_url,headers=headers).content else: ts_content = cryptor.decrypt(requests.get(ts_url,headers=headers).content)#获取bing解密ts # 写入文件 with open('merge/' + str(index+1) + '.ts','wb') as file: file.write(ts_content) print('第{}/{}个ts文件下载完成'.format(index+1,len(play_list))) # 根据ts地址集下载ts文件 print("开始下载所有的ts文件") if(len(key)):# 如果加密过 from Crypto.Cipher import AES cryptor = AES.new(key, AES.MODE_CBC, key) for index,ts_url in enumerate(play_list): if os.path.exists('merge/' + str(index+1) + '.ts'):continue #跳过已经存在的ts文件 thread_list.append(threading.Thread(target=down_ts, args=(index,ts_url,cryptor))) else: # 如果未加密 for index,ts_url in enumerate(play_list): if os.path.exists('merge/' + str(index+1) + '.ts'):continue #跳过已经存在的ts文件 thread_list.append(threading.Thread(target=down_ts, args=(index,ts_url))) for t in thread_list: t.start() for t in thread_list: t.join() # 子线程全部加入,主线程等所有子线程运行完毕 if len(os.listdir("./merge"))==len(play_list): print('所有ts文件都已下载完成') # 合并ts文件为mp4 并删除下载的ts文件 merge_cmd = "cat " for i in range(len(os.listdir("./merge"))): merge_cmd += "merge/"+ str(i+1) +".ts " merge_cmd += ">>vedio/"+vedio_name+".mp4" del_cmd = 'rm merge/*.ts' os.system(merge_cmd)#执行合并命令 os.system(del_cmd)#执行删除命令 print(vedio_name,'.mp4下载已完成') else: print("下载发生错误,请重新运行,下载完成度{}/{}".format(len(os.listdir("./merge")),len(play_list)))参考资料m3u8 文件格式详解:https://www.jianshu.com/p/e97f6555a070
-
python实现汉字转拼音 python实现汉字转拼音所用模块xpinyin模块安装pip install xpinyin使用方式from xpinyin import Pinyin p = Pinyin() pinyin = p.get_pinyin("上海") # shang-hai print(pinyin) # 显示声调1 pinyin = p.get_pinyin("上海", tone_marks=True) #shang4-hai3 print(pinyin) # 显示声调 pinyin = p.get_pinyin("上海", tone_marks='marks') #shàng-hǎi print(pinyin) # 设置分隔符 pinyin = p.get_pinyin("上海", ' ') # 'shang hai' print(pinyin) # 只显示声母 pinyin = p.get_initial("上") # 'S' print(pinyin) # 显示多字声母,并设置分隔符 p.get_initials("上海", '') #'SH' print(pinyin)shang-hai shang4-hai3 shàng-hǎi shang hai S S
-
[www.cc148.com]小说爬虫 [www.cc148.com]小说爬虫from bs4 import BeautifulSoup from urllib.request import urlopen from progressbar import * #根据目录页面地址获取目录页面的html、并封装为soup catalogue_url = "https://www.cc148.com/19_19568/" html = urlopen(catalogue_url).read().decode('gbk') soup = BeautifulSoup(html, features='lxml') #根据目录页html获取到小说的titile title = soup.title.text.split("最新章节列表")[0] #根据目录页html获取到小说每一章的地址集合chapter_url_list chapter_url_list = [] for dd in soup.find_all('dd'): chapter_url = catalogue_url + dd.a["href"] chapter_url_list.append(chapter_url) # 加入进度条功能 widgets = ['正在下载--'+title,Percentage(), ' ', Bar('#'),' ', Timer(),' ', ETA()] pbar = ProgressBar(widgets=widgets, maxval=len(chapter_url_list)).start() count = 0 #根据chapter_url_list逐章下载并保存到当前文件夹 txt_file_name = title + ".txt" with open(txt_file_name,'w') as f: for chapter_url in chapter_url_list: chapter_html = urlopen(chapter_url).read().decode('gbk') chapter_soup = BeautifulSoup(chapter_html, features='lxml') chapter_title = chapter_soup.title.text.split('_')[0] chapter_content = chapter_soup.find("div",{"id":"content"}).text chapter_text = chapter_title + "\n" + chapter_content + "\n" f.write(chapter_text) count +=1 pbar.update(count) pbar.finish()
