搜索到
1
篇与
的结果
-
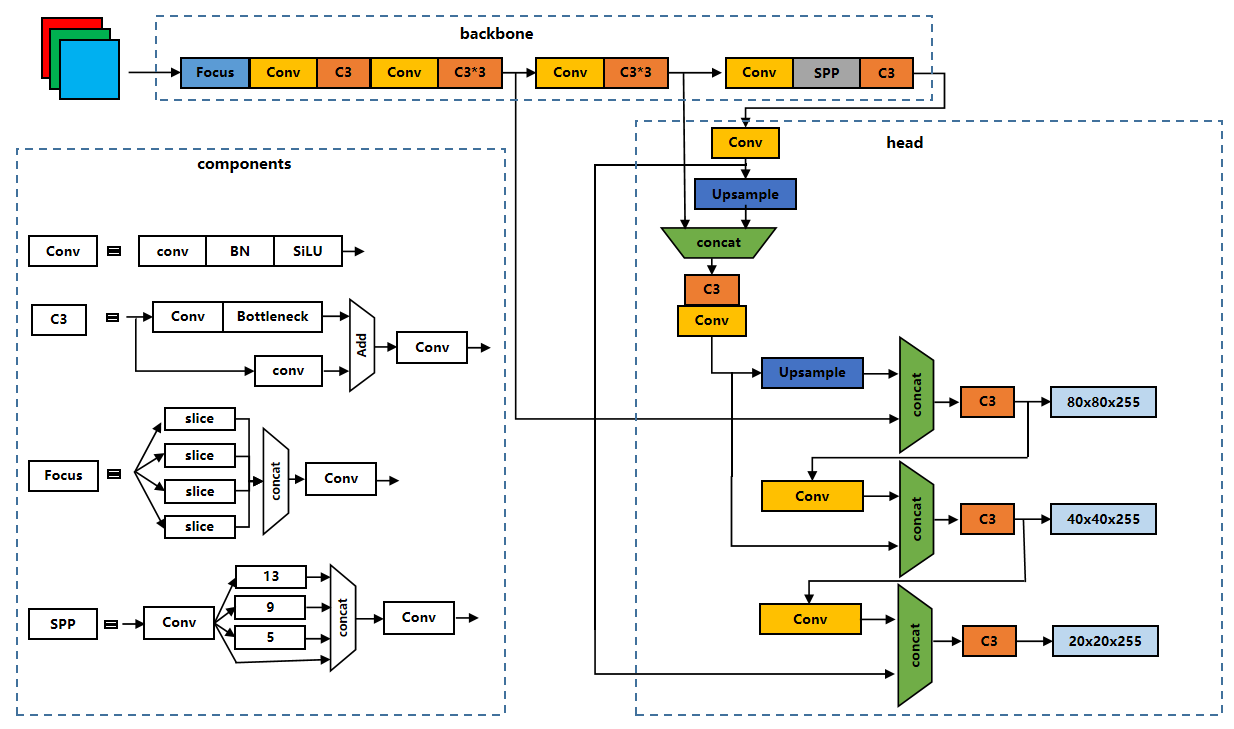
 Yolov5s:Yolov5sv6.0网络结构分析与实现 1.参考网络结构图(v5.0的)2. 配置文件解析原始配置文件yolov5s.yaml# YOLOv5 by Ultralytics, GPL-3.0 license # Parameters nc: 80 # number of classes depth_multiple: 0.33 # model depth multiple width_multiple: 0.50 # layer channel multiple anchors: - [10,13, 16,30, 33,23] # P3/8 - [30,61, 62,45, 59,119] # P4/16 - [116,90, 156,198, 373,326] # P5/32 # YOLOv5 v6.0 backbone backbone: # [from, number, module, args] [[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2 [-1, 1, Conv, [128, 3, 2]], # 1-P2/4 [-1, 3, C3, [128]], [-1, 1, Conv, [256, 3, 2]], # 3-P3/8 [-1, 6, C3, [256]], [-1, 1, Conv, [512, 3, 2]], # 5-P4/16 [-1, 9, C3, [512]], [-1, 1, Conv, [1024, 3, 2]], # 7-P5/32 [-1, 3, C3, [1024]], [-1, 1, SPPF, [1024, 5]], # 9 ] # YOLOv5 v6.0 head head: [[-1, 1, Conv, [512, 1, 1]], [-1, 1, nn.Upsample, [None, 2, 'nearest']], [[-1, 6], 1, Concat, [1]], # cat backbone P4 [-1, 3, C3, [512, False]], # 13 [-1, 1, Conv, [256, 1, 1]], [-1, 1, nn.Upsample, [None, 2, 'nearest']], [[-1, 4], 1, Concat, [1]], # cat backbone P3 [-1, 3, C3, [256, False]], # 17 (P3/8-small) [-1, 1, Conv, [256, 3, 2]], [[-1, 14], 1, Concat, [1]], # cat head P4 [-1, 3, C3, [512, False]], # 20 (P4/16-medium) [-1, 1, Conv, [512, 3, 2]], [[-1, 10], 1, Concat, [1]], # cat head P5 [-1, 3, C3, [1024, False]], # 23 (P5/32-large) [[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5) ]配置文件解析Model( (model): Sequential( (0): Conv(3,32,6,2,2) # 3x640x640-->32x320x320 (1): Conv(32,64,3,2) # 32x320x320-->64x160x160 (2): C3(64,64) # 64x160x160-->64x160x160 (3): Conv(64,128,3,2) # 64x160x160-->128x80x80 #P3 (4): C3(128,128) # 128x80x80-->128x80x80 (5): Conv(128,256,3,2) # 128x80x80-->256x40x40 #P4 (6): C3(256,256) # 256x40x40-->256x40x40 (7): Conv(256,512,3,2) # 256x40x40-->512x20x20 #P5 (8): SPP(512,512,[5, 9, 13]) # 512x20x20-->512x20x20 (9): C3(512,512) # 512x20x20-->512x20x20 #P6 (10): Conv(512,256,1,1) # 512x20x20-->256x20x20 (11): nn.Upsample(None, 2, 'nearest') # 256x20x20-->256x40x40 (12): Concat() # [x,p4]==>512x40x40 (13): C3(512,256) # 512x40x40-->256x40x40 (14): Conv(256,128) # 256x40x40-->128x40x40 (15): nn.Upsample(None, 2, 'nearest') # 128x40x40-->128x80x80 (16): Concat() # [x,p3]==>256x80x80 (17): C3(256,128) # 256x80x80-->128x80x80 #out1 (18): Conv(128,128,3,2) # 128x80x80-->128x40x40 (19): Concat() # [x,p4]==>384x40x40 (20): C3(384,256) # 384x40x40-->256x40x40 #out2 (21): Conv(256,256,3,2) # 256x40x40-->256x20x20 (22): Concat() # [x,p5]==>768x20x20 (23): C3(768,512) # 768x20x20 -->512x20x20 #out3 (24): Detect( (0): Conv2d(128, 255) # 128x80x80-->((cls_num+4+1)*anchor_num)x80x80 #out1_detect==>[3, 80, 80, 85] (1): Conv2d(256, 255) # 256x40x40-->((cls_num+4+1)*anchor_num)x40x40 #out2_detect==>[3, 40, 40, 85] (2): Conv2d(512, 255) # 512x20x20-->((cls_num+4+1)*anchor_num)x20x20 #out3_detect==>[3, 20, 20, 85] ) ) )3.代码实现3.1 公共基本块import torch import torch.nn as nn import warnings class Conv(nn.Module): # 标准卷积 def __init__(self, c1, c2, k=1, s=1, p=None, g=1, act=True): # ch_in, ch_out, kernel, stride, padding, groups super().__init__() self.conv = nn.Conv2d(c1, c2, k, s, autopad(k, p), groups=g, bias=False) self.bn = nn.BatchNorm2d(c2) self.act = nn.SiLU() if act is True else (act if isinstance(act, nn.Module) else nn.Identity()) def forward(self, x): return self.act(self.bn(self.conv(x))) def forward_fuse(self, x): return self.act(self.conv(x)) def forward_fuse(self, x): return self.act(self.conv(x)) class Bottleneck(nn.Module): # 标准bottleneck def __init__(self, c1, c2, shortcut=True, g=1, e=0.5): # ch_in, ch_out, shortcut, groups, expansion super().__init__() c_ = int(c2 * e) # hidden channels self.cv1 = Conv(c1, c_, 1, 1) self.cv2 = Conv(c_, c2, 3, 1, g=g) self.add = shortcut and c1 == c2 def forward(self, x): return x + self.cv2(self.cv1(x)) if self.add else self.cv2(self.cv1(x)) class C3(nn.Module): # CSP Bottleneck with 3 convolutions def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5): # ch_in, ch_out, number, shortcut, groups, expansion super().__init__() c_ = int(c2 * e) # hidden channels self.cv1 = Conv(c1, c_, 1, 1) self.cv2 = Conv(c1, c_, 1, 1) self.cv3 = Conv(2 * c_, c2, 1) # act=FReLU(c2) self.m = nn.Sequential(*[Bottleneck(c_, c_, shortcut, g, e=1.0) for _ in range(n)]) # self.m = nn.Sequential(*[CrossConv(c_, c_, 3, 1, g, 1.0, shortcut) for _ in range(n)]) def forward(self, x): return self.cv3(torch.cat((self.m(self.cv1(x)), self.cv2(x)), dim=1)) class SPPF(nn.Module): # Spatial Pyramid Pooling - Fast (SPPF) layer for YOLOv5 by Glenn Jocher def __init__(self, c1, c2, k=5): # equivalent to SPP(k=(5, 9, 13)) super().__init__() c_ = c1 // 2 # hidden channels self.cv1 = Conv(c1, c_, 1, 1) self.cv2 = Conv(c_ * 4, c2, 1, 1) self.m = nn.MaxPool2d(kernel_size=k, stride=1, padding=k // 2) def forward(self, x): x = self.cv1(x) with warnings.catch_warnings(): warnings.simplefilter('ignore') # suppress torch 1.9.0 max_pool2d() warning y1 = self.m(x) y2 = self.m(y1) return self.cv2(torch.cat([x, y1, y2, self.m(y2)], 1)) class Concat(nn.Module): # 沿维度连接张量列表 def __init__(self, dimension=1): super().__init__() self.d = dimension def forward(self, x): return torch.cat(x, self.d) def autopad(k, p=None): # kernel, padding # 计算然卷积结果与输入具有相同大小的padding if p is None: p = k // 2 if isinstance(k, int) else [x // 2 for x in k] # auto-pad return p3.2 backboneclass Yolov5sV6Backbone(nn.Module): def __init__(self): super(Yolov5sV6Backbone,self).