-
Python中xml、字典、EasyDict、json格式相互转换(包含json格式化和xml格式化) Python中xml、字典、EasyDict、json格式相互转换(包含json格式化和xml格式化)依赖包jsonxmltodictxml转字典import xmltodict xmlstr =""" <student> <stid>10213</stid> <info> <name>name</name> <sex>male</sex> </info> <course> <name>math</name> <score>90</score> </course> </student> """ #parse是的xml解析器 dict_ = xmltodict.parse(xmlstr) print(dict_)OrderedDict([('student', OrderedDict([('stid', '10213'), ('info', OrderedDict([('name', 'name'), ('sex', 'male')])), ('course', OrderedDict([('name', 'math'), ('score', '90')]))]))])字典转EasyDictimport xmltodict xmlstr =""" <student> <stid>10213</stid> <info> <name>name</name> <sex>male</sex> </info> <course> <name>math</name> <score>90</score> </course> </student> """ #parse是的xml解析器 dict_ = xmltodict.parse(xmlstr) #转EasyDict from easydict import EasyDict dict_ = EasyDict(dict_) print(dict_){'student': {'stid': '10213', 'info': {'name': 'name', 'sex': 'male'}, 'course': {'name': 'math', 'score': '90'}}}字典转json最简版import json dict_ = { 'name': 'Jack', 'age': 22, 'skills': ['Python', 'Java', 'C++', 'Matlab'], 'major': '计算机技术', 'english': '英语六级', 'school': 'WIT' } #json库dumps()是将dict转化成json格式,loads()是将json转化成dict格式。 #dumps()方法的ident=1,格式化json jsonstr = json.dumps(dict_) print(jsonstr){"name": "Jack", "age": 22, "skills": ["Python", "Java", "C++", "Matlab"], "major": "\u8ba1\u7b97\u673a\u6280\u672f", "english": "\u82f1\u8bed\u516d\u7ea7", "school": "WIT"}很明显中文字符被转化了,于是使用:ensure_ascii=Falseimport json dict_ = { 'name': 'Jack', 'age': 22, 'skills': ['Python', 'Java', 'C++', 'Matlab'], 'major': '计算机技术', 'english': '英语六级', 'school': 'WIT' } #json库dumps()是将dict转化成json格式,loads()是将json转化成dict格式。 #dumps()方法的ident=1,格式化json jsonstr = json.dumps(dict_,ensure_ascii=False) print(jsonstr){"name": "Jack", "age": 22, "skills": ["Python", "Java", "C++", "Matlab"], "major": "计算机技术", "english": "英语六级", "school": "WIT"}加入行缩进import json dict_ = { 'name': 'Jack', 'age': 22, 'skills': ['Python', 'Java', 'C++', 'Matlab'], 'major': '计算机技术', 'english': '英语六级', 'school': 'WIT' } #json库dumps()是将dict转化成json格式,loads()是将json转化成dict格式。 #dumps()方法的ident=1,格式化json jsonstr = json.dumps(dict_,indent=2) #indent=2 表示行缩进=2 print(jsonstr){ "name": "Jack", "age": 22, "skills": [ "Python", "Java", "C++", "Matlab" ], "major": "\u8ba1\u7b97\u673a\u6280\u672f", "english": "\u82f1\u8bed\u516d\u7ea7", "school": "WIT" }很明显中文字符被转化了,于是使用:ensure_ascii=Falseimport json dict_ = { 'name': 'Jack', 'age': 22, 'skills': ['Python', 'Java', 'C++', 'Matlab'], 'major': '计算机技术', 'english': '英语六级', 'school': 'WIT' } #json库dumps()是将dict转化成json格式,loads()是将json转化成dict格式。 #dumps()方法的ident=1,格式化json jsonstr = json.dumps(dict_,indent=2,ensure_ascii=False) #indent=2 表示行缩进=2 print(jsonstr){ "name": "Jack", "age": 22, "skills": [ "Python", "Java", "C++", "Matlab" ], "major": "计算机技术", "english": "英语六级", "school": "WIT" }json转字典json.loads(json串),将json字符串转化成字典import json jsonstr = """ { "name": "Jack", "age": 22, "skills": [ "Python", "Java", "C++", "Matlab" ], "major": "计算机技术", "english": "英语六级", "school": "WIT" } """ dict_ = json.loads(jsonstr) print(dict_){'name': 'Jack', 'age': 22, 'skills': ['Python', 'Java', 'C++', 'Matlab'], 'major': '计算机技术', 'english': '英语六级', 'school': 'WIT'}字典转xmlimport xmltodict dict_ = {'student': {'course': {'name': 'math', 'score': '90'}, 'info': {'sex': 'male', 'name': 'name'}, 'stid': '10213'}} xmlstr = xmltodict.unparse(dict_) print(xmlstr)<?xml version="1.0" encoding="utf-8"?> <student><course><name>math</name><score>90</score></course><info><sex>male</sex><name>name</name></info><stid>10213</stid></student>XML格式化(美化)import xmltodict dict_ = {'student': {'course': {'name': 'math', 'score': '90'}, 'info': {'sex': 'male', 'name': 'name'}, 'stid': '10213'}} xmlstr = xmltodict.unparse(dict_) from xml.dom import minidom xml = minidom.parseString(xmlstr) xml_pretty_str = xml.toprettyxml() print(xml_pretty_str)<?xml version="1.0" encoding="utf-8"?> <student> <course> <name>math</name> <score>90</score> </course> <info> <sex>male</sex> <name>name</name> </info> <stid>10213</stid> </student>参考资料Python中xml和json格式相互转换操作示例:https://www.jb51.net/article/152118.htmPython json读写方式和字典相互转化:https://www.jb51.net/article/184983.htmPython如何优雅的格式化XML 【Python XML Format】: https://blog.csdn.net/qq_41958123/article/details/105357692
-
progressbar:python进度条功能 1.安装progressbar安装:pip install progressbar2.使用2.1 用法一import time from progressbar import * total = 1000 def dosomework(): time.sleep(0.01) progress = ProgressBar() for i in progress(range(1000)): dosomework()用法一显示效果5% |### | 100% |#########################################################################|2.2 用法二import time from progressbar import * total = 1000 def dosomework(): time.sleep(0.01) pbar = ProgressBar().start() for i in range(1000): pbar.update(int((i / (total - 1)) * 100)) dosomework() pbar.finish()用法二显示效果5% |### | 100% |#########################################################################|2.3 用法三import time from progressbar import * total = 1000 def dosomework(): time.sleep(0.01) widgets = ['Progress: ',Percentage(), ' ', Bar('#'),' ', Timer(),' ', ETA(), ' ', FileTransferSpeed()] pbar = ProgressBar(widgets=widgets, maxval=10*total).start() for i in range(total): # do something pbar.update(10 * i + 1) dosomework() pbar.finish()widgets可选参数含义:Progress: ' :设置进度条前显示的文字Percentage() :显示百分比Bar('#') : 设置进度条形状Timer() :显示已用时间ETA() : 显示预计剩余时间用法三显示效果Progress: 100% |#############| Elapsed Time: 0:00:10 Time: 0:00:10 981.79 B/s
-
Python中将dataframe转换为字典 Python中将dataframe转换为字典有时候,在Python中需要将dataframe类型转换为字典类型,下面的方法帮助我们解决这一问题。构造dataframeimport pandas as pd a = ['Name', 'Age', 'Gender'] b = ['Ali', '19', 'China'] data = pd.DataFrame(zip(a, b), columns=['project', 'attribute']) print datadataframe转换为字典dict_country = data.set_index('project').T.to_dict('list') print dict_country结果 project attribute 0 Name Ali 1 Age 19 2 Gender China {'Gender': ['China'], 'Age': ['19'], 'Name': ['Ali']}注意事项转置之前需要设置指定的索引,否则会按照默认索引转换成这样:{0: ['Name', 'Ali'], 1: ['Age', '19'], 2: ['Gender', 'China']}参考资料Python中将dataframe转换为字典:https://blog.csdn.net/yuanxiang01/article/details/79634632