__init__() self.backbone_part1 = nn.Sequential( Conv(3,32,6,2,2), # 0 Conv(32,64,3,2), # 1 C3(64,64), #2 Conv(64,128,3,2) #3 ) self.backbone_part2 = nn.Sequential( C3(128,128), # 4_1 Conv(128,256,3,2) # 5 ) self.backbone_part3 = nn.Sequential( C3(256,256), # 6 Conv(256,512,3,2) # 7 ) self.backbone_part4 = nn.Sequential( C3(512,512), # 8 SPPF(512,512,5), # 9 ) def forward(self,x): p3 = self.backbone_part1(x) p4 = self.backbone_part2(p3) p5 = self.backbone_part3(p4) p6 = self.backbone_part4(p5) return p3,p4,p5,p6调用测试backbone = Yolov5sV6Backbone() fake_input = torch.rand(1,3,640,640) p3,p4,p5,p6 = backbone(fake_input) print(p3.shape,p4.shape,p5.shape,p6.shape)torch.Size([1, 128, 80, 80]) torch.Size([1, 256, 40, 40]) torch.Size([1, 512, 20, 20]) torch.Size([1, 512, 20, 20])3.3 headclass Yolov5sV6Head(nn.Module): def __init__(self): super(Yolov5sV6Head,self).__init__() self.head_part1 = nn.Sequential( Conv(512,256,1,1), # 10 nn.Upsample(None, 2, 'nearest') # 11 ) self.head_concat1 =Concat() # 12 self.head_part2 = nn.Sequential( C3(512,256), # 13 Conv(256,128), # 14 nn.Upsample(None, 2, 'nearest') # 15 ) self.head_concat2 = Concat() # 16 self.head_out1 = C3(256,128) # 17 # 128x80x80 self.head_part3 = Conv(128,128,3,2) # 18 self.head_concat3 = Concat() # 19 self.head_out2 = C3(384,256) # 20 self.head_part4 = Conv(256,256,3,2) # 21 self.head_concat4 = Concat() # 22 self.head_out3 = C3(768,512) # 23 # 512x40x40 def forward(self,p3,p4,p5,x): x = self.head_part1(x) x = self.head_concat1([x,p4]) x = self.head_part2(x) x = self.head_concat2([x,p3]) out1 = self.head_out1(x) x = self.head_part3(out1) x = self.head_concat3([x,p4]) out2 = self.head_out2(x) x = self.head_part4(out2) x = self.head_concat4([x,p5]) out3 = self.head_out3(x) return out1,out2,out3调用测试backbone = Yolov5sV6Backbone() head = Yolov5sV6Head() fake_input = torch.rand(1,3,640,640) p3,p4,p5,p6 = backbone(fake_input) out1,out2,out3 = head(p3,p4,p5,p6) print(out1.shape,out2.shape,out3.shape)3.4 detect 部分class Yolov5sV6Detect(nn.Module): stride = None # strides computed during build def __init__(self, nc=80, anchors=(), ch=[128,256,512], inplace=True): # detection layer super(Yolov5sV6Detect,self).__init__() self.nc = nc # number of classes self.no = nc + 5 # number of outputs per anchor self.nl = len(anchors) # number of detection layers self.na = len(anchors[0]) // 2 # number of anchors self.grid = [torch.zeros(1)] * self.nl # init grid self.anchor_grid = [torch.zeros(1)] * self.nl # init anchor grid self.register_buffer('anchors', torch.tensor(anchors).float().view(self.nl, -1, 2)) # shape(nl,na,2) self.m = nn.ModuleList(nn.Conv2d(x, self.no * self.na, 1) for x in ch) # output conv self.inplace = inplace # use in-place ops (e.g. slice assignment) def forward(self, x): z = [] # inference output for i in range(self.nl): x[i] = self.m[i](x[i]) # conv bs, _, ny, nx = x[i].shape # x(bs,255,20,20) to x(bs,3,20,20,85) x[i] = x[i].view(bs, self.na, self.no, ny, nx).permute(0, 1, 3, 4, 2).contiguous() if not self.training: # inference if self.grid[i].shape[2:4] != x[i].shape[2:4]: self.grid[i], self.anchor_grid[i] = self._make_grid(nx, ny, i) y = x[i].sigmoid() if self.inplace: y[..., 0:2] = (y[..., 0:2] * 2 - 0.5 + self.grid[i]) * self.stride[i] # xy y[..., 2:4] = (y[..., 2:4] * 2) ** 2 * self.anchor_grid[i] # wh else: # for YOLOv5 on AWS Inferentia https://github.com/ultralytics/yolov5/pull/2953 xy = (y[..., 0:2] * 2 - 0.5 + self.grid[i]) * self.stride[i] # xy wh = (y[..., 2:4] * 2) ** 2 * self.anchor_grid[i] # wh y = torch.cat((xy, wh, y[..., 4:]), -1) z.append(y.view(bs, -1, self.no)) return x if self.training else (torch.cat(z, 1), x) def _make_grid(self, nx=20, ny=20, i=0): d = self.anchors[i].device if check_version(torch.__version__, '1.10.0'): # torch>=1.10.0 meshgrid workaround for torch>=0.7 compatibility yv, xv = torch.meshgrid([torch.arange(ny, device=d), torch.arange(nx, device=d)], indexing='ij') else: yv, xv = torch.meshgrid([torch.arange(ny, device=d), torch.arange(nx, device=d)]) grid = torch.stack((xv, yv), 2).expand((1, self.na, ny, nx, 2)).float() anchor_grid = (self.anchors[i].clone() * self.stride[i]) \ .view((1, self.na, 1, 1, 2)).expand((1, self.na, ny, nx, 2)).float() return grid, anchor_grid调用测试anchors = [ [10,13, 16,30, 33,23], [30,61, 62,45, 59,119], [116,90, 156,198, 373,326] ] backbone = Yolov5sV6Backbone() head = Yolov5sV6Head() detect = Yolov5sV6Detect(nc=80,anchors=anchors) fake_input = torch.rand(1,3,640,640) p3,p4,p5,p6 = backbone(fake_input) out1,out2,out3 = head(p3,p4,p5,p6) out1,out2,out3 = detect([out1,out2,out3]) print(out1.shape,out2.shape,out3.shape)torch.Size([1, 3, 80, 80, 85]) torch.Size([1, 3, 40, 40, 85]) torch.Size([1, 3, 20, 20, 85])3.5 整体组装class Yolov5sV6(nn.Module): def __init__(self,nc=80,anchors=()): super(Yolov5sV6,self).__init__() self.backbone = Yolov5sV6Backbone() self.head = Yolov5sV6Head() self.detect = Yolov5sV6Detect(nc,anchors) def forward(self,x): p3,p4,p5,p6 = self.backbone(x) out1,out2,out3 = self.head(p3,p4,p5,p6) out1,out2,out3 = self.detect([out1,out2,out3]) return out1,out2,out3调用测试anchors = [ [10,13, 16,30, 33,23], [30,61, 62,45, 59,119], [116,90, 156,198, 373,326] ] yolov5s = Yolov5sV6(nc=80,anchors=anchors) fake_input = torch.rand(1,3,640,640) out1,out2,out3 = yolov5s(fake_input) print(out1.shape,out2.shape,out3.shape)torch.Size([1, 3, 80, 80, 85]) torch.Size([1, 3, 40, 40, 85]) torch.Size([1, 3, 20, 20, 85])4.模型复杂度分析模型名Input模型大小全精度模型大小半精度参数量FLOPSbackbone640x64026.0MB13.1MB3.80M4.42GFLOPShead640x64011.5MB5.78MB3.00M2.79GFLOPSdetect640x640897KB450KB0.23M0.37GFLOPSYolov5s640x64026.9M13.5M7.03M7.58GFLOPS参考资料https://github.com/ultralytics/yolov5YOLOv5代码详解(common.py部分)Yolov5从入门到放弃(一)---yolov5网络架构YOLOV5网络结构