-
Python中的三目运算符 Python中的三目运算符语法格式Python语言不像Java、JavaScript等这些语言有类似: 判段的条件?条件为真时的结果:条件为假时的结果这样的三目运算,但是Python也有自己的三目运算符: 条件为真时的结果 if 判段的条件 else 条件为假时的结果举例例一:编写一个Python程序,输入两个数,比较它们的大小并输出其中较大者。x = int(input("please enter first integer:")) y = int(input("please enter second integer:")) #一般的写法 if (x == y): print("两数相同!") elif(x > y): print("较大的数为:",x) else: print("较大的数为:",y) # 三目运算符写法 print(x if(x>y) else y)
-
Python将字典中的键值对反转方法 Python将字典中的键值对反转方法应用背景(问题示例)src:{'1': 0, '10': 1, '100': 2, '11': 3, '12': 4, '13': 5, '14': 6, '15': 7, '16': 8, '17': 9, '18': 10, '19': 11, '2': 12, '20': 13, '21': 14, '22': 15, '23': 16, '24': 17, '25': 18, '26': 19, '27': 20, '28': 21, '29': 22, '3': 23, '30': 24, '31': 25, '32': 26, '33': 27, '34': 28, '35': 29, '36': 30, '37': 31, '38': 32, '39': 33, '4': 34, '40': 35, '41': 36, '42': 37, '43': 38, '44': 39, '45': 40, '46': 41, '47': 42, '48': 43, '49': 44, '5': 45, '50': 46, '51': 47, '52': 48, '53': 49, '54': 50, '55': 51, '56': 52, '57': 53, '58': 54, '59': 55, '6': 56, '60': 57, '61': 58, '62': 59, '63': 60, '64': 61, '65': 62, '66': 63, '67': 64, '68': 65, '69': 66, '7': 67, '70': 68, '71': 69, '72': 70, '73': 71, '74': 72, '75': 73, '76': 74, '77': 75, '78': 76, '79': 77, '8': 78, '80': 79, '81': 80, '82': 81, '83': 82, '84': 83, '85': 84, '86': 85, '87': 86, '88': 87, '89': 88, '9': 89, '90': 90, '91': 91, '92': 92, '93': 93, '94': 94, '95': 95, '96': 96, '97': 97, '98': 98, '99': 99}dst:{0: '1', 1: '10', 2: '100', 3: '11', 4: '12', 5: '13', 6: '14', 7: '15', 8: '16', 9: '17', 10: '18', 11: '19', 12: '2', 13: '20', 14: '21', 15: '22', 16: '23', 17: '24', 18: '25', 19: '26', 20: '27', 21: '28', 22: '29', 23: '3', 24: '30', 25: '31', 26: '32', 27: '33', 28: '34', 29: '35', 30: '36', 31: '37', 32: '38', 33: '39', 34: '4', 35: '40', 36: '41', 37: '42', 38: '43', 39: '44', 40: '45', 41: '46', 42: '47', 43: '48', 44: '49', 45: '5', 46: '50', 47: '51', 48: '52', 49: '53', 50: '54', 51: '55', 52: '56', 53: '57', 54: '58', 55: '59', 56: '6', 57: '60', 58: '61', 59: '62', 60: '63', 61: '64', 62: '65', 63: '66', 64: '67', 65: '68', 66: '69', 67: '7', 68: '70', 69: '71', 70: '72', 71: '73', 72: '74', 73: '75', 74: '76', 75: '77', 76: '78', 77: '79', 78: '8', 79: '80', 80: '81', 81: '82', 82: '83', 83: '84', 84: '85', 85: '86', 86: '87', 87: '88', 88: '89', 89: '9', 90: '90', 91: '91', 92: '92', 93: '93', 94: '94', 95: '95', 96: '96', 97: '97', 98: '98', 99: '99'}具体方法第一种:dict={"a":1,"b":2,"c":3} inverse_dic={} for key,val in dict.items(): inverse_dic[val]=key第二种(推荐):dict_list={"a":1,"b":2,"c":3} inverse_dict=dict([val,key] for key,val in dict_list.items())第三种:dict_list={"a":1,"b":2,"c":3} mydict_new=dict(zip(dict_list.values(),dict_list.keys())参考资料Python将字典中的键值对反转方法:https://blog.csdn.net/ityti/article/details/85098699
-