Yolov5s:Yolov5sv6.0网络结构分析与实现 1.参考网络结构图(v5.0的)2. 配置文件解析原始配置文件yolov5s.yaml# YOLOv5 by Ultralytics, GPL-3.0 license # Parameters nc: 80 # number of classes depth_multiple: 0.33 # model depth multiple width_multiple: 0.50 # layer channel multiple anchors: - [10,13, 16,30, 33,23] # P3/8 - [30,61, 62,45, 59,119] # P4/16 - [116,90, 156,198, 373,326] # P5/32 # YOLOv5 v6.0 backbone backbone: # [from, number, module, args] [[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2 [-1, 1, Conv, [128, 3, 2]], # 1-P2/4 [-1, 3, C3, [128]], [-1, 1, Conv, [256, 3, 2]], # 3-P3/8 [-1, 6, C3, [256]], [-1, 1, Conv, [512, 3, 2]], # 5-P4/16 [-1, 9, C3, [512]], [-1, 1, Conv, [1024, 3, 2]], # 7-P5/32 [-1, 3, C3, [1024]], [-1, 1, SPPF, [1024, 5]], # 9 ] # YOLOv5 v6.0 head head: [[-1, 1, Conv, [512, 1, 1]], [-1, 1, nn.Upsample, [None, 2, 'nearest']], [[-1, 6], 1, Concat, [1]], # cat backbone P4 [-1, 3, C3, [512, False]], # 13 [-1, 1, Conv, [256, 1, 1]], [-1, 1, nn.Upsample, [None, 2, 'nearest']], [[-1, 4], 1, Concat, [1]], # cat backbone P3 [-1, 3, C3, [256, False]], # 17 (P3/8-small) [-1, 1, Conv, [256, 3, 2]], [[-1, 14], 1, Concat, [1]], # cat head P4 [-1, 3, C3, [512, False]], # 20 (P4/16-medium) [-1, 1, Conv, [512, 3, 2]], [[-1, 10], 1, Concat, [1]], # cat head P5 [-1, 3, C3, [1024, False]], # 23 (P5/32-large) [[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5) ]配置文件解析Model( (model): Sequential( (0): Conv(3,32,6,2,2) # 3x640x640-->32x320x320 (1): Conv(32,64,3,2) # 32x320x320-->64x160x160 (2): C3(64,64) # 64x160x160-->64x160x160 (3): Conv(64,128,3,2) # 64x160x160-->128x80x80 #P3 (4): C3(128,128) # 128x80x80-->128x80x80 (5): Conv(128,256,3,2) # 128x80x80-->256x40x40 #P4 (6): C3(256,256) # 256x40x40-->256x40x40 (7): Conv(256,512,3,2) # 256x40x40-->512x20x20 #P5 (8): SPP(512,512,[5, 9, 13]) # 512x20x20-->512x20x20 (9): C3(512,512) # 512x20x20-->512x20x20 #P6 (10): Conv(512,256,1,1) # 512x20x20-->256x20x20 (11): nn.Upsample(None, 2, 'nearest') # 256x20x20-->256x40x40 (12): Concat() # [x,p4]==>512x40x40 (13): C3(512,256) # 512x40x40-->256x40x40 (14): Conv(256,128) # 256x40x40-->128x40x40 (15): nn.Upsample(None, 2, 'nearest') # 128x40x40-->128x80x80 (16): Concat() # [x,p3]==>256x80x80 (17): C3(256,128) # 256x80x80-->128x80x80 #out1 (18): Conv(128,128,3,2) # 128x80x80-->128x40x40 (19): Concat() # [x,p4]==>384x40x40 (20): C3(384,256) # 384x40x40-->256x40x40 #out2 (21): Conv(256,256,3,2) # 256x40x40-->256x20x20 (22): Concat() # [x,p5]==>768x20x20 (23): C3(768,512) # 768x20x20 -->512x20x20 #out3 (24): Detect( (0): Conv2d(128, 255) # 128x80x80-->((cls_num+4+1)*anchor_num)x80x80 #out1_detect==>[3, 80, 80, 85] (1): Conv2d(256, 255) # 256x40x40-->((cls_num+4+1)*anchor_num)x40x40 #out2_detect==>[3, 40, 40, 85] (2): Conv2d(512, 255) # 512x20x20-->((cls_num+4+1)*anchor_num)x20x20 #out3_detect==>[3, 20, 20, 85] ) ) )3.代码实现3.1 公共基本块import torch import torch.nn as nn import warnings class Conv(nn.Module): # 标准卷积 def __init__(self, c1, c2, k=1, s=1, p=None, g=1, act=True): # ch_in, ch_out, kernel, stride, padding, groups super().__init__() self.conv = nn.Conv2d(c1, c2, k, s, autopad(k, p), groups=g, bias=False) self.bn = nn.BatchNorm2d(c2) self.act = nn.SiLU() if act is True else (act if isinstance(act, nn.Module) else nn.Identity()) def forward(self, x): return self.act(self.bn(self.conv(x))) def forward_fuse(self, x): return self.act(self.conv(x)) def forward_fuse(self, x): return self.act(self.conv(x)) class Bottleneck(nn.Module): # 标准bottleneck def __init__(self, c1, c2, shortcut=True, g=1, e=0.5): # ch_in, ch_out, shortcut, groups, expansion super().__init__() c_ = int(c2 * e) # hidden channels self.cv1 = Conv(c1, c_, 1, 1) self.cv2 = Conv(c_, c2, 3, 1, g=g) self.add = shortcut and c1 == c2 def forward(self, x): return x + self.cv2(self.cv1(x)) if self.add else self.cv2(self.cv1(x)) class C3(nn.Module): # CSP Bottleneck with 3 convolutions def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5): # ch_in, ch_out, number, shortcut, groups, expansion super().__init__() c_ = int(c2 * e) # hidden channels self.cv1 = Conv(c1, c_, 1, 1) self.cv2 = Conv(c1, c_, 1, 1) self.cv3 = Conv(2 * c_, c2, 1) # act=FReLU(c2) self.m = nn.Sequential(*[Bottleneck(c_, c_, shortcut, g, e=1.0) for _ in range(n)]) # self.m = nn.Sequential(*[CrossConv(c_, c_, 3, 1, g, 1.0, shortcut) for _ in range(n)]) def forward(self, x): return self.cv3(torch.cat((self.m(self.cv1(x)), self.cv2(x)), dim=1)) class SPPF(nn.Module): # Spatial Pyramid Pooling - Fast (SPPF) layer for YOLOv5 by Glenn Jocher def __init__(self, c1, c2, k=5): # equivalent to SPP(k=(5, 9, 13)) super().__init__() c_ = c1 // 2 # hidden channels self.cv1 = Conv(c1, c_, 1, 1) self.cv2 = Conv(c_ * 4, c2, 1, 1) self.m = nn.MaxPool2d(kernel_size=k, stride=1, padding=k // 2) def forward(self, x): x = self.cv1(x) with warnings.catch_warnings(): warnings.simplefilter('ignore') # suppress torch 1.9.0 max_pool2d() warning y1 = self.m(x) y2 = self.m(y1) return self.cv2(torch.cat([x, y1, y2, self.m(y2)], 1)) class Concat(nn.Module): # 沿维度连接张量列表 def __init__(self, dimension=1): super().__init__() self.d = dimension def forward(self, x): return torch.cat(x, self.d) def autopad(k, p=None): # kernel, padding # 计算然卷积结果与输入具有相同大小的padding if p is None: p = k // 2 if isinstance(k, int) else [x // 2 for x in k] # auto-pad return p3.2 backboneclass Yolov5sV6Backbone(nn.Module): def __init__(self): super(Yolov5sV6Backbone,self).