Python3实现局域网存活主机扫描(多线程) Python3实现局域网存活主机扫描import os import time import platform import threading def get_os(): ''''' get os 类型 ''' os = platform.system() if os == "Windows": return "n" else: return "c" def ping_ip(ip_str): cmd = ["ping", "-{op}".format(op=get_os()), "1", ip_str] output = os.popen(" ".join(cmd)).readlines() flag = False for line in list(output): if not line: continue if str(line).upper().find("TTL") >=0: flag = True break if flag: print("ip: %s is ok ***"%ip_str) def find_ip(ip_prefix): ''''' 给出当前的127.0.0 ,然后扫描整个段所有地址 ''' for i in range(1,256): ip = '%s.%s'%(ip_prefix,i) t = threading.Thread(target=ping_ip, args=(ip,)) # 注意传入的参数一定是一个元组! t.start() if __name__ == "__main__": print("start time %s"%time.ctime()) ip_prefix = "10.1.130" find_ip(ip_prefix) print("end time %s"%time.ctime())
-
被窝网电视剧爬虫 被窝网电视剧爬虫#抓取电视剧 from bs4 import BeautifulSoup from urllib.request import urlopen import urllib import re import requests import os from tqdm import tqdm def download_from_url(url, dst): """ @param: url to download file @param: dst place to put the file :return: bool """ # 获取文件长度 try: file_size = int(urlopen(url).info().get('Content-Length', -1)) except Exception as e: print(e) print("错误,访问url: %s 异常" % url) return False # 判断本地文件存在时 if os.path.exists(dst): # 获取文件大小 first_byte = os.path.getsize(dst) else: # 初始大小为0 first_byte = 0 # 判断大小一致,表示本地文件存在 if first_byte >= file_size: print("文件已经存在,无需下载") return file_size header = {"Range": "bytes=%s-%s" % (first_byte, file_size)} pbar = tqdm( total=file_size, initial=first_byte, unit='B', unit_scale=True, desc=url.split('/')[-1]) # 访问url进行下载 req = requests.get(url, headers=header, stream=True) try: with(open(dst, 'ab')) as f: for chunk in req.iter_content(chunk_size=1024): if chunk: f.write(chunk) pbar.update(1024) except Exception as e: print(e) return False pbar.close() return True #网站根地址 web_base_url="http://10.1.48.113/" vedio_episodes_page_url_list=[ "http://10.1.48.113/shipin/dianshijuji/2018-09-29/193.php", "http://10.1.48.113/shipin/dianshijuji/2018-10-26/242.php", "http://10.1.48.113/shipin/dianshijuji/2018-10-26/239.php", "http://10.1.48.113/shipin/dianshijuji/2018-10-26/240.php", "http://10.1.48.113/shipin/dianshijuji/2018-10-26/238.php", "http://10.1.48.113/shipin/dianshijuji/2018-09-22/157.php" ] for vedio_episodes_page_url in vedio_episodes_page_url_list: #逐部电视剧解析 try: vedio_episodes_page_html = urlopen(vedio_episodes_page_url).read().decode('utf-8') vedio_episodes_page_soup = BeautifulSoup(vedio_episodes_page_html, features='lxml') #解析出电视剧名和设置保存文件夹 vedio_name=vedio_episodes_page_soup.head.find_all("meta")[2]["content"].replace(" ","") vedio_save_dir="./"+vedio_name if not os.path.exists(vedio_save_dir): os.mkdir(vedio_save_dir) #解析出单集播放页面地址 vedio_episode_href_list=vedio_episodes_page_soup.find_all('a', {"class": "meihua_btn"}) print("[开始下载]:"+vedio_name+"---"+vedio_episodes_page_url) #逐集解析 count=0 for vedio_episode_href in vedio_episode_href_list: vedio_episode_url = web_base_url + vedio_episode_href["href"] vedio_episode_html = urlopen(vedio_episode_url).read().decode('utf-8') vedio_episode_soup = BeautifulSoup(vedio_episode_html, features='lxml') count=count+1 vedio_episode_title = "第"+str(count)+"集" vedio_episode_save_path=vedio_save_dir+"/"+vedio_episode_title+".mp4" episode_url = web_base_url + re.findall("video:'(.