__init__() self.backbone_part1 = nn.Sequential( Conv(3,32,6,2,2), # 0 Conv(32,64,3,2), # 1 C3(64,64), #2 Conv(64,128,3,2) #3 ) self.backbone_part2 = nn.Sequential( C3(128,128), # 4_1 Conv(128,256,3,2) # 5 ) self.backbone_part3 = nn.Sequential( C3(256,256), # 6 Conv(256,512,3,2) # 7 ) self.backbone_part4 = nn.Sequential( C3(512,512), # 8 SPPF(512,512,5), # 9 ) def forward(self,x): p3 = self.backbone_part1(x) p4 = self.backbone_part2(p3) p5 = self.backbone_part3(p4) p6 = self.backbone_part4(p5) return p3,p4,p5,p6调用测试backbone = Yolov5sV6Backbone() fake_input = torch.rand(1,3,640,640) p3,p4,p5,p6 = backbone(fake_input) print(p3.shape,p4.shape,p5.shape,p6.shape)torch.Size([1, 128, 80, 80]) torch.Size([1, 256, 40, 40]) torch.Size([1, 512, 20, 20]) torch.Size([1, 512, 20, 20])3.3 headclass Yolov5sV6Head(nn.Module): def __init__(self): super(Yolov5sV6Head,self).__init__() self.head_part1 = nn.Sequential( Conv(512,256,1,1), # 10 nn.Upsample(None, 2, 'nearest') # 11 ) self.head_concat1 =Concat() # 12 self.head_part2 = nn.Sequential( C3(512,256), # 13 Conv(256,128), # 14 nn.Upsample(None, 2, 'nearest') # 15 ) self.head_concat2 = Concat() # 16 self.head_out1 = C3(256,128) # 17 # 128x80x80 self.head_part3 = Conv(128,128,3,2) # 18 self.head_concat3 = Concat() # 19 self.head_out2 = C3(384,256) # 20 self.head_part4 = Conv(256,256,3,2) # 21 self.head_concat4 = Concat() # 22 self.head_out3 = C3(768,512) # 23 # 512x40x40 def forward(self,p3,p4,p5,x): x = self.head_part1(x) x = self.head_concat1([x,p4]) x = self.head_part2(x) x = self.head_concat2([x,p3]) out1 = self.head_out1(x) x = self.head_part3(out1) x = self.head_concat3([x,p4]) out2 = self.head_out2(x) x = self.head_part4(out2) x = self.head_concat4([x,p5]) out3 = self.head_out3(x) return out1,out2,out3调用测试backbone = Yolov5sV6Backbone() head = Yolov5sV6Head() fake_input = torch.rand(1,3,640,640) p3,p4,p5,p6 = backbone(fake_input) out1,out2,out3 = head(p3,p4,p5,p6) print(out1.shape,out2.shape,out3.shape)3.4 detect 部分class Yolov5sV6Detect(nn.Module): stride = None # strides computed during build def __init__(self, nc=80, anchors=(), ch=[128,256,512], inplace=True): # detection layer super(Yolov5sV6Detect,self).__init__() self.nc = nc # number of classes self.no = nc + 5 # number of outputs per anchor self.nl = len(anchors) # number of detection layers self.na = len(anchors[0]) // 2 # number of anchors self.grid = [torch.zeros(1)] * self.nl # init grid self.anchor_grid = [torch.zeros(1)] * self.nl # init anchor grid self.register_buffer('anchors', torch.tensor(anchors).float().view(self.nl, -1, 2)) # shape(nl,na,2) self.m = nn.ModuleList(nn.Conv2d(x, self.no * self.na, 1) for x in ch) # output conv self.inplace = inplace # use in-place ops (e.g. slice assignment) def forward(self, x): z = [] # inference output for i in range(self.nl): x[i] = self.m[i](x[i]) # conv bs, _, ny, nx = x[i].shape # x(bs,255,20,20) to x(bs,3,20,20,85) x[i] = x[i].view(bs, self.na, self.no, ny, nx).permute(0, 1, 3, 4, 2).contiguous() if not self.training: # inference if self.grid[i].shape[2:4] != x[i].shape[2:4]: self.grid[i], self.anchor_grid[i] = self._make_grid(nx, ny, i) y = x[i].sigmoid() if self.inplace: y[..., 0:2] = (y[..., 0:2] * 2 - 0.5 + self.grid[i]) * self.stride[i] # xy y[..., 2:4] = (y[..., 2:4] * 2) ** 2 * self.anchor_grid[i] # wh else: # for YOLOv5 on AWS Inferentia https://github.com/ultralytics/yolov5/pull/2953 xy = (y[..., 0:2] * 2 - 0.5 + self.grid[i]) * self.stride[i] # xy wh = (y[..., 2:4] * 2) ** 2 * self.anchor_grid[i] # wh y = torch.cat((xy, wh, y[..., 4:]), -1) z.append(y.view(bs, -1, self.no)) return x if self.training else (torch.cat(z, 1), x) def _make_grid(self, nx=20, ny=20, i=0): d = self.anchors[i].device if check_version(torch.__version__, '1.10.0'): # torch>=1.10.0 meshgrid workaround for torch>=0.7 compatibility yv, xv = torch.meshgrid([torch.arange(ny, device=d), torch.arange(nx, device=d)], indexing='ij') else: yv, xv = torch.meshgrid([torch.arange(ny, device=d), torch.arange(nx, device=d)]) grid = torch.stack((xv, yv), 2).expand((1, self.na, ny, nx, 2)).float() anchor_grid = (self.anchors[i].clone() * self.stride[i]) \ .view((1, self.na, 1, 1, 2)).expand((1, self.na, ny, nx, 2)).float() return grid, anchor_grid调用测试anchors = [ [10,13, 16,30, 33,23], [30,61, 62,45, 59,119], [116,90, 156,198, 373,326] ] backbone = Yolov5sV6Backbone() head = Yolov5sV6Head() detect = Yolov5sV6Detect(nc=80,anchors=anchors) fake_input = torch.rand(1,3,640,640) p3,p4,p5,p6 = backbone(fake_input) out1,out2,out3 = head(p3,p4,p5,p6) out1,out2,out3 = detect([out1,out2,out3]) print(out1.shape,out2.shape,out3.shape)torch.Size([1, 3, 80, 80, 85]) torch.Size([1, 3, 40, 40, 85]) torch.Size([1, 3, 20, 20, 85])3.5 整体组装class Yolov5sV6(nn.Module): def __init__(self,nc=80,anchors=()): super(Yolov5sV6,self).__init__() self.backbone = Yolov5sV6Backbone() self.head = Yolov5sV6Head() self.detect = Yolov5sV6Detect(nc,anchors) def forward(self,x): p3,p4,p5,p6 = self.backbone(x) out1,out2,out3 = self.head(p3,p4,p5,p6) out1,out2,out3 = self.detect([out1,out2,out3]) return out1,out2,out3调用测试anchors = [ [10,13, 16,30, 33,23], [30,61, 62,45, 59,119], [116,90, 156,198, 373,326] ] yolov5s = Yolov5sV6(nc=80,anchors=anchors) fake_input = torch.rand(1,3,640,640) out1,out2,out3 = yolov5s(fake_input) print(out1.shape,out2.shape,out3.shape)torch.Size([1, 3, 80, 80, 85]) torch.Size([1, 3, 40, 40, 85]) torch.Size([1, 3, 20, 20, 85])4.模型复杂度分析模型名Input模型大小全精度模型大小半精度参数量FLOPSbackbone640x64026.0MB13.1MB3.80M4.42GFLOPShead640x64011.5MB5.78MB3.00M2.79GFLOPSdetect640x640897KB450KB0.23M0.37GFLOPSYolov5s640x64026.9M13.5M7.03M7.58GFLOPS参考资料https://github.com/ultralytics/yolov5YOLOv5代码详解(common.py部分)Yolov5从入门到放弃(一)---yolov5网络架构YOLOV5网络结构