*?)'",vedio_episode_html)[0] #逐集下载 print("[开始下载]:"+vedio_name+"---"+vedio_episode_title+"---"+episode_url) download_from_url(episode_url,vedio_episode_save_path) print("[下载完成]:"+vedio_name+"---"+vedio_episode_title) except Exception as e: print(e) print("错误,解析url: %s 异常" % vedio_episodes_page_url)
-
Python使用类似JavaScript的对象——EasyDict(更强大的Dict) Python使用类似JavaScript的对象——EasyDict(更强大的Dict)简介用惯 JavaScript 的人上来用 Python 的字典 dict 会很困惑,为什么只能用[]取属性而不能用.呢?JavaScriptvar data = { 'class1': { 'a': {'Chinese': 80}, '小明': {'Chinese': 90}, } }; console.log(data); console.log(data.class1, data['class1']); console.log(data.class1.a, data['class1']['a']); console.log(data.class1.a.Chinese, data['class1']['a']['Chinese']); console.log(data.class1['小明'].Chinese); // 混着用Python 会报错 AttributeError: 'dict' object has no attribute 'xxx'data = { 'class1': { 'a': {'Chinese': 80}, '小明': {'Chinese': 90}, } } print(data) print(data.class1, data['class1']) print(data.class1.a, data['class1']['a']) print(data.class1.a.Chinese, data['class1']['a']['Chinese']) print(data.class1['小明'].Chinese) # 混着用安装pip install easydictPS:可以不安装直接使用源码,仅30行,见文末初试from easydict import EasyDict data = { 'class1': { 'a': {'Chinese': 80}, '小明': {'Chinese': 90}, } } data = EasyDict(data) print(data) print(data.class1, data['class1']) print(data.class1.a, data['class1']['a']) print(data.class1.a.Chinese, data['class1']['a']['Chinese']) print(data.class1['小明'].Chinese) # 混着用 # {'class1': {'a': {'Chinese': 80}, '小明': {'Chinese': 90}}} # {'a': {'Chinese': 80}, '小明': {'Chinese': 90}} {'a': {'Chinese': 80}, '小明': {'Chinese': 90}} # {'Chinese': 80} {'Chinese': 80} # 80 80 # 90 1234567891011121314151617181920 EasyDict` 本质上还是 `Dict from easydict import EasyDict data = EasyDict(log=False) data.debug = True print(data.items()) # dict_items([('log', False), ('debug', True)])EasyDict 源码class EasyDict(dict): def __init__(self, d=None, **kwargs): if d is None: d = {} if kwargs: d.update(**kwargs) for k, v in d.items(): setattr(self, k, v) for k in self.__class__.__dict__.keys(): if not (k.startswith('__') and k.endswith('__')) and not k in ('update', 'pop'): setattr(self, k, getattr(self, k)) def __setattr__(self, name, value): if isinstance(value, (list, tuple)): value = [self.__class__(x) if isinstance(x, dict) else x for x in value] elif isinstance(value, dict) and not isinstance(value, self.__class__): value = self.__class__(value) super(EasyDict, self).__setattr__(name, value) super(EasyDict, self).__setitem__(name, value) __setitem__ = __setattr__ def update(self, e=None, **f): d = e or dict() d.update(f) for k in d: setattr(self, k, d[k]) def pop(self, k, d=None): delattr(self, k) return super(EasyDict, self).pop(k, d)




![[www.cc148.com]小说爬虫](https://blog.inat.top/usr/themes/Joe/assets/thumb/3.jpg)